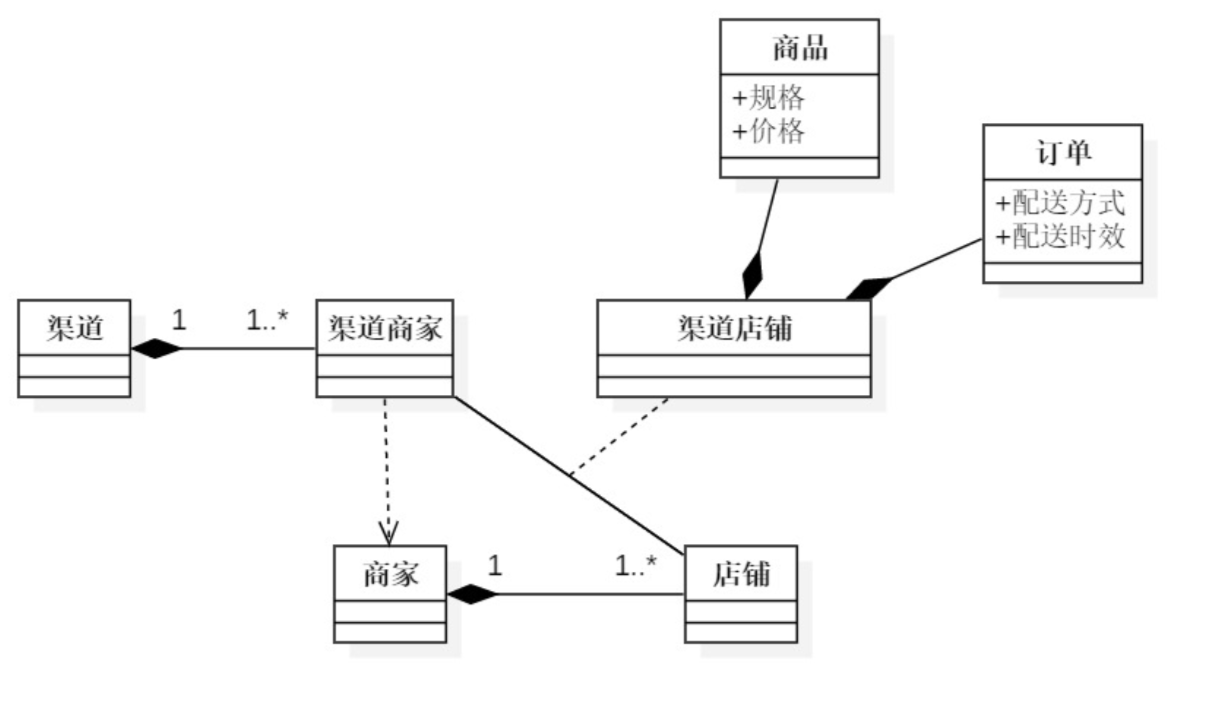
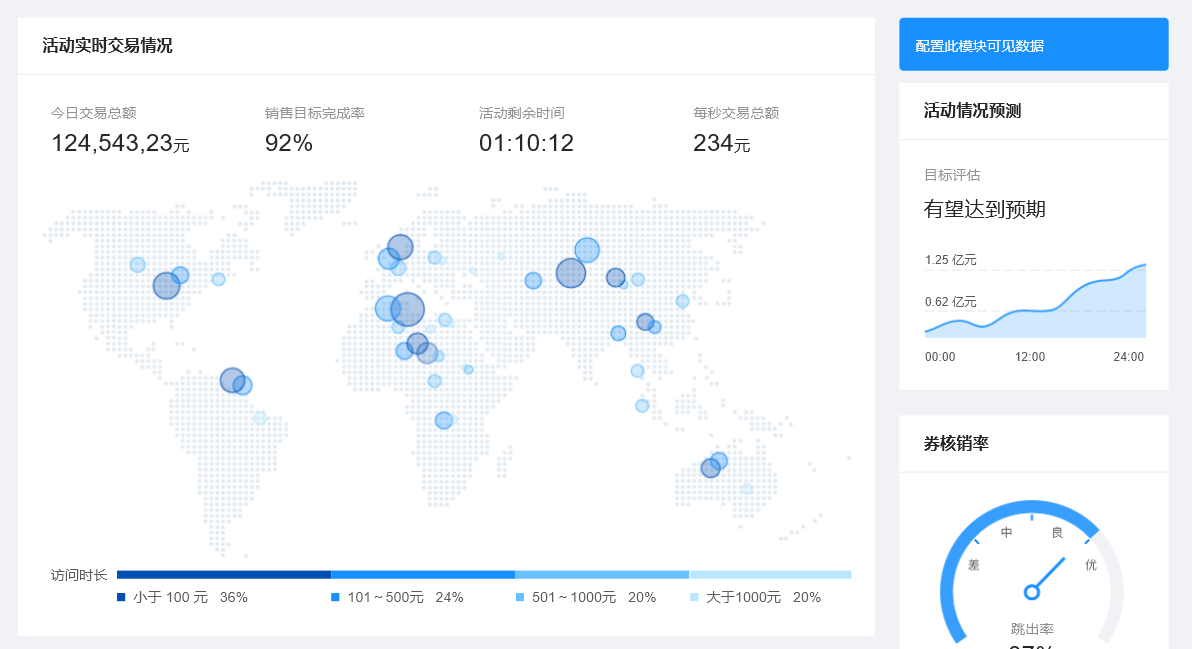
事情的来源是今早 9 点零三分,我还在梦里吃着澳龙,突然微信的震动把我震醒了。我一拿手机,原来是我的恩师胡晓波给我发来一条消息,让我试着能不能写一篇关于卡通 LOGO 的教程。当然我是一个很乐于分享的好人,所以有了今天的这篇分享。

