

前言:如何让你的设计更有价值,设计有价值代表你的方案有价值,你的方案有价值代表你的理论有价值、你的理论有价值代表你的专业能力体现,归根到底,说明了什么人作出什么样的作品的同时会带来相应的价值。站在设计师的角度看,在公司里,属于站在用户体验上的提出的设计建议或者设计方案,基于“以用户为中心”理念和交互设计原则,通过自己的设计思维与专业能力,为公司创造更大的价值,不单只是一个美观的输出。

目录:
一、设计行业的发展趋势
a)设计与产品的关系
b)找到自身价值的重要性
二、了解设计师的价值分层
a)设计协同
b)推动业务增长
c)设计驱动产品
三、设计师需要具备的哪些思维?
a)双钻模型解决问题
b)“五度”设计成果评估模型
c)培养数据思维,利用数据提升设计的价值
一、设计行业的发展趋势
a)设计与产品的关系
以前,设计师在团队里的位置会比较尴尬,因为没法验证自己对业务的推动是否产生了什么明确的价值。而大数据的来临,设计的价值变得显性化,作为与用户关系密切的设计师,善用好数据,可以发挥的作用其实很大。我们可以通过自己的设计思维与专业能力,为公司创造更大的价值,不单只是一个美观的输出。这就使得设计与产品业务关系越来越密切,是整个行业发展的必然趋势。
举一个设计以小成提高业务的实例。这是我之前做的分拣软件迭代首页的自定义配置组件。在改动前分拣首页功能多,甚至有时候需要滑动寻找。寻找点击率大概是不到16%,改动后提高到了40%,不消耗任何其他人力、物力成本,就可以用设计让CTR翻倍。
设计目标:减少首页模块寻找的时间,加大成功点击率,考虑延展性发展
现有问题:主次功能混淆、视觉点不够集中、点击按钮不明显
优化方案:1、主次布局调整,主上次下;2、面积放大提高模块命中率;3、色彩区分主次按钮;4、添加“➕”自定义配置首页主功能,加入人性化设计理念。
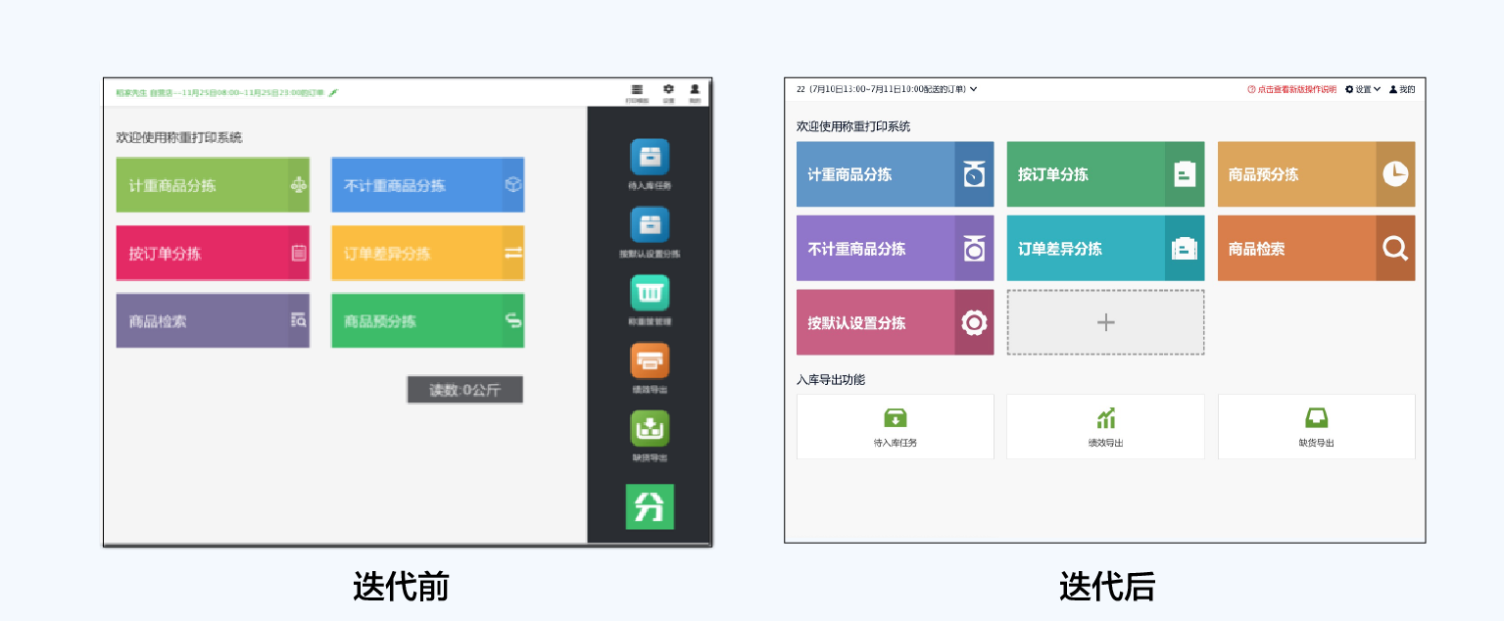
体验连接:https://www.growingio.com/projects/lPQ7bOj9/product-analytics/heatmap/j9yvlyRy(账户/密码miaomiao/liuge1)
b)找到自身价值的重要性
自身价值顾名思义就是你的工作成果会带来什么价值,按照公司更看重我们的设计能给产品的发展带来多大的价值。虽然职位的性质已经很明确你的价值的体现,但是这里注重成果的价值,设计师的成果更多是设计方案,方案成果的价值的接受度也是需要从易到难的渐进的。

举一个设计价值体现的实例。这是我之前做的新Station组件库——GM Design。设置组件和设计规范不仅保持了产品的统一性,且减少用户在使用过程中的行为认知负担,快速同事达成合作,还可以减少不必要的操作和排查,提高易用性。
设计目标:保持产品的统一性,减少认知负担,降低时间和人力成本,提高易用性
现有问题:同个功能存在组件多样、组件学习成本高、反复修改,
优化方案:1、建立组件库;2、功能类型划分,采用同一个组件的变形处理;3、组件集中化;
体验连接:https://lanhuapp.com/url/rKmeX
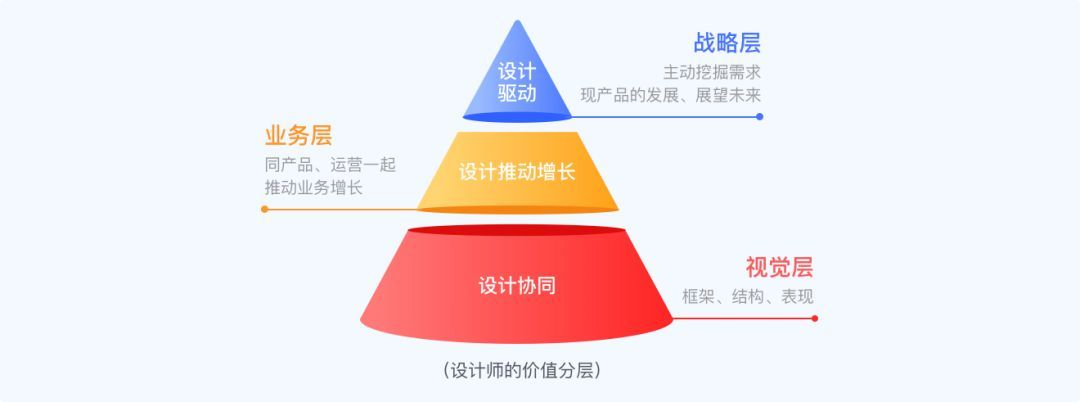
二、了解设计师的价值分层
设计师的价值可以分为以下三层:设计协同、设计推动业务增长、设计驱动产品。
a)设计协同
一个完美的执行者,能够在拿到需求后高效又完美地实现落地。简单地说就是手上功夫好。
做好这个阶段需要有优秀的专业能力,良好的沟通能力,并参与到产品的探索与构思中来。

举一个设计协调的实例。Q2阶段的B-Shop商城交互迭代。前期输出设计基础和设计规范,有助于开发高效实现,实时跟进UI进度和设计协助。在产品的探索中发现数字键盘组件的问题点,由于自己写的数字组件具有局限性,导致体验上无法满足部分需求,如:输入框的定位在数字键盘之上。基于这个问题点,我们提出A/B方案,A方案是自己写的数字组件,B方案是自己写的数字组件延用原生的逻辑,从用户测试得出,A方案是更符合用户操作习惯。
设计目标:组件高效快捷输入,侧重交互体验提升,视觉优化,提高易用性
现有问题:学习成本高、缺少设计基础、信息分层不明显、体验差
优化方案:1、划分主次信息,阅读更直观;2、建立设计规范;3、组件优化,符合用户操作习惯;4、图文结合,按钮优化,加强页面指导性
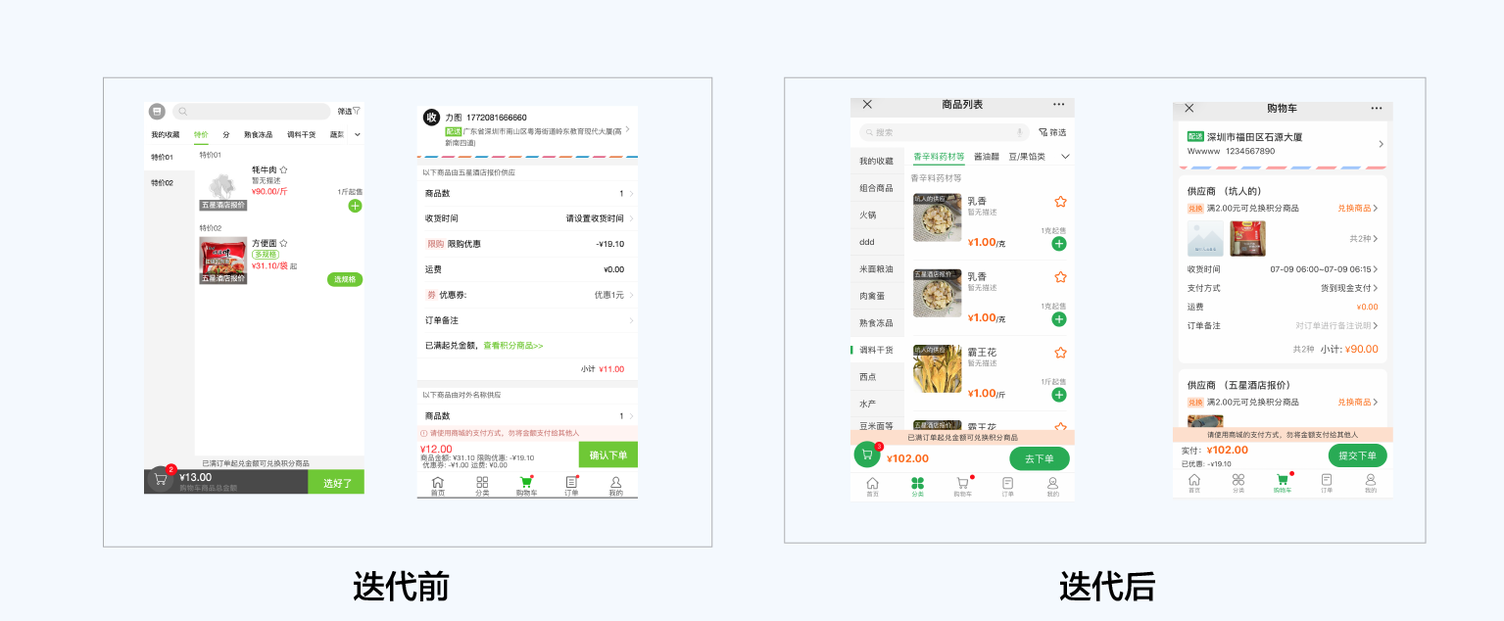
体验连接:https://bshop.guanmai.cn/?cms_key=miaotest×tamp=1561085945884#/product(账户/密码miaomiao/1qaz2wsx)
b)推动业务增长
这个阶段的设计师,会比上一个阶段更能体现设计师的设计价值,并对产品产生一定的影响力。能在以用户为中心的基础上,推动业务的增长,所以这个阶段的设计也被称为UGD(User Growth Design)。