准备好了吗?我要进去……哦不,我要开始了!
做好一个卡通 LOGO,有几个关键的点需要注意。如果这几点做不好,那么你做出来的卡通 LOGO 总觉得带着一股乡村气息,总做不出那味儿。下面拿这个案例演示的时候,我会一一提到。
首先先去网上找一些关于青蛙的素材,当然,你可以找照片,也可以找一些青蛙的卡通形象参考。然后在网上我看到了这张图,觉得非常有意思。虎躯一震,决定把这个拿来当动作参考。
在做卡通logo的时候,找照片素材最好是找姿态、动作比较有故事性、有意思、有特点的,这样出来的形象也比较生动。
接着,把这张照片垫底,试着草图一下它,把它的轮廓先用 AI 钢笔工具勾出来,这样就得到了一个初始的外轮廓。
再处理下这个外轮廓,得到这个初始的轮廓后,感觉这个形象完全可行,那么我们现在需要把它的线条变的更顺滑,整体的形象显得更可爱(既然是卡通,可爱一点会更好看)。
重点 2:
怎么能让一个形象变得 Q 萌可爱?长时间的研究卡通,我得出这么一个结论:形象偏矮胖、敦厚、圆润,就比较能突出可爱的特征,把你勾勒的初始轮廓适当压扁,让它变矮胖。
经过线条的优化(使其圆滑),外轮廓的压扁处理以后,就得到了最后的这个结果。
整体形象确定以后,再给青蛙画五官,这里,我们再去网上找一些青蛙的卡通形象的处理方式(或者不局限于找青蛙也可以找一些与青蛙形象相近的动物,例如蜥蜴等等)。

重点 3:
卡通的五官,处理方式其实很简单,尽量用几何图形去作为脸部的五官特征。
在这个案例上,因为主体是青蛙,所以不能单纯用一个小圆点去作为青蛙的眼睛,我们可以看到青蛙眼睛的特征,是有一个较大的眼白与较小点的眼珠。所以这边的处理方式,就是一个白色的大圆+黑色小圆。

单单这个形象还是不太够,虽然这个坐姿已经比较生动了,我们可以根据这个形象展开联想,让它更充满故事性和趣味性,这里观察青蛙的姿势,这个屁股的角度,可以让它坐在跟大自然有关的物体上,加上这个双手护胸的动作,让它叼一根树枝,更能体现悠闲的气质。

重点 4:
卡通吉祥物的标志,利用本身的的姿态动作,适当展开联想,加一些小物件可以让它更生动,更有趣。
接下来就是上色跟补充一些细节了。如果配色较差,可以去网上找一些配色的参考。这里我找到一个卡通的配色,刚好也是绿色为主,适合青蛙,且背景也可以参考它做一个叠底。
最后,选个自己觉得较为合适的字体,如果会做字体的话最好是自己做个字儿,再做个排版,就OK 啦~
重点 5:
卡通 LOGO 的排版,不要太复杂,因为卡通标志本身的图形具象,排版简单更好看,用字的字体气质要符合图形。
前面的案例,想必大家都已经 get 到了步骤,还我还是要再演示一下这个案例,嘻嘻。
还是一样的,这张照片是我偶然看到的,觉得非常有感觉就保存到手机了。在做这个 LOGO 前突然想到有这么一张图,立马开始操作。

其实大家在日常生活中看到比较有意思的图片,都可以保存下来,说不定哪天它就能变成一个好看的 LOGO 是不是呢?
好了不说废话,开始勾轮廓!
这张图的松鼠,看起来还是比较饱满的,所以在后期调整优化曲线的时候会比较轻松,但是这个图的外轮廓,相比第一个案例的青蛙,是比较复杂的,这里需要耐心一些。
这里绘制的外轮廓,线条都不是合并的,但是我们发现,这个 LOGO 是需要做一些高光跟阴影的,所以这里先给大家普及一个基础知识。
三种描边模式,我们选择第三种——使描边外侧对齐,因为我在给图形做剪切阴影或者是高光时,不可能 100% 沿着轮廓去勾勒,这样太累了,所以一般会超出外轮廓一些,再去做剪切,这样能省不少时间。
重点 6:
卡通 LOGO 的绘制,基本都是用到外轮廓,这样好做高光跟阴影的剪切。
回到主题,我们接着画这个松鼠。
刚刚我们已经把草图大概勾勒出来了,现在把这个草图垫底,让它形成一个合并的状态(注意先观察草图找好锚点的起点,否则很难让整个轮廓连起来),并且过程中、优化线条曲线(这一步还是有点难度的,钢笔工具不太熟的同学需要多练习)。
勾勒完成后的线条是图 1 这样的,不少同学会有疑问,为什么有些地方会呈现双线的状态?别急,把它换成外描边模式你就明白了。

因为外描边模式,当有两条相近的线条时,是有可能重叠的,这样就能形成一些细节线条。

接着,我们继续调整有些不完美的地方,比如重叠到的地方线条粗细不统一等等,调整完后我们看下效果。

到了这步以后,其实最难的点已经被你拿捏了,剩下的就是补一些细节。另外,松鼠的尾巴,这边是没有按照图片的线条去处理的,因为现在这个图形是往下走的趋势,如果尾巴还是往下垂,那整个图形的重心就不平衡了。
这边尾巴的处理也可以网上找一些参考,因为上面说的平衡问题,所以我把松鼠尾巴处理成往上走的趋势。
大体造型已经完成,现在剩下的就是填补五官、填充颜色,加高光阴影。
重点 7:
阴影跟高光这部分,其实不需要过于严谨。没有美术功底的同学也不用发愁,在一些有交错,遮挡的部位加阴影,在头顶或者身体外边缘加高光,基本是没有什么大问题的。
这样图形就完成了,最后加上排版就完成了。
第三个案例跟前两个其实很相似,都是我在网上看到比较有意思的照片,下载下来做成卡通标志。废话不多说,上图了。

其实我个人很喜欢做猴,当然大部分原因是因为我爱人叫……猴子, emmm好像离题了,收!
emmm好像离题了,收!
因为猴子本身是一种带着调皮、聪明、智慧性质的动物,做猴 LOGO 其实可以让它赋予多种性格。
如上两个案例的方法,先大概绘制一下猴子的外轮廓,看一下图形大概的感觉(这里还是与第一个案例说的,图形整体看起来比较瘦高,可爱气质会偏弱,我们可以尝试压扁)。压扁后我觉得是我想要的一个高度,但是压扁后头部也会变形,那么接下去只要我们把这个压扁后的猴子轮廓复制一个,再使用第一版绘制的头部就 OK 了(这里不做具体演示)。
重点 8:
卡通类型的 LOGO,一般身体都会比较短,头比较大,圆,这样可爱的气质才会突显。
经过一番调整操作后得到这样一个轮廓,但是现在这猴子是没有尾巴的,所以我们要给它添加一根又粗又长……的尾巴。
这样得到了一个最终的轮廓形态。接下来就是给它画上脸,五官,还有增加一些高光细节了。
这里看你想给猴子定义什么样的表情气质。原照片的这猴子,表情略带无辜,我觉得还蛮不错的。那么我们尝试一下画上表情,注意简化。