需要设计师具备用户洞见力,数据分析能力,从这两个维度出发,去熟悉业务、分析业务,从而推动业务。
举一个推动业务增长的实例。Q2阶段的采购APP的交互迭代。表头的功能布局与标签栏的“➕”添加功能的调整,其实在用户调研阶段的热力图数据和观察法分析得出,工具类移动端侧重点在功能区,需要一目了然知道我的当前任务数是很重要的信息,且是高频操作,所以放置顶部;标签栏的添加功能是为了快速添加采购单据和询价为目的,用户群体特殊性,需要一键新建添加的需求。
设计目标:侧重交互体验提升,提高工作效率,提高易用性
现有问题:学习成本高、缺少设计基础、操作路径长、体验差
优化方案:1、操作路径简化,采用路径集合弹框;2、建立设计规范;3、组件优化,符合用户操作习惯;4、一键新建“➕”的功能,达到快速新建
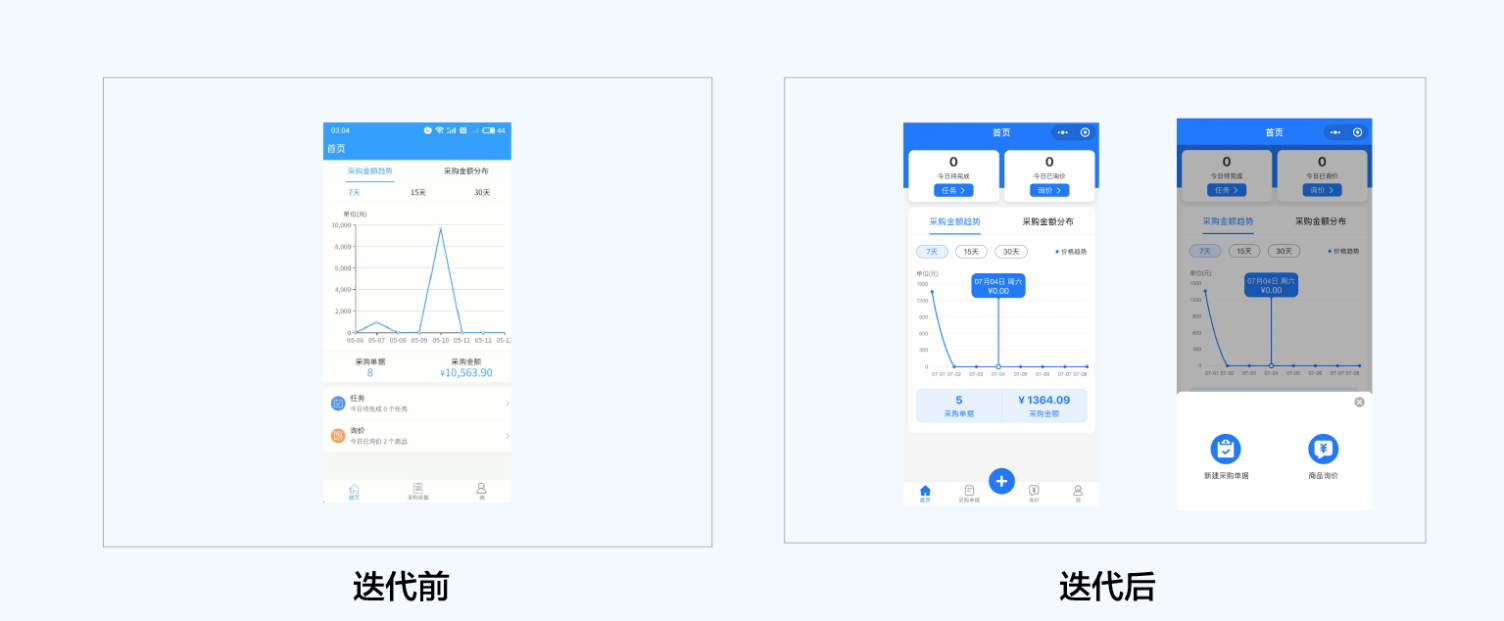
体验连接:http://station.env-bugfix.dev.k8s.guanmai.cn/purchase_assistant/#/login(账户/密码zhangsan0001/ liuge1)
c)设计驱动产品
这个阶段的设计师,在团队中的价值可以说是非常大了。从被动的需求接收方,转化为从战略层,能主动提出需求的一方。也是UXD发展的终极方向。
三、设计师需要具备的哪些思维?
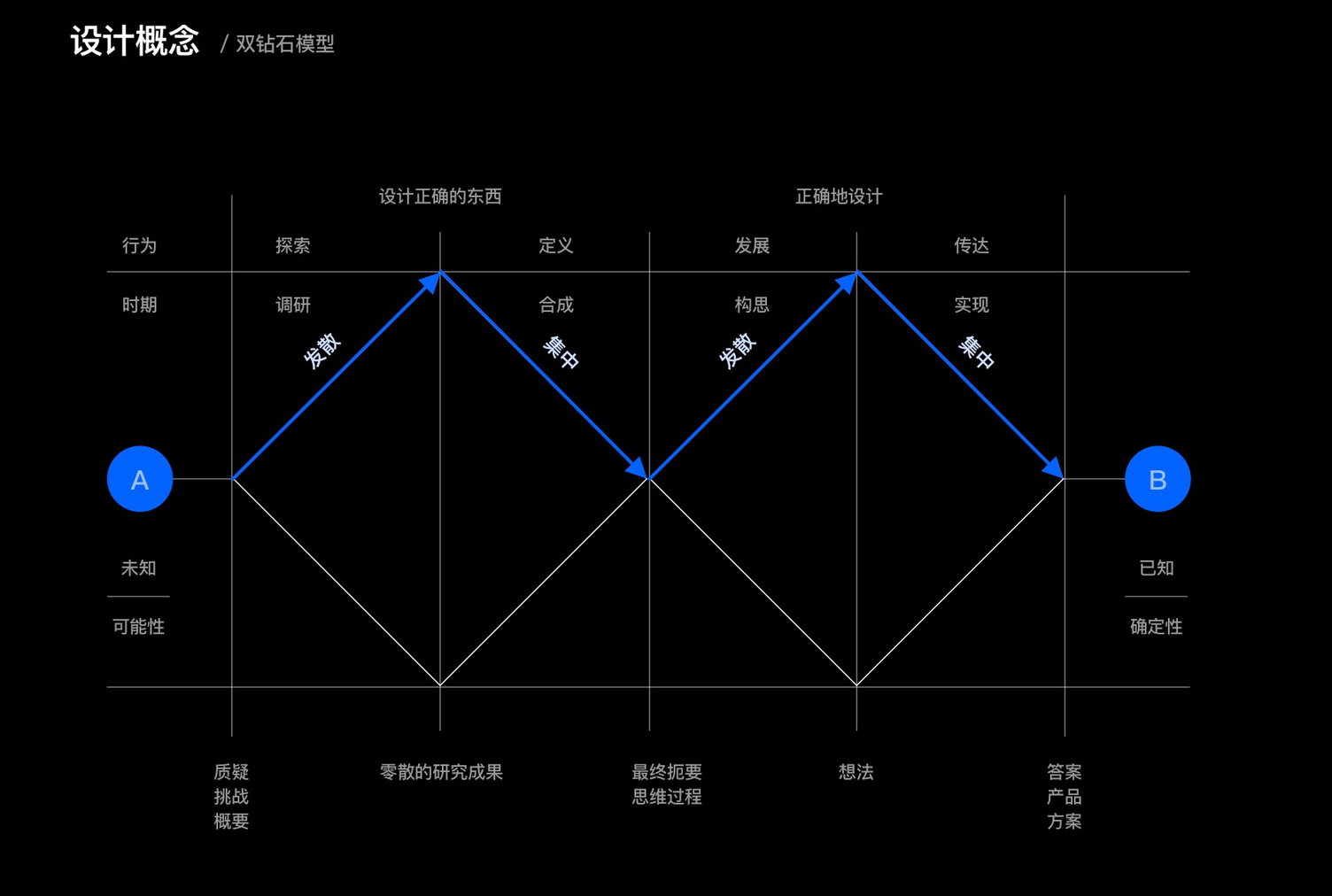
a)双钻模型解决问题
什么是双钻模型?
双钻设计模型由英国设计协会提出,该设计模型的核心是:发现正确的问题、发现正确的解决方案。一般应用在产品开发过程中的需求定义和交互设计阶段。
双钻设计模型把设计过程分成4个阶段:发现问题(挖掘)、定义问题(创意)、构思方案(制作)和交付方案(落地)。
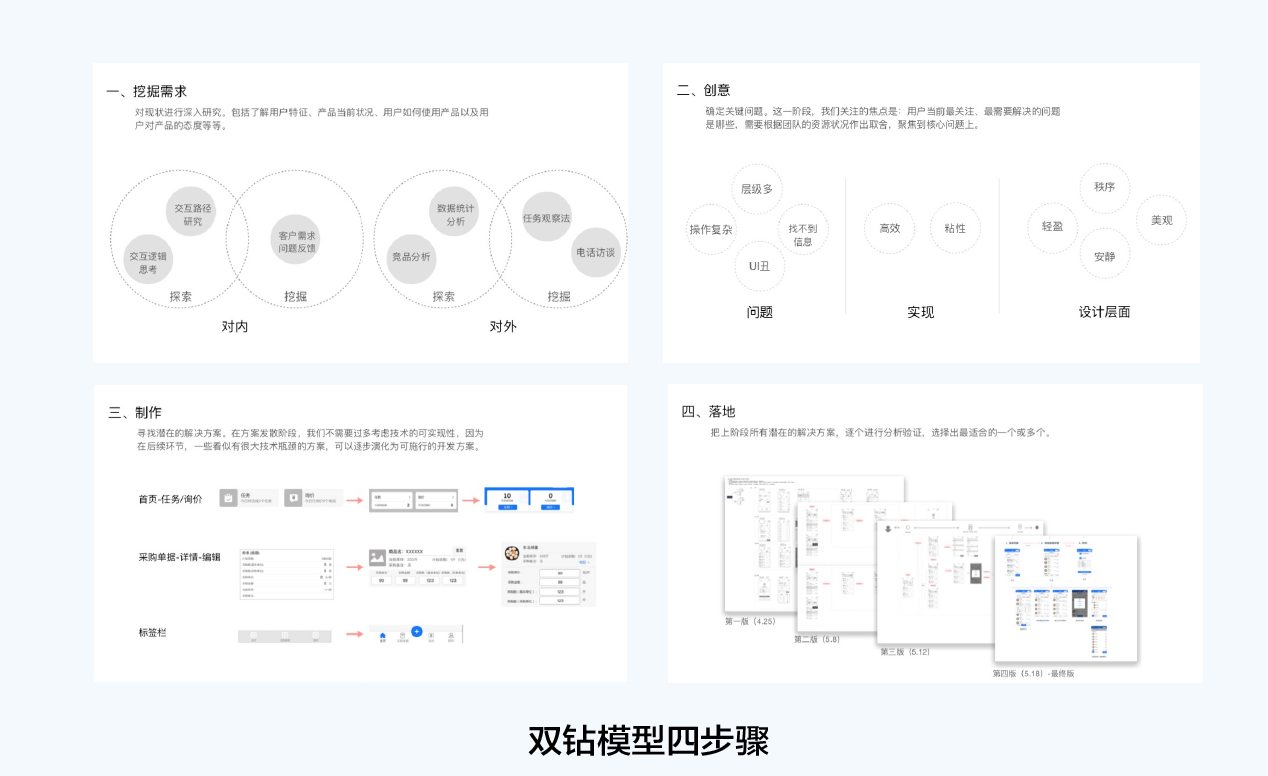
采购APP进行双钻模型思维构建的基础,提供交互迭代的底层设计理论支持,在挖掘需求阶段,属于用户调研阶段;创意阶段,关注点在于问题梳理、实现目的、设计层面;制作阶段,寻找潜在的解决方案;落地阶段,解决方案的分析和验证,输出最适合一个。
b)“五度”设计成果评估模型
用户体验周期(由阿里巴巴UED提出概念)
用户体验周期指的是用户与产品的关系随着时间变化而形成的不同周期阶段。用户体验周期可以分为「当前」和「长远」两个阶段,每个阶段中有不同的细分。
「当前」阶段,分为 3 个过程:
触达:用户来访问网站,包括第一次访问网站的新用户和再一次访问网站的老用户;
行动:用户在网站上进行相关操作;
感知:用户在操作完成后对产品形成的主观感受。
「长远」阶段:分为 2 种表现:
回访:用户自己再次使用该产品;
传播:用户推荐给其他人使用该产品。

如何在具体项目中体现呢?下图,运用一个具体项目举例:
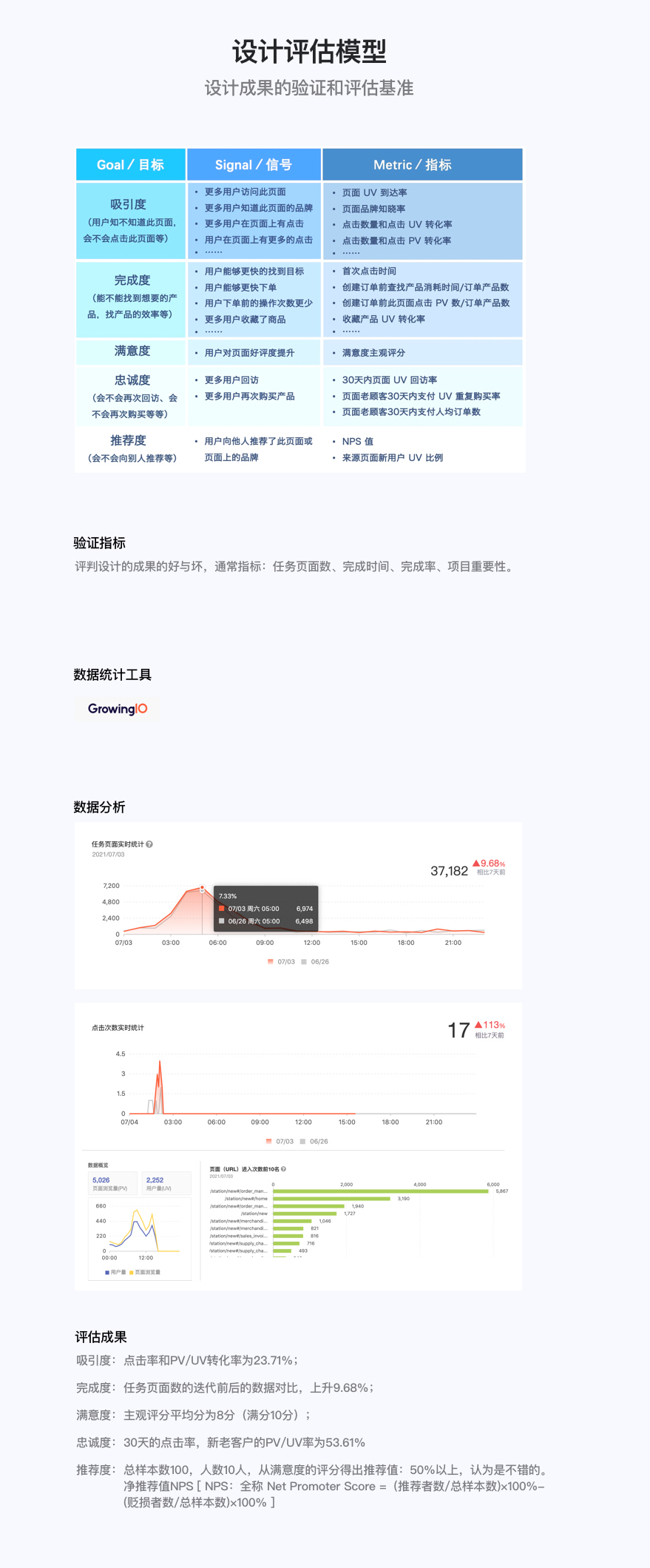
c)培养数据思维,利用数据提升设计的价值
项目与需求上线后,去验证自己的设计是否有效地达成了目标。这个时候你就需要去看数据反馈。没有数据就就没有比较,没有比较就不能进步。
关于数据的用处有很多,举个例子,当两个人对各自的方案争执不休,分别觉得对方不好,但站在各自的逻辑上似乎都能说得通,那怎么办呢?分别做一个A/B测试,数据不会说谎,哪一个方案更有效,一目了然。

那么如何将数据结合到我们的设计中呢?首先在设计前,我们需要先定一个目标,而每一个目标就应有一项对应的数据指标。比如,提高了某一块的CTR(点击通过率),提高CVR(转化率),提高商品曝光、1/7/15/30日留存率等等。方便之后去验证自己的的action是否完成了自己的Goal。
拿到了数据之后,还需要分析数据。不管是有没有达到目标,都要去分析原因,进行复盘总结。复盘的好处是可以让我们在这一次项目中吸取有价值的经验—失败了就找失败的原因,方便以后避开同样的错误;成功了就分析成功的原因,并将成功的策略复制运用到今后的工作中,增加以后的成功率。如此,不管有没有成功,都能给我们带来最大化的价值。我们也会更加的接近用户、接近产品、接近业务。从而帮助我们进一步洞察用户、挖掘新的需求。
以上就是今天所要分享的全部内容。再带大家回顾一下,一共分为三部分:第一个是了解设计师的发展趋势,第二个是趋势下的设计师价值分层(设计协同、设计推动增长、设计驱动),第三个就是在价值分层的逐步递升中所需要培养的双钻模型、GSA的策略、数据增长思维等。

分享此文一切功德,皆悉回向给文章原作者及众读者.
免责声明:蓝蓝设计尊重原作者,文章的版权归原作者。如涉及版权问题,请及时与我们取得联系,我们立即更正或删除。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
B端产品往往都具有较长的业务流程和操作步骤,需要用户循规蹈矩、通过较多的步骤找到相应的页面,来触达相应的用户目标。落实到体验设计中,需要设计师充分考虑用户在操作路径中的操作权重(频率&停留时长),进一步以核心步骤为中心向路径两端延伸,完成页面布局。
如何分析和评估用户在操作路径中的权重呢?今天介绍一下,本人从统计学中借用的一个概念——正态分布模型,并将其应用到体验设计的流程中。
1 首先,什么是正态分布模型呢?
正态分布,也称“常态分布”,或高斯分布,是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。
如果一个指标受到若干独立因素共同影响,且每个因素不能产生支配性的影响,不管每个因素本身是什么分布,它们叠加后影响的这个指标平均值就是正态分布。
如图:
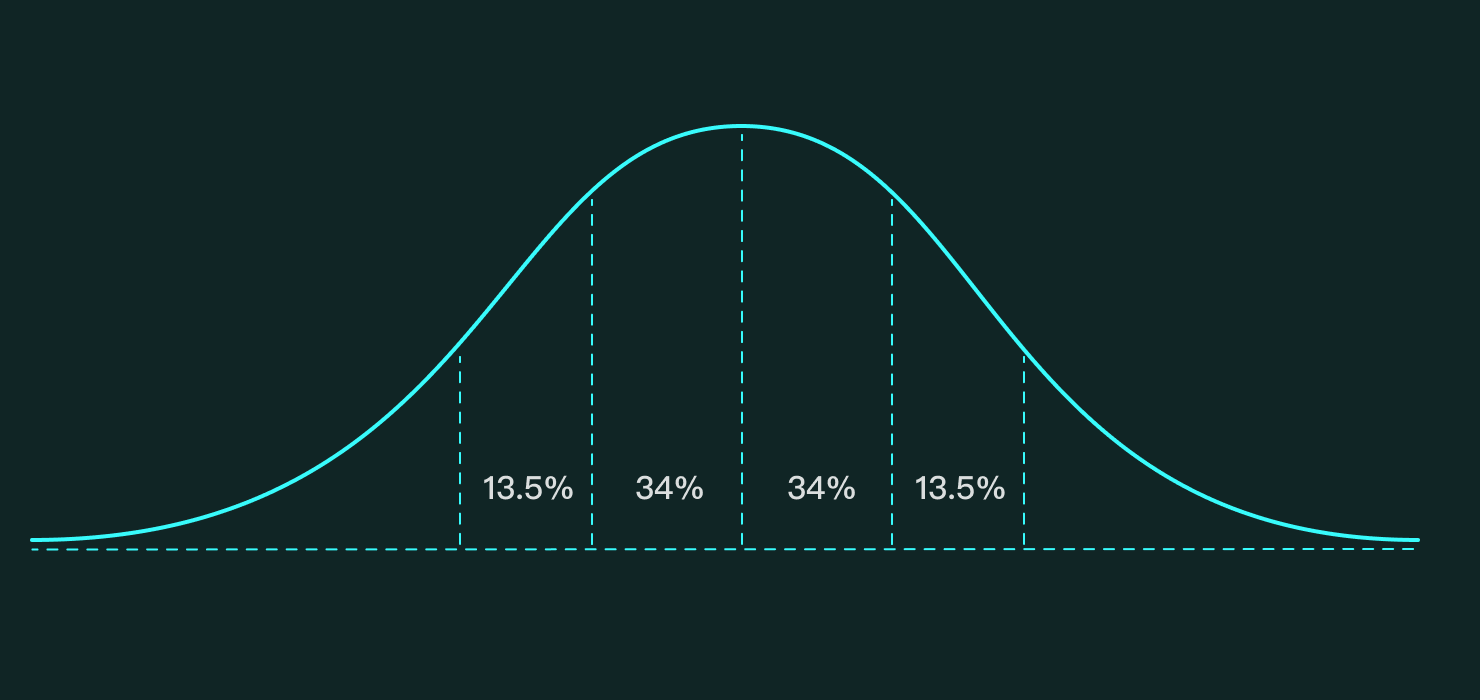
标准正态分布模型
正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此,人们又经常称之为钟形曲线。
标准的正态分布模型包含了中心极限定理的三要素,影响因素独立,因素影响程度随机但无法支配,各个因素之间是相加的关系。

中心极限定理三要素
当然,在体验设计中正态分布模型就没有那么复杂,而且用户的操作也不是随机分布。那如何在体验设计中如何应用呢?
接下来,介绍一下基于用户体验,提炼的正态分布模型。
如图: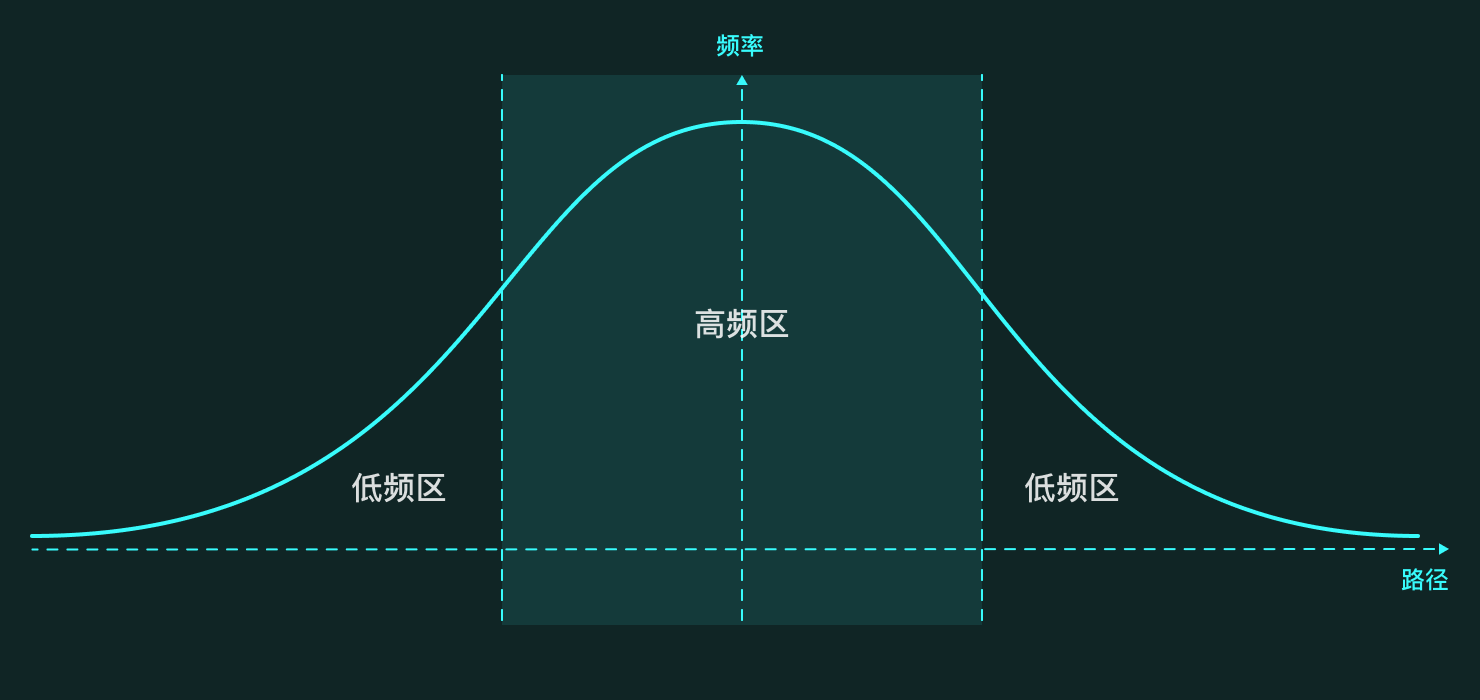
体验设计中标准正态分布模型
总的来说,体验设计中的正态分布模型,是一种用来探讨用户在某一功能的操作过程(或产品的整个生命周期)中,操作频率(权重)所集中的区间与页面布局、信息架构之间关系的方法与思维。
这个模型涉及两个维度:
一是带有指向性的操作路径(步骤/功能模块),可以是一个功能的详细、单一的操作路径,也可以是一个产品从使用到停止使用的生命周期中,用户对整体功能使用流程;
二是频率,操作路径中的步骤或者核心功能被使用的频率,即权重。这个维度可以直观的反应出用户的关注重点和高频操作,便于后续的用户引导及页面布局等。
将用户的操作频率按流程顺序放置到坐标中,即可得到类似于正态曲线的图形,直观的反映出用户在功能步骤(模块)上的关注度。
2 体验设计中正态模型的类型
根据分析功能的颗粒度不同,得到正态分布模型的验证结果也不相同。
由此,体验设计中的正态模型,大体上可分为两类:
第一类是具体的功能(功能型),通过该功能的起始到完成,获得该功能高频操作及核心页面,可有助于功能路径优化及页面布局、功能排布,让用户更方便的获取高频操作。
第二是产品整体功能(产品型),通过用户从使用到停止使用该产品的全部路径,获取用户在使用产品时关注的功能,有利于明确产品定位、优化功能架构,在B端产品上还可以进行角色和权限的管理。
接下来,我们就详细探讨一下两种类型的正态分布模型。
2.1 功能型的正态分布模型
功能型的正态分布模型多用于优化产品功能及路径。这种类型的模型关注更加聚焦,结论也更加直接,甚至可以直接应用到设计方案上。因此在分析功能路径时,要简化相关联的分支路径,避免其对聚焦问题的干扰,使分析结论更加精准。
例如,一个手机TB的购物流程,如果要研究用户购买行为,就需要更多的关注用户对商品的选择、比较等操作,同时简化用户的支付操作路径;如果研究的是购物流程中用户的支付行为,就应该相应的简化用户选择产品的路径。
如图:

举例:淘宝购物流程分析
另外,这种类型分析结果的落地,需要格外关注功能操作路径的入口及其他功能的衔接,保证在更大层级上的操作不会出现断点,保证使用流畅。
2.2、产品型的正态分布模型
产品型的正态分布模型,可以看作众多功能型路径的简化提炼版本,忽略操作细节,着眼于业务在功能模块之间的流转,多用于产品定位升级或架构调整。这种类型的模型是将产品的拓扑图,按照用户从开始使用到停止使用的的操作路径(产品的生命周期),将其映射到坐标轴上,来直观表现出产品的核心功能。
如图:

产品型&功能型
其结果属于定性结论,在设计方案时更多的是参考意义,只有在进行产品定位迭代及架构调整时,才具有指导意义。因此,在不同场景下用合适的模型才能更具有说服力。
正态分布模型的可以应用到B/C/G等多种类型的产品上,根据不同类型的产品,该模型还会有其他功能的扩展。
例如,B/G端产品往往都具有长流程、多角色、多模块的特点,当正态分布模型在B/G端产品上应用时,还可以清晰凸显角色、权限的结构,有利于对用户权限和角色的定义与管理。
3 案例分析
在本人所从事的安防行业中,实时报警的处理是较为高频、且重要的业务功能。本文仅对功能型模型进行案例分析,希望该方法(思维)的表达更加清晰明确,也能够帮到大家。
3.1 业务概述:
实时报警的业务流程大致是这样的:在监控中心或岗亭,保安人员对园区的安防状态进行警戒时,如果有异常状况触发了报警,系统会反馈推送给安保人员,安保人员通过录像抓图等信息判断报警的紧急程度以及处理方式。
3.2 业务定性
该功能是典型的“海岛事件”,具有偶然性和急迫性的特点。所谓海岛事件,是本人对具有偶然性与急迫性特点业务的概括统称,后续可以写文章专门探讨该问题。
3.3 场景推演
安保人员每时每刻都全神贯注监管整个区域的安全状态,是不可能的,更何况这类海岛事件呢?所以,在发生报警时安保人员大概率处在“摸鱼”状态。
当有报警进入时,安保人员第一时间需要确认的是报警的类型以及位置,从而快速判断如何处理。只有当报警信息不明确时,安保人员才会进一步通过录像、抓图、关联的监控来进一步判断报警信息。

实时报警场景推演
3.4 报警业务处理的正态模型分析
在整个场景推演过程中,用户的关注重点是报警详情以及报警信息的确认过程,会有较少的概率查看辅助信息,因此需要保留辅助信息的入口。
如图:
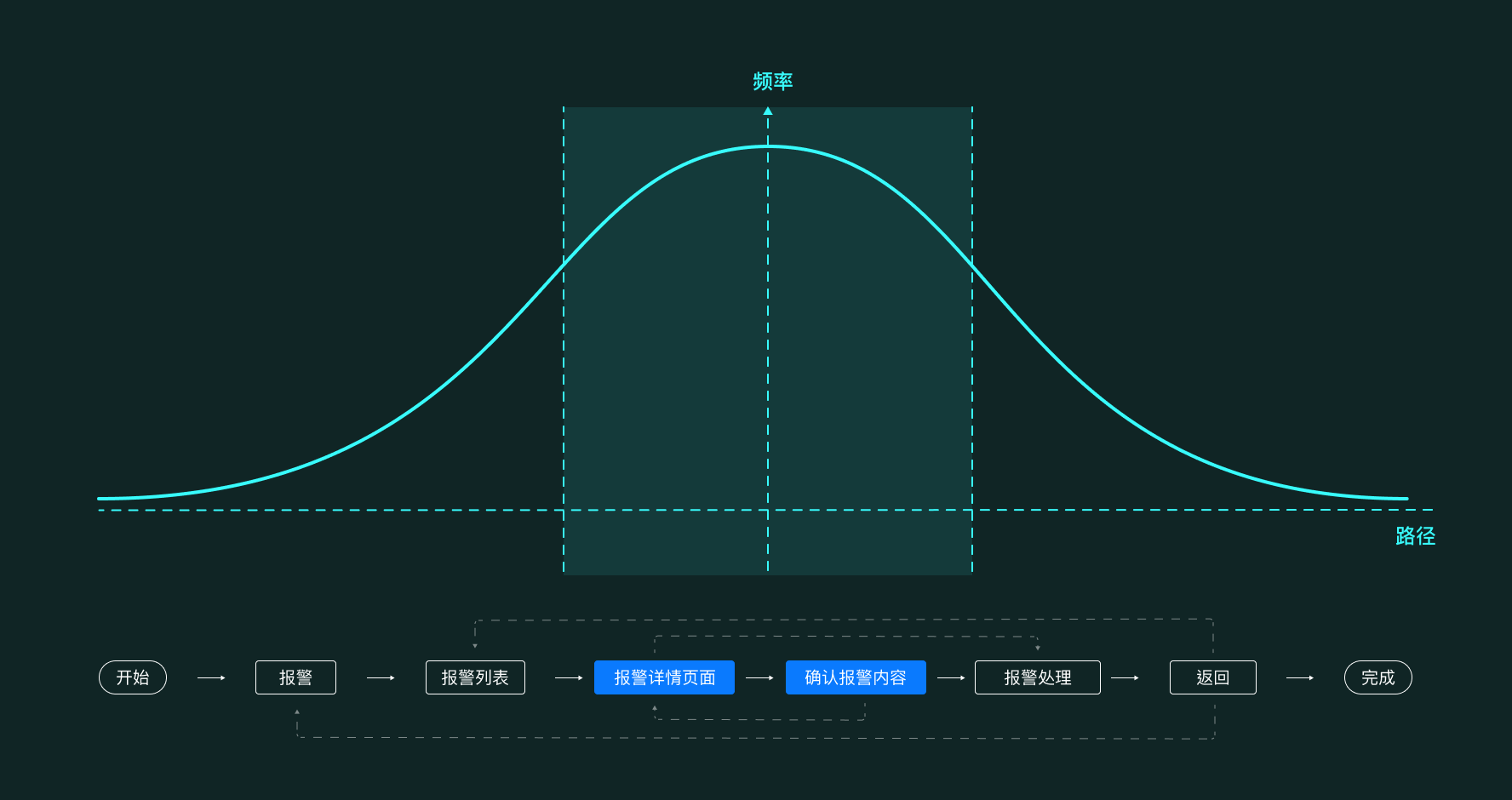
3.5 方案展示
方案采用瀑布流式,高权重的关键信息拥有更高的页面权重,用户可以快速获取信息,以判断处理方式。同时,渐进式展示确认信、辅助信息,如抓图、录像、关联视频等,一方面可以减少对用户决策的干扰,同时能够快速获取这些信息,辅助用户做出判断。
由于方案涉及到公司项目,所以方案不方便直接展示,这里只展示页面信息布局。