委屈、无辜的表情,如果你不知道怎么画才能表现出来,可以对着镜子装个委屈的表情看下,或者度娘一下委屈、无辜的照片。一般委屈无辜,眼睛的形状都是呈现一个眼角往下的状态。

加完五官以后,现在整个猴子的大致形象已经出来了,那现在这个姿势,需要加点什么才能让它变完整。原照片上,是两根分叉的树干,其实照着画也没什么不妥,那我们就给它画上树干,再上个色。
画完树干,上完色后,整个图形是不稳的。原因是分叉的树干其实是个 V 字形,所以我们为了让它稳住,在底部加一个类似阴影的形状去压住它就完全 OK了。

本以为到这,就完成了。端详许久,总觉得还差点啥,感觉这猴儿还不够灵性。这时候我突然想到我前几天买的毛线帽,然后想着,天冷了,给猴儿个帽子吧……

画完后,又看了许久,不禁发出感叹,我 TMD 真是个天才……最后老规矩,加排版,完事儿!
前面的都是根据一些照片去做的吉祥物卡通标志,其实创造性不属于特别高,我个人其实更喜欢是这类 MIX 标志,把两种不相关的物体结合起来,但却不违和,反而更显趣味创造性。
这个案例的灵感来源是我在 BE 上看到一个我很喜欢的设计师做的一个标志(下图) ,把老鼠与胡萝卜结合,非常有意思。

做这个 LOGO 之前,我就一直想做个胡萝卜的创意性标志(出于对波哥的爱 ),这类型的卡通 LOGO,有时候就是灵感一瞬间迸发的事儿。但是没灵感的时候,我都会去网上瞎看,有时候看着看着,就能想到做啥了。偶然间看到几张坦克的照片,灵鸡一动,把胡萝卜跟坦克结合,因为刚好坦克的炮管,可以用胡萝卜代替(想到这里,我露出了姨母笑)。
),这类型的卡通 LOGO,有时候就是灵感一瞬间迸发的事儿。但是没灵感的时候,我都会去网上瞎看,有时候看着看着,就能想到做啥了。偶然间看到几张坦克的照片,灵鸡一动,把胡萝卜跟坦克结合,因为刚好坦克的炮管,可以用胡萝卜代替(想到这里,我露出了姨母笑)。
那么胡萝卜跟坦克的造型怎么画呢?首先还是打开你的网页,可以先搜一下胡萝卜的造型,再搜坦克的图片(这里找到的坦克图片,已经是手绘图了,所以我们要把它概括简化一下)。
我先不用管胡萝卜的部分,因为胡萝卜的角度是要根据坦克轮子的角度来做,所以我们先把坦克的部分绘制一下。仔细观察坦克底座的构造,拆解绘制。

到这里大家可能会有点困惑,这样的图片我要怎么下手?不要急,其实不难。上面我们已经把坦克底座的部分拆解,现在只需要绘制一排车轮跟轮子上面的铁盖。这里需要注意的是,因为坦克的特征十分明显,就是一根长长的炮管与底部的一排轮子,所以只要把这两个特征能抓出来,基本不难看出是坦克了。

重点 9:
当你要把一个实物/动物图片转化成卡通风格时,要仔细观察它原来的线条,使其更几何化,去繁从简。
坦克部分处理完就可以搞这个胡萝卜了,这里就不用做太多演示了,胡萝卜这么好画!注意跟坦克合上的角度就 OK 了!

这个角度先画个草图,放上去试试合不合适。

可以!
再观察下胡萝卜的细节,因为它要充当炮管,所以我们不加上面的叶子,但是这样会不会看不出是胡萝卜?那我们可以观察下胡萝卜身体部分有什么细节,再加上胡萝卜的橙红色,说看不出我不信!
特征:胡萝卜身上的划痕
别急,现在看不出胡萝卜不要紧,上色以后一切都会好的~
好了,可以合体了!注意各个组件的图层关系。

上色!排版!完事儿!
这个案例跟上个案例其实非常相似,都是 MIX 系列的卡通 LOGO 这个 LOGO ,这个 LOGO 灵感来源于我偶然在网上看到了这张图片,以猕猴桃代替了鹦鹉的翅膀,配色也完全不违和,是非常优秀的作品了。