我们都知道,在页面纵向布局上,随着视觉流的下移,用户的关注度会逐步降低,因此,在实时报警处理页面布局上,将从上到下信息的重要性逐级降低。
首先是实时报警处理的核心区,分为两个部分基本信息区与视频辅助区,这两部分信息是判断实时报警性质以及处理方式的主要依据。其中,基本信息区是最重要的,用户可以根据报警的基本信息,来确定如何处理报警。对于大部分的报警信息,用户可直接判断报警是否需要处理,或是进一步的确认及验证,尽可能的减少用户的操作;因此,报警的处理入口,紧随基本信息。
而视频辅助区是对部分报警的回放确认,是在查看基本信息后的进一步操作,频率相对较低,因此虽然属于核心区,但是层级却低于基本信息的展示。
辅助验证区放置的报警期间的连续抓图,可以满足用户的放大查看,进行报警辅助确认,随着用户视觉流下移,其重要程度迅速降低,相应的操作的步骤也较为复杂,页面视觉权重也有较大的压缩。
最后,对于极少的报警信息,用户需要通过关联视频的信息进行验证,可通过页面底部的关联视频入口,点击展开关联视频浮层,进行报警信息验证。这是整个实时报警的最后一个层级信息展示。
4 写在最后
正态分布模型不仅仅是一个工具、方法,同时,也是一种设计思维。
在设计之初,充分理解功能的定位,完善功能入口,让用户更容易触达产品的核心功能。然后通过核心功能向业务两侧进行延伸,进而覆盖整个业务,完成产品的框架与流程的构建。
在设计之中,关注高频的核心步骤,让用户的高频操作具有更简便的操作空间,把用户更想知道、更想操作的内容推送到用户面前,让用户在整个操作流程中的操作频率与页面布局的权重分布相匹配,而不是想当然。
只有这样,设计才更具价值,才能培养更忠诚的用户。
分享此文一切功德,皆悉回向给文章原作者及众读者.
免责声明:蓝蓝设计尊重原作者,文章的版权归原作者。如涉及版权问题,请及时与我们取得联系,我们立即更正或删除。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
NFT,即非同质化代币,具有唯一性,某种程度上也可以称为一种数字资产,由此也产生了一定的收藏价值。而NFT也被品牌们“盯”上,成为品牌营销的方向之一。本篇文章里,作者就NFT的定义、价值,以及营销层面上NFT与品牌的结合做了解读,不妨来看一下。
不知道最近大家有没有发现NFT(非同质化代币)概念很火?甚至蔓延到了营销圈……
近日, Burberry Blanko为旗下多人游戏《Blankos Block Party》打造 B Series 限量版游戏角色-Burberry Blanko,玩家可以在游戏中收集、出售 Blanko NFT 公仔。
?")
图片来自:微博@Burberry
奥迪携手艺术家程然 Chengran 创作了 NFT 艺术作品《幻想高速》,该作品以新奥迪 A8L 60 TFSIe 为灵感,在虚拟现实美学层面,延展对未来的自由幻想。据悉,该作品将通过 xNFT Protocol 限量铸造与发行。
?")
图片来自:品牌
8月,潮玩互联网品牌 IP 小站也推出首款 NFT 盲盒——EMMA 甜蜜森林系列。据悉,用户只需购买一只实体玩偶,便能在 IP 小站 APP 内随机获得一款同系列的 NFT 数字艺术收藏品,在 IP 小站里还能进行潮玩交易。
?")
图片来自:品牌
另外近日,腾讯音乐首批“TME数字藏品”也即将上线。胡彦斌《和尚》20周年纪念黑胶NFT在QQ音乐平台开启购买资格的抽签预约,限量发售2001张。
?")
图片来自:腾讯音乐
之前,宝洁公司旗下的卫生纸品牌 Charmin 推出过厕纸主题 NFT,一共推出了 6 款限量的NFT厕纸,其中005 号“ 作品 ”,现报价是 2200 美元。
除此之外,让NFT不断走进大家视野的“出圈事件”还有……
2021年初,美国乐队林肯公园的创办者、联合主唱Mike Shinoda将自己制作的一段音乐作为NFT拍卖,最终以3万美元成交。
3月6日,推特CEO Jack Dorsey发布了一个指向平台“Valuables”的链接,页面打开后,是他于2006年发布的首条推文“just setting up my twttr”(刚设置好我的推特)正在上面拍卖,最高出价250万美元。
?")
图片来自:网络截图
3月11日,一枚代表着艺术家 Beeple 创作的、由5000张较小图像组成的数字画作所有权的 NFT,在佳士得拍卖行以超过 6900 万美元(约4.5亿人民币)的竞拍价售出,震惊了艺术圈。
?")
图片来自:网络截图
不知道大家听了这些新闻,是什么感受?是不是也一脸懵?或者充满很多疑惑,NFT到底是什么?有什么价值?为什么有人为之买单?对于品牌来说,NFT可能会带来哪些机会吗?
时有趣也不明白技术上的复杂知识,只能参考国内外资料,进行一些普适性定义上的解释。NFT英文全称为Non-Fungible Token,也叫「非同质化代币」,具有不可分割、不可替代、独一无二等特点。
NFT 是一种数字资产,代表现实世界的对象,如艺术、音乐、游戏内物品和视频。它们在网上买卖,经常使用加密货币,并且它们通常使用与许多加密货币相同的底层软件进行编码。简单来说,也就相当于带有编号的人民币,这个世界上不会有两张编号一样的人民币,也不会有两个完全一样的NFT。
首先,NFT存在于区块链上,区块链是记录交易的分布式公共分类“账本”,NFT 是从代表有形和无形物品的数字对象中创建或“铸造”出来的。NFT由于其非同质化、不可拆分的特性,使得它可以锚定现实世界中商品的概念,简单来理解,就是在发行在区块链上的数字资产,这个资产可以是游戏道具、数字艺术品、门票等,并且具有唯一性和不可复制性。
由于NFT具备天然的收藏属性和便于交易,加密艺术家们可以利用NFT创造出独一无二的数字艺术品。比如,NFT 可以代表一幅画,一首歌,一项专利,一段影片,一张照片,或者其他的知识产权。比如上海美术电影制片厂就铸造了「大闹天宫系列」的NFT作品,价值49美元、99美元、149美元不等,目前均已售罄。
?")
图片来自:网络截图
这听起来很荒谬:花了这么多钱,就只证明了我是这幅画唯一的实际拥有者吗?
但这确实是NFT狂热中很关键的一点。但时有趣也认为,人们收藏NFT作品,一方面肯定是出于心理上的认同,“觉得它有收藏价值”;另一方面,目前来看,这种收藏行为也可以彰显收藏者在数字领域的身份。
?")
图片来自:网络截图
以上海美术电影制片厂就铸造了「大闹天宫系列」的其中一个NFT作品的交易记录为例,也可以看到上海美术电影制片厂作为铸造者挂售99美元并卖出,用户挂售的历史价格和交易行为将全部被记录在区块链上,每一个NFT作品有且永远仅有一名拥有者。这保证了交易品的真实性与独特性。基于这些特性,NFT不仅在保护版权的条件下为数字内容创作者创造了更多机会,同时还为收藏玩家提供了更大的交易市场。
虽然无法预估目前的市场规模,但它的规模肯定会进一步扩大。一个新的领域,也必须要在经历了不同周期以后,才能确定它真正的价值。
当用户愿意为了一串token买单,当品牌的存在不仅仅在于现实世界,当所有交易行为将记录在册……这一切都变得既危险又迷人。通过观察学习各种的NFT案例和知识,从营销角度出发,时有趣也发现了以下几个有意思的点:
事实上,除了上述的例子,今年5月份以来,几乎每一天都有各大品牌入局NFT的消息,路易威登、Burberry、奥迪、保时捷、可口可乐等品牌都不约而同发布了自己品牌的NFT藏品。
而通过观察这些铸造NFT作品的品牌,也可以发现,大多都是我们认知里,品牌做得非常成功,且具有影响力的品牌。时趣之前也提到过,品牌表现在产品的虚拟价值中,是建立在消费者心中的认知和心智,随着时间的积累,门槛越来越高,越难以被竞争对手超越和抄袭。
品牌战略、品牌建设、品牌管理,乍一听很虚,但是“虚者实之,实者虚之”,越是虚的管理能力,越有可能成为品牌最后长大的关键瓶颈,越需要品牌更早的理解和建设相关的管理能力。
?")
图片来自:网络
所以也不只是产品定价高的高奢品牌铸造的NFT作品才有市场,有影响力的品牌也同样可以在NFT领域获得关注。
比如,必胜客加拿大公司在“让每个人都买得起,就像吃一口披萨花不了多少钱一样”的理念支持下推出了一款“像素化披萨”艺术品,并将其以约0.18美元的价格挂在了NFT交易平台上。此NFT作品为必胜客带来了营销机会。每周必胜客都会发布一片新口味披萨的NFT,第一个新口味披萨的NFT已经售出,之后上架的新NFT售价也迅速飙高,达到了约9000美元。
时有趣之前看过一篇解析NFT的文章说:“如果NFT的价值核心是共情,那么价值传输就是通过认同来进行传输。认同这个概念其实是有关于一个人对自己社会、心理身份的认定,而在NFT市场里一种认同会变得非常明显。”
即使在数字化的趋势下,很多品牌都更倾向于把「人」作为完全理性的存在,只管性价比不问品牌,而NFT则给品牌们提了个醒,人们还是会为了认同感而买单。
?")
图片来自:网络
比如卫生纸算是典型的日常消耗品,但宝洁公司旗下卫生纸品牌Charmin推出的五件NFT加密艺术品,起名为“NFTP”非同质化卫生纸。这个新颖的想法还是立刻引起了许多人关注,且售价高达约264.72美元。负责人表示相关收益会捐献给人道主义援助慈善机构Direct Relief。在NFT支持下的品牌营销方式不仅扩大了Charmin的知名度,并且在尽可能在最小的成本之下提升了品牌在公众之中的好感度与影响力。
不难发现,很多品牌对NFT的运用主要集中在游戏、盲盒、艺术等领域。比如,之前LV和英雄联盟的联名合作,是为消费者在虚拟游戏世界塑造人物形象,寻找身份认同,提供了更多的可能性。
而如果说虚拟向左,现实向右,NFT的进一步发展,其实是将品牌带入了另一个「虚拟与现实」的十字路口。
你以为手表、香水都必须有实物才能被消费?实则虚拟和现实的边界也许正在被打破。时尚奢侈品品牌捷克豹(Jacob & Co.)在3月底宣布和NFT平台ArtGrails合作,推出世界首款只存在于虚拟世界的手表。德国美妆和生活方式公司 Look Labs 在三月底推出了首款NFT香水。该团队用近红外光谱仪收集了自家另一款香水Cyber Eau de Parfum的光谱信息,并将这些信息铸造在了NFT中。
?")
图片来自:Cyber Eau de Parfum
对于用户来说,NFT的特性使得一件NFT作品成为了独一无二的资产,免去鉴别真伪的麻烦。而对于品牌来说,NFT的独特性也使得品牌可以大大减少市场上假冒复制品的流通,无论是在新品发售还是二手市场,商品的价值都能得到保证。
比如,早在两年前,运动品牌耐克就已经看到NFT趋势,当时就为一个名为“CryptoKicks”的NFT球鞋申请了专利,用户可以通过该系统通将加密的数字资产附加到球鞋等物理产品上。Nike和用户都可以通过此系统依托区块链技术追踪产品所有权,并验证其真实性。
?")
图片来自:网络
当用户购买一双Nike球鞋时,会收到和这双鞋配套的唯一的数字资产(ERC-721代币),即同时获得鞋与代币,二者结合即被称为CryptoKicks,意为加密球鞋。随后系统会生成一个“CryptoKick ID”,其中记录了球鞋材料、所属系列、具体型号等信息,并会被存储在一个被称作Digital Locker的加密货币钱包类型APP中。
和球鞋一样,鞋款所对应的数字资产一起也转移到其买家手中。只需把数字通证转移,相应的所有权信息也将随之转移,而且是防篡改的。
虽然NFT有很多“新奇特”,但作为一个新兴事物,品牌在自己消化其知识的同时,还需要给予用户一定的时间去建立对NFT的认知,并接受虚拟空间的产品形式与交易方式。
另外,由于NFT技术的复杂性,品牌需要投入大量的资本与精力在数字技术与内容创新方面寻求发展。
蓝蓝设计建立了UI设计分享群,每天会分享国内外的一些优秀设计,如果有兴趣的话,可以进入一起成长学习,请扫码ben_lanlan,报下信息,会请您入群。欢迎您加入噢~~希望得到建议咨询、商务合作,也请与我们联系。
分享此文一切功德,皆悉回向给文章原作者及众读者.
免责声明:蓝蓝设计尊重原作者,文章的版权归原作者。如涉及版权问题,请及时与我们取得联系,我们立即更正或删除。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
作为产品经理/交互设计师,我们无时不刻都在处理信息,我们调研用户收集需求信息,从用户反馈了解产品使用的问题。我们从接收的有限信息整理信息发散思维,我们在工作流程中需要不断地处理和重塑信息,最后落地到实际产品上。这里就作者在实际工作中的应用与理解给大家阐述一点小知识,希望能够给疑惑的你们带来一点帮助。
我们首先需要思考一个问题:在产品设计中信息处理的本质是什么?
两个关键词:挖掘和理清。

整理信息的方法都有哪些呢?在《超级整理术》这边书里的讲述了作者关于他如何整理的方法。
如下图:
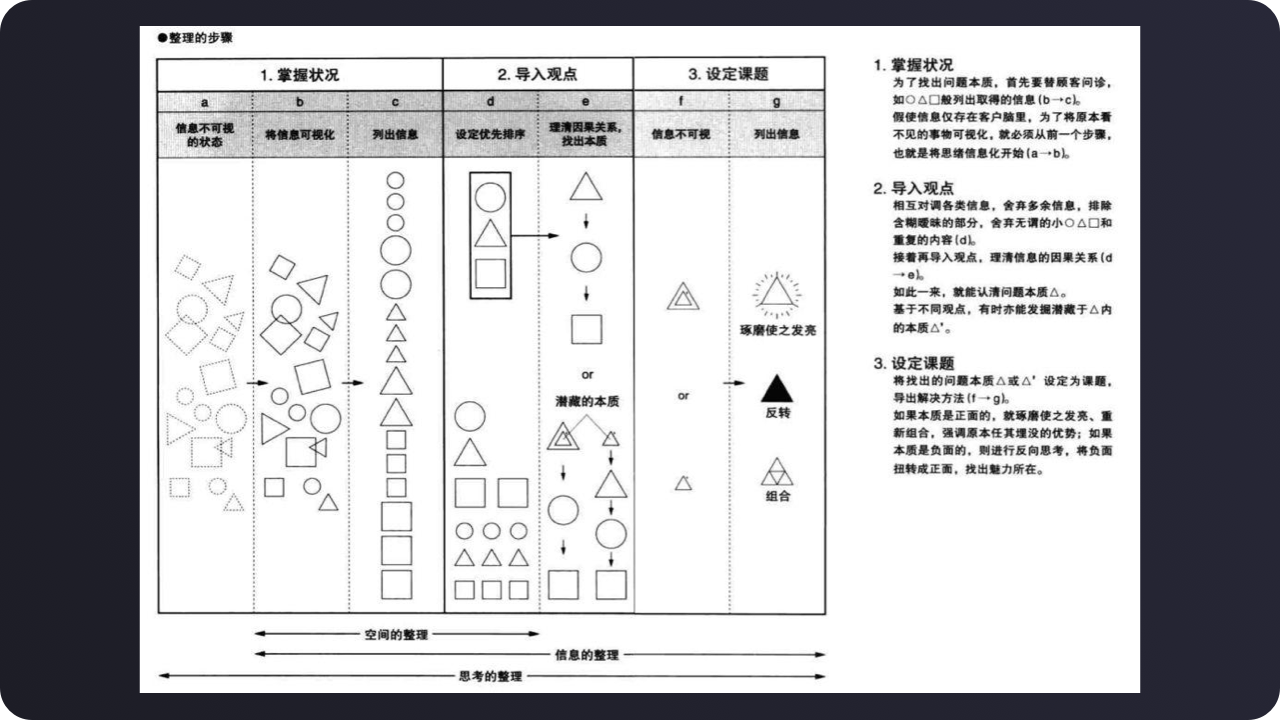
通过这一方法的实践与优化,我把应用到产品设计中的方法提炼。
信息处理的三个阶段:
在工作项目中,我们要如何进行信息的收集呢?分为四步走:
明确目标——确定信息源——建立收集器——整理分类

首先要明确目标,为了达成怎样的目标,建立目标关键筛选集合,锁定要收集信息的范围。
例:为了达成需求到产品转化,我们在产品工作中需要收集需求信息,建立目标关键筛选集合。
其次,建立需求池。
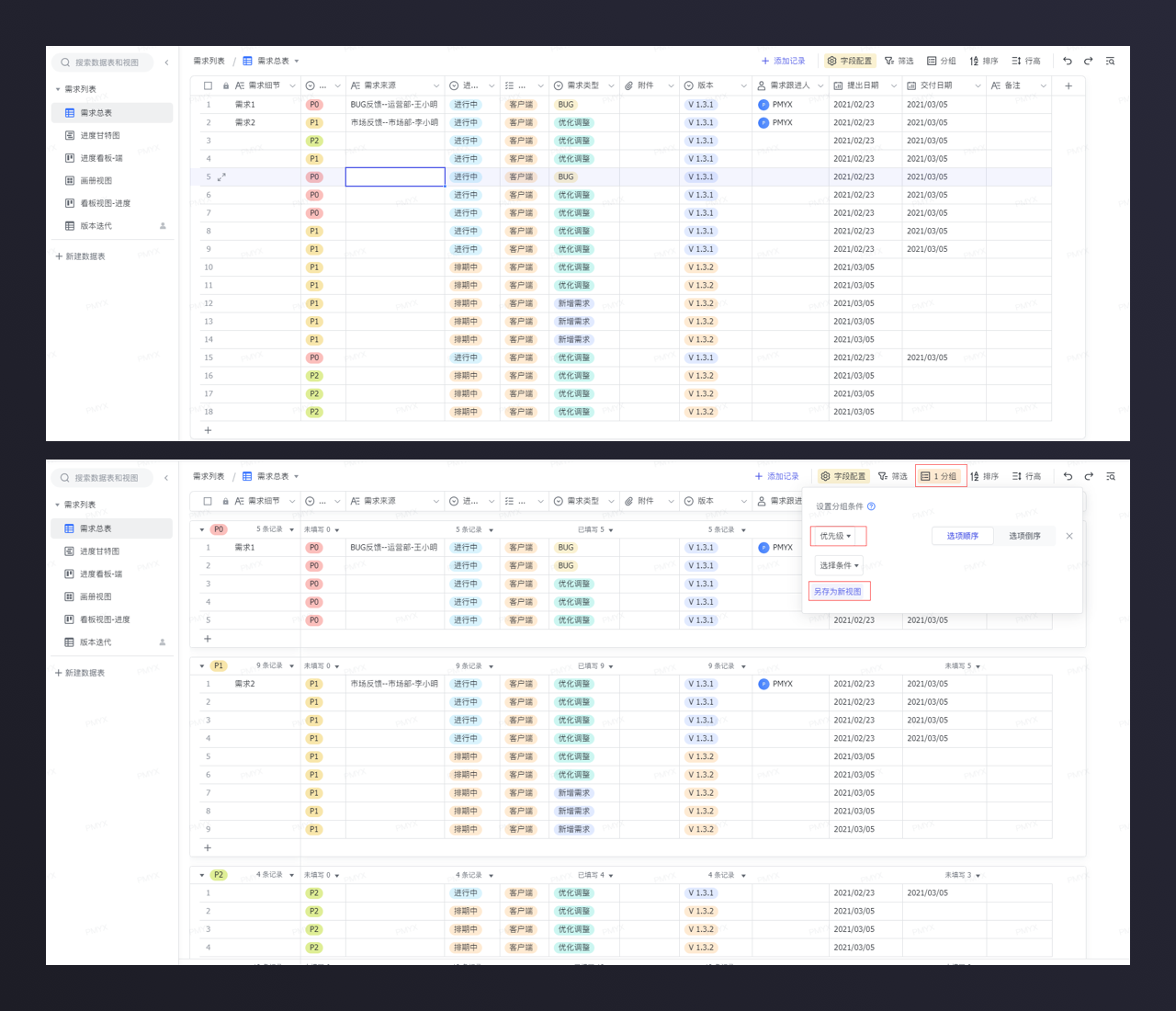
产品设计中最常见的需求收集工具——需求池。
进行需求的收集,是产品日常工作中最常见的工作之一。
运用多维表格进行需求池管理,从多个维度来进行需求的数据统计分类。
两个软件:【飞书多维表格】和【维格表】,都是做需求整理的好工具。
可以根据数据关键字快速筛选展示。
我们处在一个大世界中,作为一个独立的个体,我们无时不刻都在接收着来自四面八方各色各样的信息,有人的地方就有“信息场”。
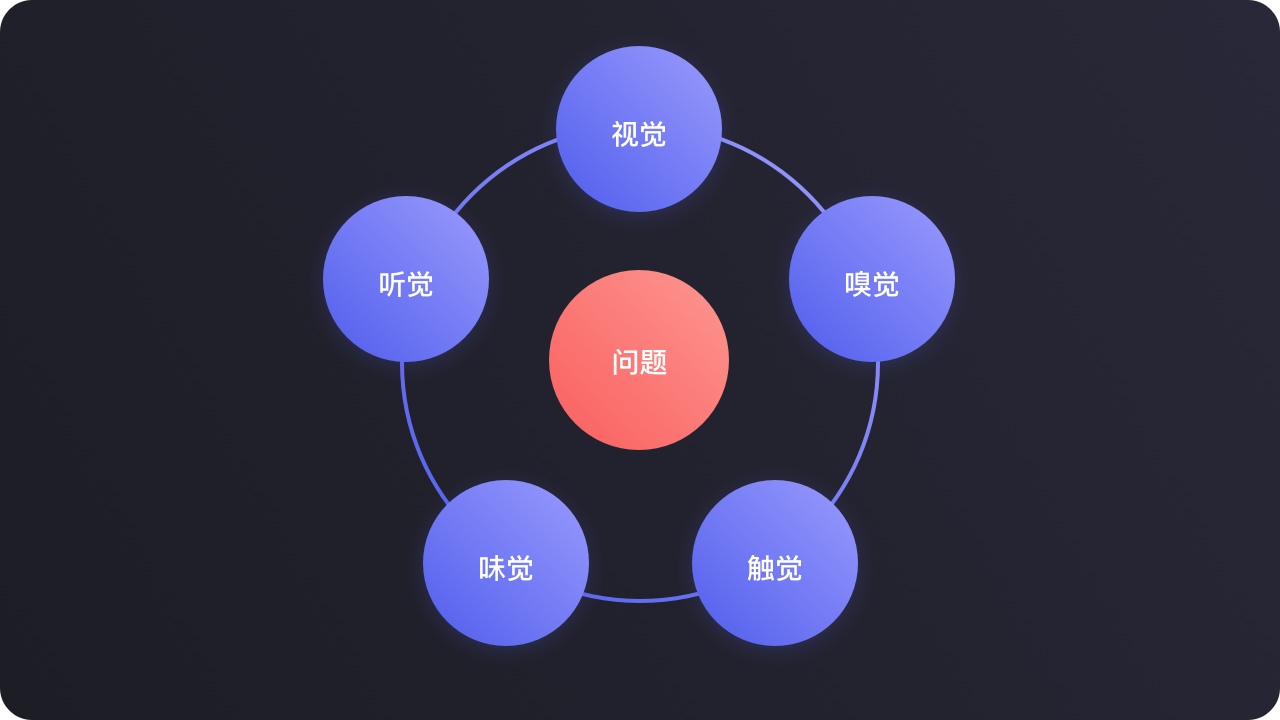
例如我们用“五感”在生活的场景里进行着信息交换:
做为一个产品设计者,做产品设计,研究用户使用场景,为的就是更好的应用到用户的生活、工作、学习等场景中。
我们需要保持信息的敏感度,学会观察周围的信息,无论来源于生活、工作、学习。
对他人时一个微不足道的小信息,可能就是触发你某个灵感的契机。
就和推理悬疑剧里破案一样,从案发现场收集的信息,通过信息关联,挖掘更多的信息,这样才能更好的辅助我们找到“嫌疑人X”。
同样,接收信息后,发现这些信息无法立马精准到“关键X”,这个时候,我们需要通过自身的经验、知识库、知识搜索、外界帮助来找寻更多的信息线索。
因此我把信息的认知思辨切分为两个维度,由点拓展到线,再由线拓展到面。
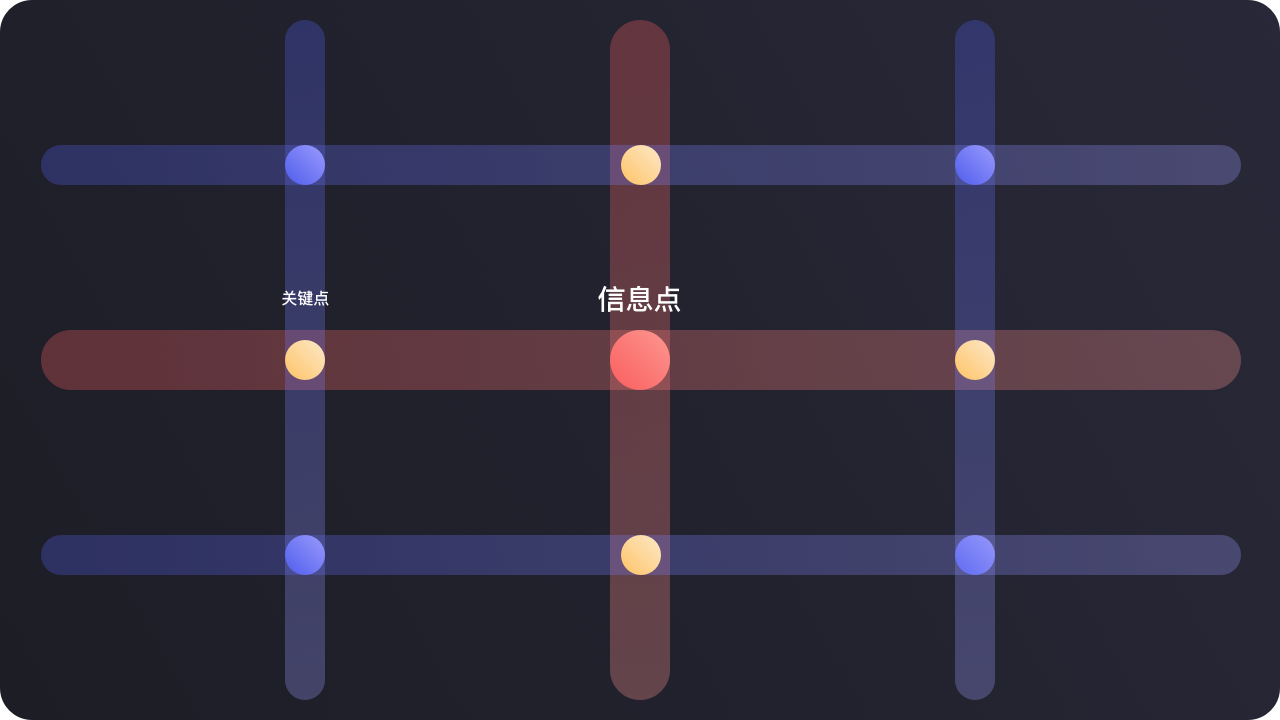
在信息深度上拓展,指的是当我们接收到信息后,对问题本身的解构,具体问题具体分析,深挖问题背后的本质原因,从而解决它。
1)怎么挖掘信息的深度
怎么挖掘信息的深度——5W法则。
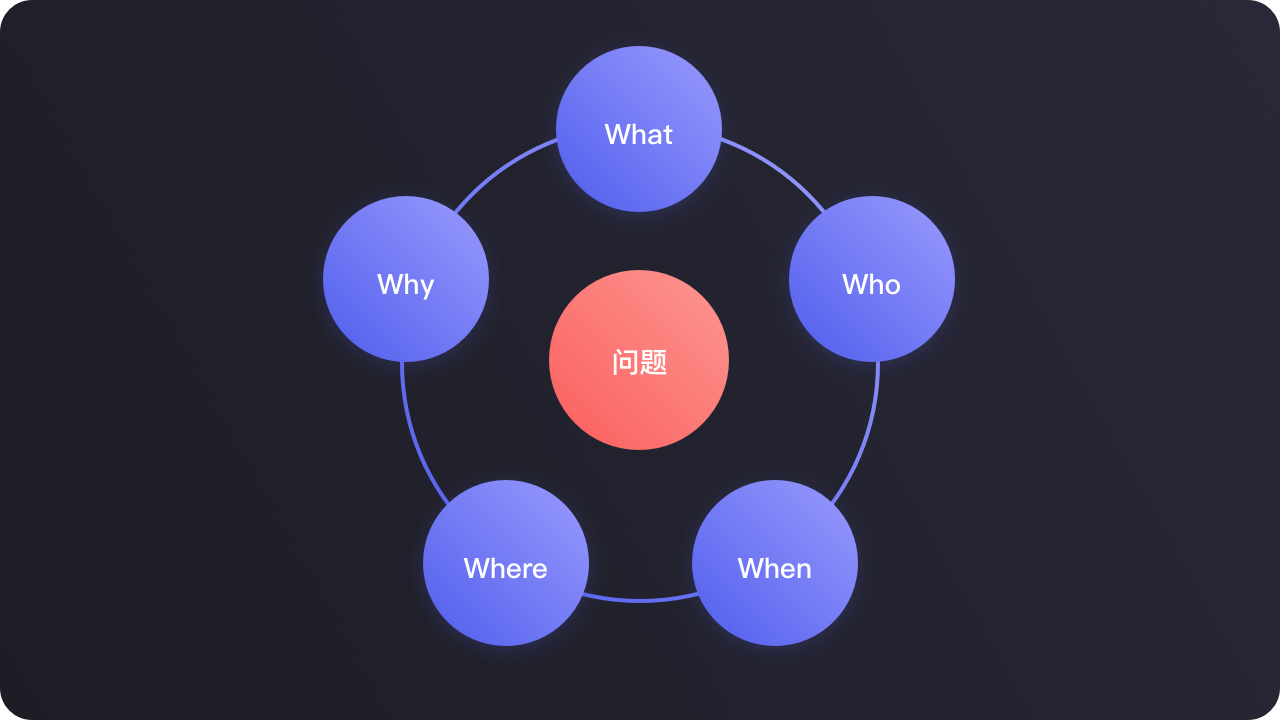
What什么事:
一定要明确是什么事,才有行动的标准,行动之前先思考后行动。
what能让你定位到事件本身,此时需要挖掘更多信息来帮助你解决这个问题。
WHO什么人:
一定要弄清你服务的对象,问题提供者可能不是真实发生问题的人,在信息传播过程中,信息是会损耗的,我们需要明确实际发生问题的人,再切入解决问题。
Why原因是什么:
用户为什么要这么做,这个信息很关键,促使他想加功能的动机是什么?
Where什么场景:
什么场景下发送的问题,促使他想要加功能,通过场景分析可以帮助我们分析是不是真的是需要这个功能才可以解决用户的真实问题。
When什么时间:
发生时间:发生问题的时间,用户发生问题的时间点,有利于缩小日志排查范围。
关键时间:什么场景下触发的这个“关键节点”,这个关键节点的时间,我们可以称它为“关键时间”。
2)产品信息结构的设计
怎么进行产品信息的拆解——用户五要素。
这里我们可以利用信息层级递进的方法来进行信息深度的挖掘。
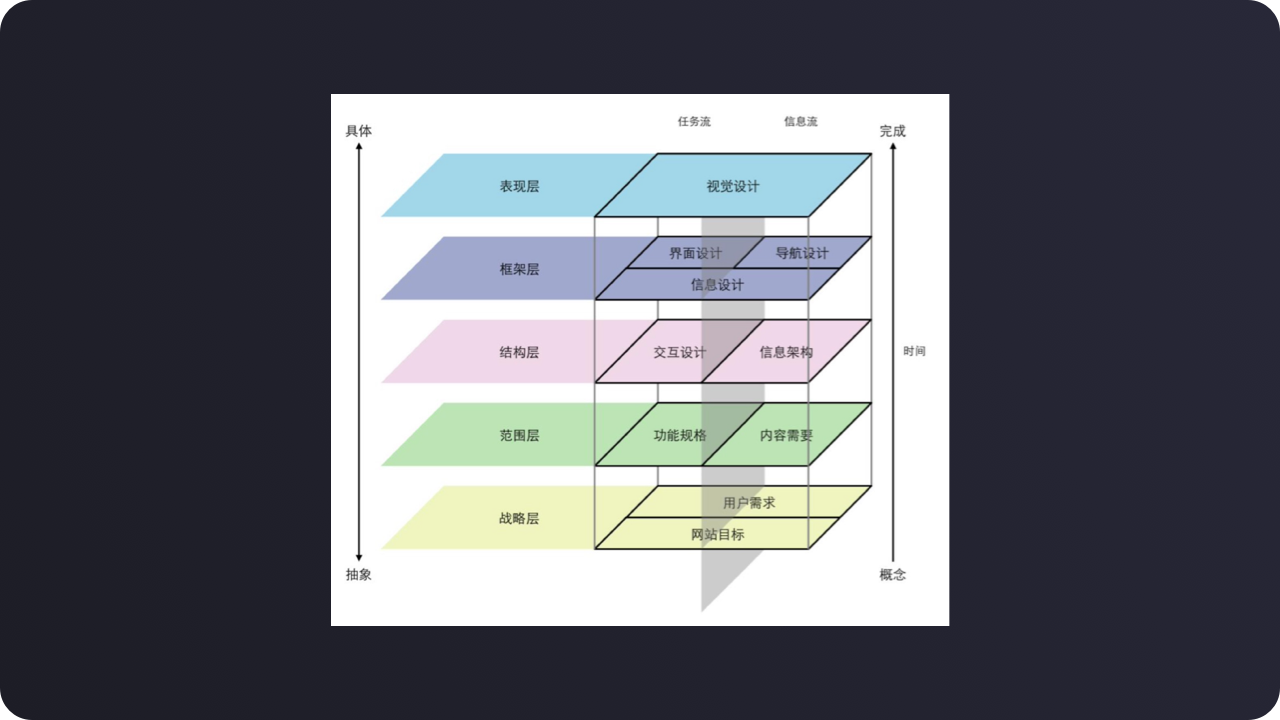
引用用户五要素的方法细化自己的产品设计工作流程形成逐步递进的工作流程。
如下图,是我在工作当中常用的工作流程。
业务目标-业务流程-系统框架-功能结构-信息结构-交互设计-用户体验
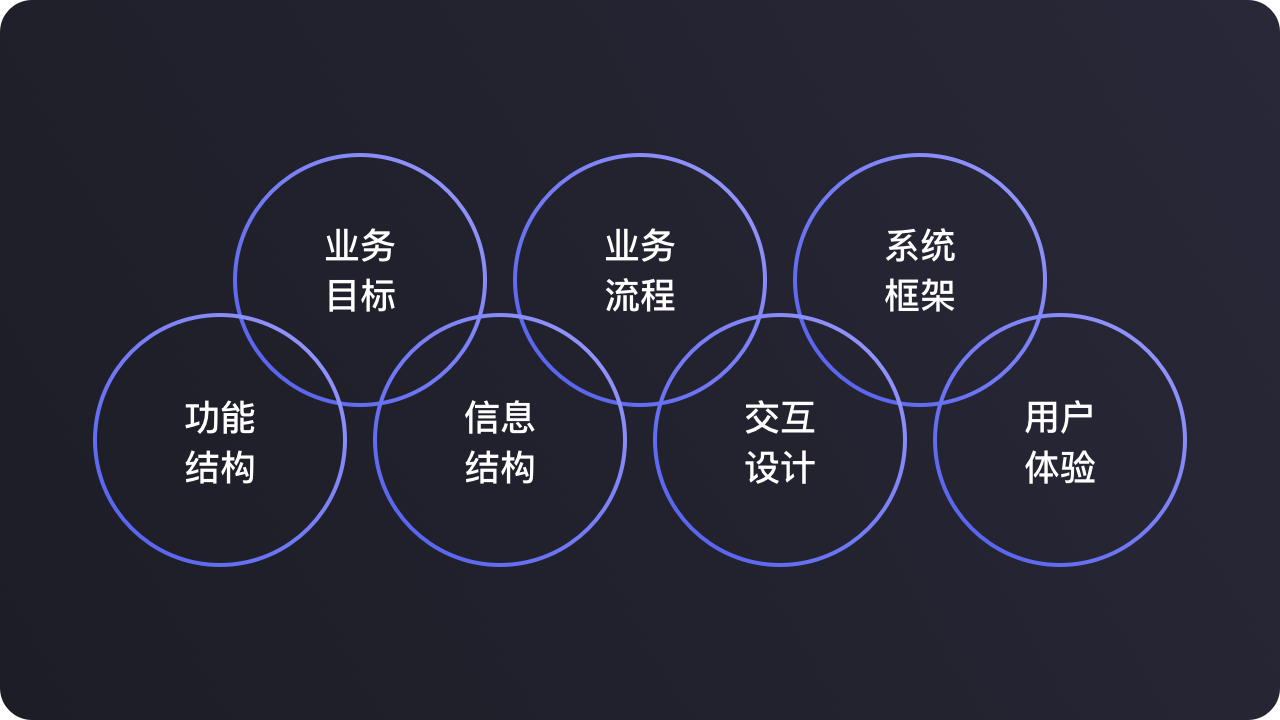
怎么挖掘信息的广度?
信息广度的挖掘,和在一本探案小说里找寻各个人物之间的人物关系的方式很像,只不过从找寻人物之间的关系变成了找寻信息之间的关系。
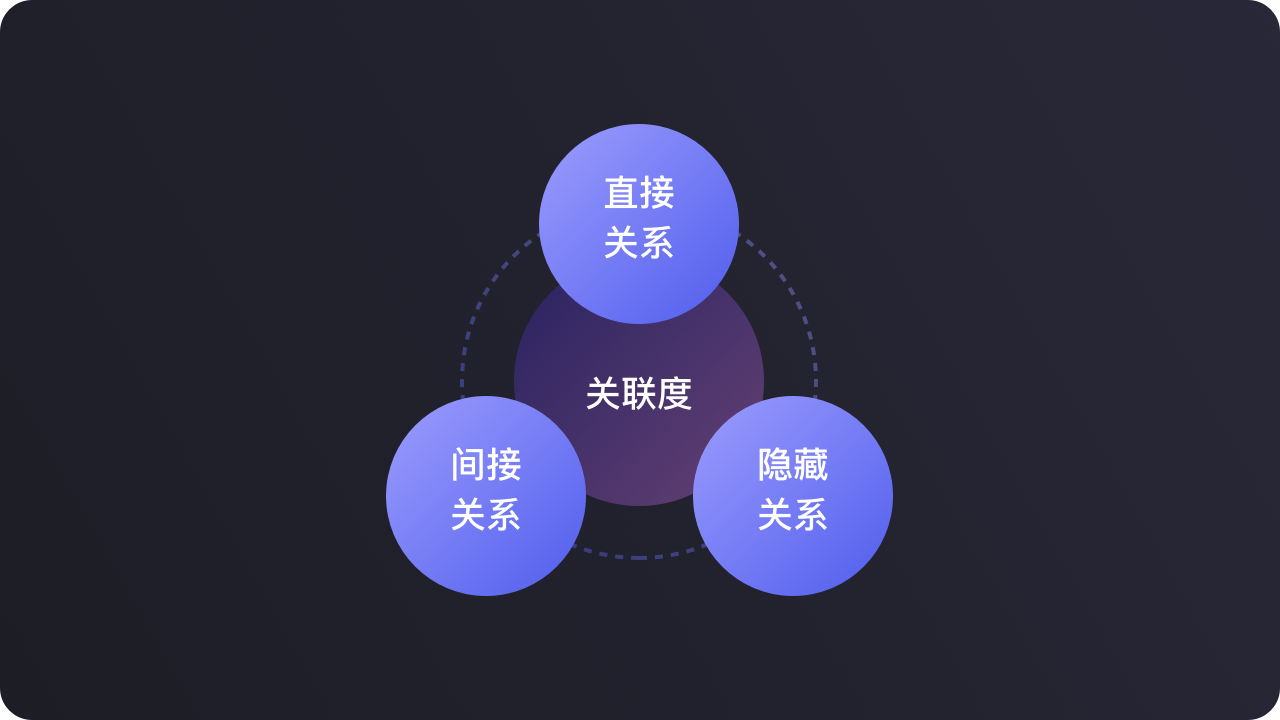
我将信息与信息之间的关系归纳为三个维度的关系:
直接关系、间接关系、隐藏关系
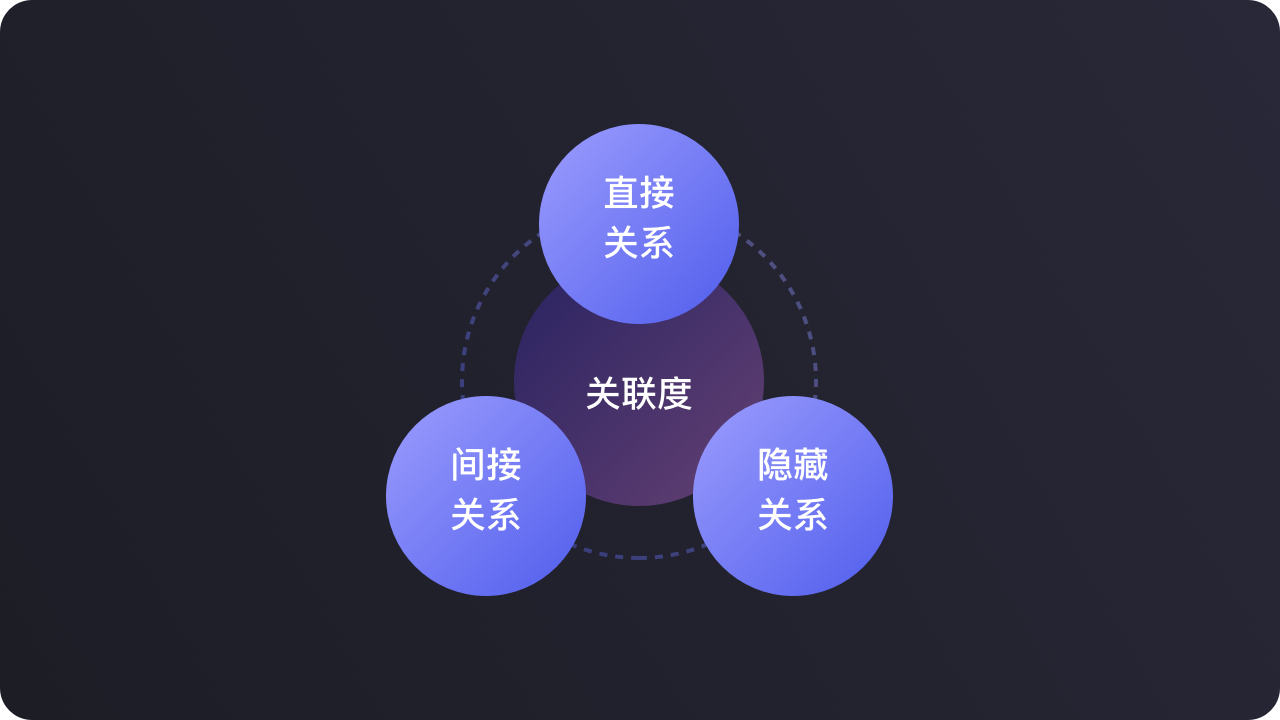
往往深层信息都埋藏在“隐藏关系”里。
通过不同信息关键点的三层关系挖掘,最终我们可以找到很多信息的关联度,这就像下面这张网一样,极大的拓展了原本单一的信息。
例如:通过苹果这个意象
重塑解决最重要的两大关键是:解构与重塑。
接下去我们来具体展开来谈谈如何结构信息与重塑信息。
在我的理解上解构信息做的其实是:整理和关系。
如下图所示,我们可以看到在进行文件夹目录的梳理中,我们通过大模块+细分类的方式将文件目录进行了梳理。
在这个环节做的就是“整理”各个目录分类,将分类处理好了之后,后续的文件就可以按照文件与分类的“关系”放进文件夹目录。
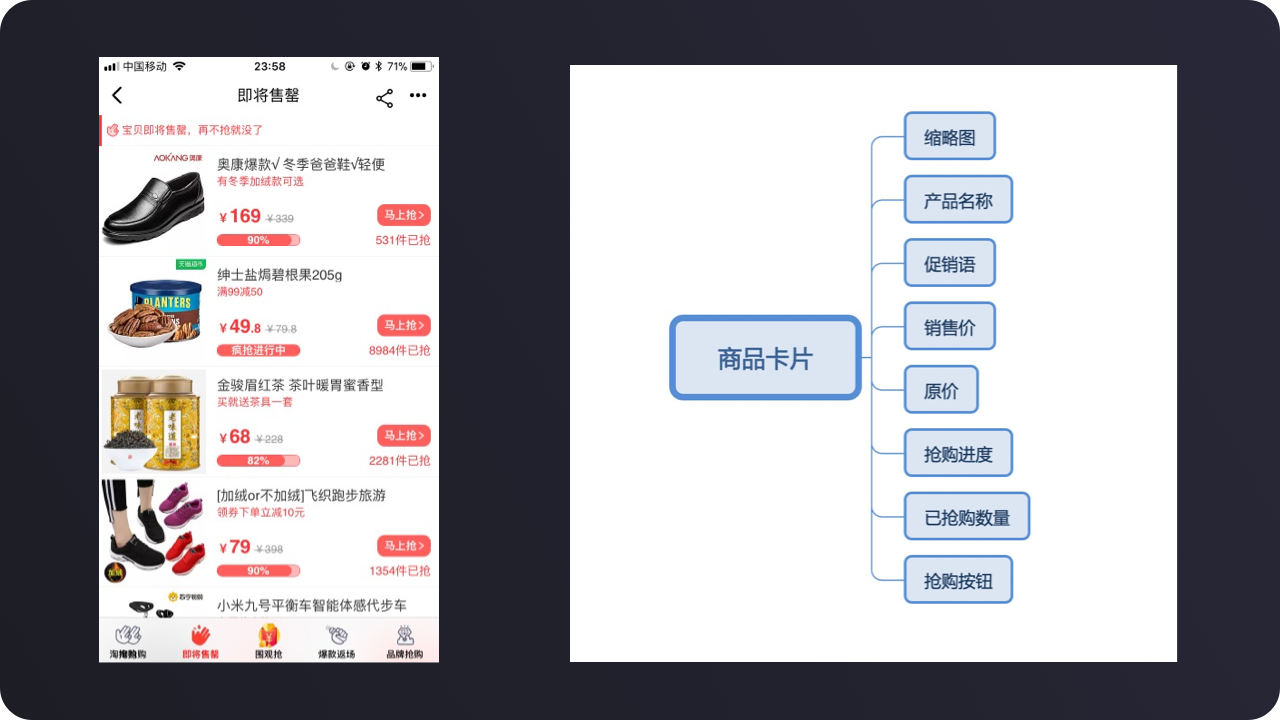
我们再来看一个APP页面的解构信息的案例。
从页面中拆解商品卡片的关键信息。
缩略图、产品名称、促销语、销售价、原价、抢购进度、已抢购数量、抢购按钮。
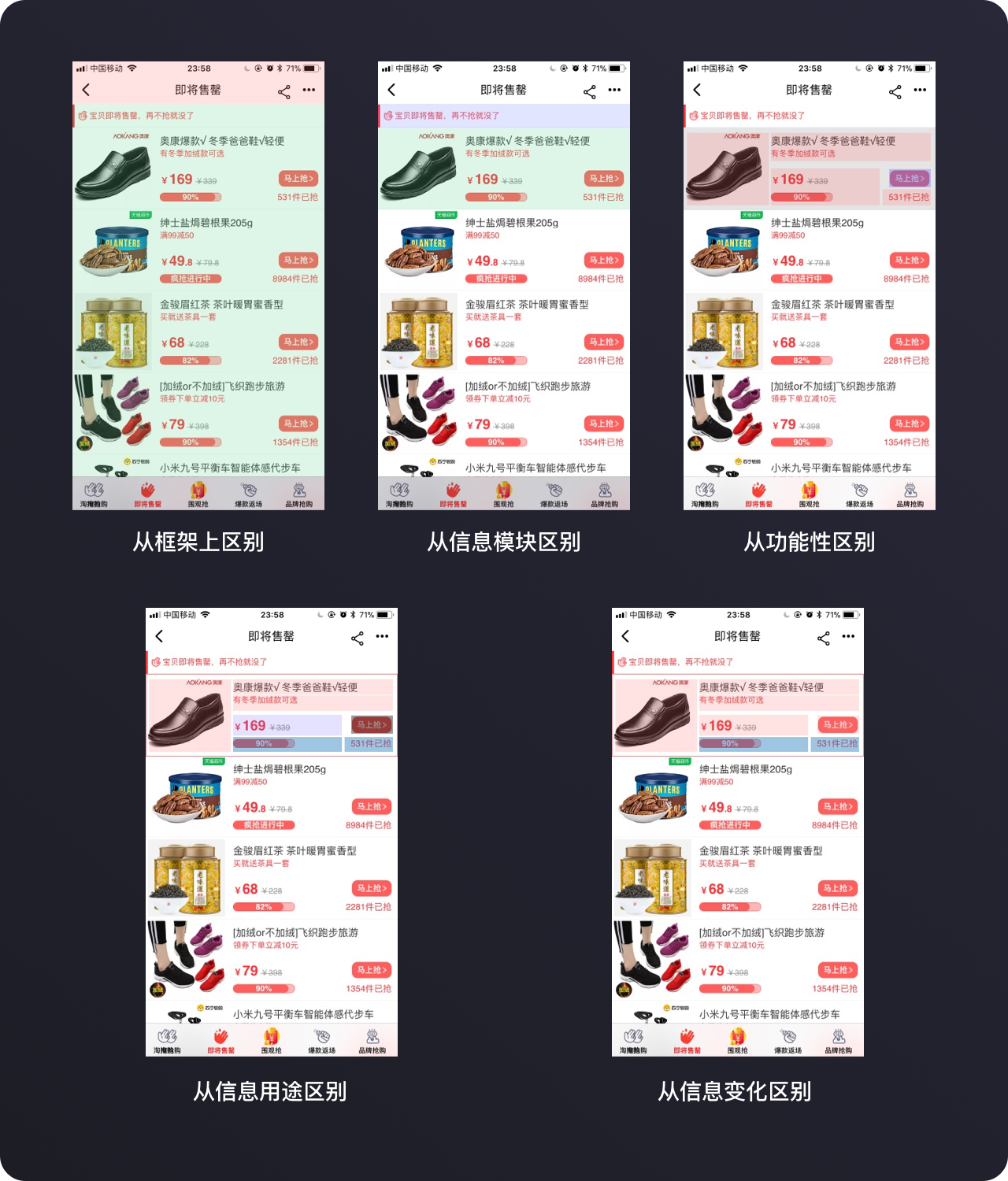
从五个维度去看这个页面,我们可以得出五个信息的关系:
在我的理解上解构信息做的其实是:理解和表达。
1)理解信息的方法:拆解组合