萌生了想长做一个类似的 LOGO,当然我们不能再用猕猴桃的元素了。想想,其实很多水果可以做这样的「代替品」。但是这里需要注意的是,什么样的水果切开,还非常具有特征,让人一眼就能辨识出来。最后我选了西瓜,西瓜可以有半圆,也可以有三角形,这样的话,鸟的翅膀形态发挥空间就很大了。切开后的西瓜籽加上红色的瓜瓤十分具有辨识度。

当然我们先要做的是「鸟」这个主体的造型。这边还是先去网上找一下鸟的图片,最终,我选用这张图片来作为这个 LOGO 的主体(因为它本身图片就有可爱的气质,更方便我们后面创作)。
这里我只提取了这只鸟的身体跟嘴的部分,翅膀我们要用西瓜代替的,所以暂时先不去绘制。确定好身体部分以后,我们再尝试先画切开的一半的西瓜。这里也不难,网上搜一下西瓜,很多素材可以参考着画。
画好的西瓜,我们再尝试旋转角度,跟鸟的身体部分合体一下。

看起来真可以啊!
现在的造型看起来是不是还不戳!是吧~但是还没完!一般展翅的鸟儿,爪子是什么状态?别慌,继续度娘!
可以看到,展翅后的鸟儿,爪子都是往前伸。我们秉着卡通能简化就简化的原则,把爪子处理成线的形式即可。加以上色,「西瓜鸟」就出来了。

图形这样已经是完成了,现在就剩下排版。当我加上文字以后,发现这个 LOGO 越看越显得空,那咋办?加个背景色块其实就解决了(这里的背景色块,也是根据鸟的身体走势做的椭圆)!
重点 10:
当你的卡通 LOGO 做完后发现整体看起来不饱满,尝试加个背景色块,屡试不爽。
总结Tips:
-
在做卡通 LOGO 的时候,找照片素材最好是找姿态,动作比较有故事性,有意思,有特点的,这样出来的形象也比较生动。
-
怎么能让一个形象变得 Q 萌可爱?形象偏矮胖、敦厚、圆润,就比较能突出可爱的特征,把你勾勒的初始轮廓适当压扁,让它变矮胖。
-
卡通的五官,处理方式其实很简单,尽量用几何图形去作为脸部的五官特征。
-
卡通吉祥物的标志,利用本身的的姿态动作,适当展开联想,加一些小物件可以让它更生动,更有趣。
-
卡通 LOGO 的排版,不要太复杂,因为卡通标志本身的图形具象,排版简单更好看,用字的字体气质要符合图形。
-
卡通 LOGO 的绘制,基本都是用到外轮廓,这样好做高光跟阴影的剪切。
-
阴影跟高光这部分,其实不需要过于严谨,在一些有交错,遮挡的部位加阴影,在头顶或者身体外边缘加高光,基本是没有什么大问题的。
-
卡通类型的 LOGO,一般身体都会比较短,头比较大,圆,这样可爱的气质才会突显。
-
当你要把一个实物/动物图片转化成卡通风格时,要仔细观察它原来的线条,使其更几何化,去繁从简。
-
当你的卡通 LOGO 做完后发现整体看起来不饱满,尝试加个背景色块,屡试不爽。
初试卡通,或许效果没有很好,但是都是能靠多看,多练,练会的。喜欢它,你就能静下心去做它,练它,兴趣是最好的老师。所以如果你也喜欢卡通类型的 LOGO,让我们干起来吧!
原文地址:胡晓波工作室(公众号)
作者:小章鱼
转载请注明:学UI网》五个案例教会你怎么做卡通 LOGO (一)
蓝蓝设计建立了UI设计分享群,每天会分享国内外的一些优秀设计,如果有兴趣的话,可以进入一起成长学习,请扫码蓝小助,报下信息,蓝小助会请您入群。欢迎您加入噢~~希望得到建议咨询、商务合作,也请与我们联系。

分享此文一切功德,皆悉回向给文章原作者及众读者.
免责声明:蓝蓝设计尊重原作者,文章的版权归原作者。如涉及版权问题,请及时与我们取得联系,我们立即更正或删除。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务