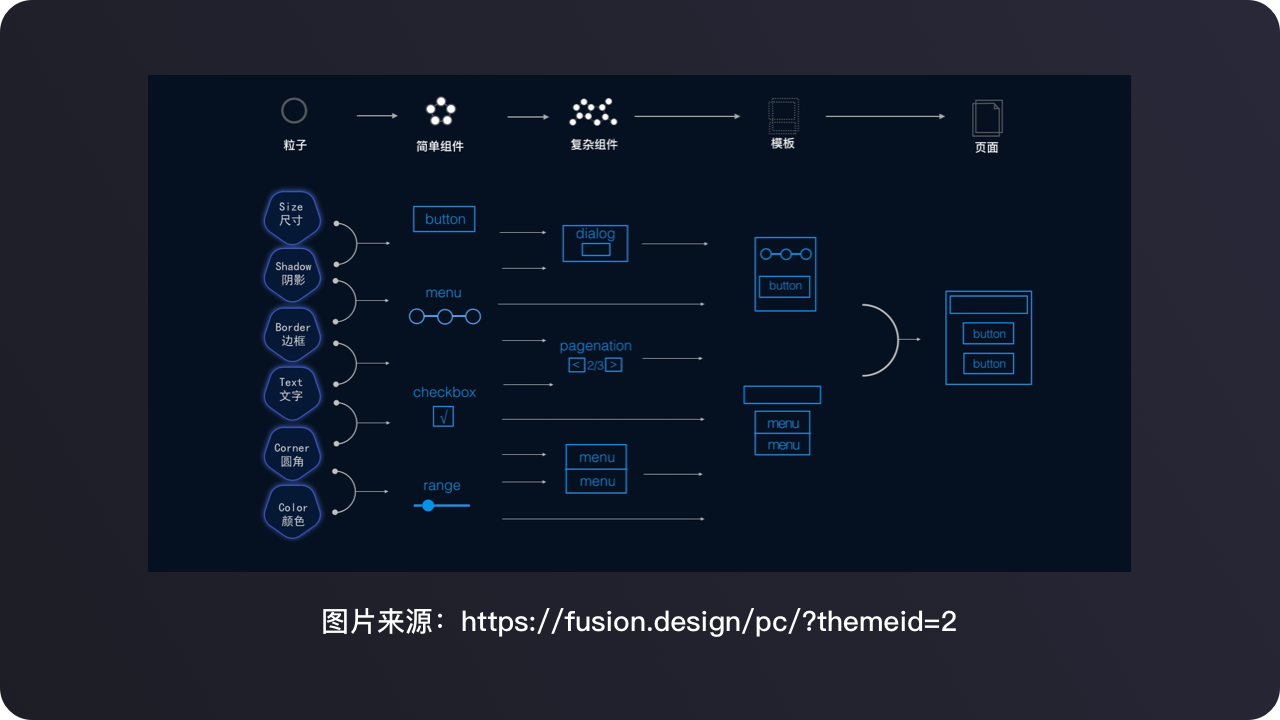
拆——做的是信息的单元拆解。
在我们之前的案例中进行Axure组件化打造时进行的就是信息的拆解,把需要用到的单元组件都拆解出来,作为素材库。
组——做的是信息的单元组合。
当我们拆解得到了组件库之后,在进行新的页面的构建中,使用这些单元组件进行重新组合从而得到全新的页面。
2)表达信息的方法:建立关系
在认知思辨的过程中我们挖掘信息的广度,找寻信息间的关系,而在做信息重塑时,这个过程正好是一个逆向的过程,我们在搭建关键信息间的关系网,让他们彼此更加可靠具有意义。
谢谢大家的观看,到此本次关于高效处理信息的内容分享就到此结束了,希望大家能够从中获取到一点收获。
最后回顾一次:
蓝蓝设计建立了UI设计分享群,每天会分享国内外的一些优秀设计,如果有兴趣的话,可以进入一起成长学习,请扫码ben_lanlan,报下信息,会请您入群。欢迎您加入噢~~希望得到建议咨询、商务合作,也请与我们联系。
分享此文一切功德,皆悉回向给文章原作者及众读者.
免责声明:蓝蓝设计尊重原作者,文章的版权归原作者。如涉及版权问题,请及时与我们取得联系,我们立即更正或删除。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
编辑导语:在产品中,有某些情况是客观存在但却极少出现的,这就是产品中的边缘情况,而边缘情况的发生会影响用户的使用体验,因此产品设计时需要考虑到如何应对边缘情况的发生。本篇文章里,作者就边缘情况的类型、应对策略等方面做了总结,一起来看一下。
作为一名职场中合格的交互设计师或产品经理来说,避免在工作中出现遗漏各种边缘情况的考虑,与规避在方案评审的时候会遭到评审会中其他同学的各种diss的尴尬,是评判交互方案和交互设计师活好不好的重要评判指标。
所以,产品设计方案好赖看产品和交互的能力,产品和交互能力的好赖不得不看边缘情况怎么处理了。
交互设计其实是“向好避坏”并行的设计过程,向好设计是要追求绝对的好,结合实际情况竟可能保证产品体验的舒适和惊喜,这是产品设计一定要为用户的极致体验需要负责的;避坏设计是相对的坏,结合实际情况尽可能为一些低频场景的极端情况做好容错方案和机制,这就是产品设计中常常提到的边缘情况处理设计。
从产品角度来讲,边缘情况是在用户使用APP的时候,极少会出现但是又客观存在的、会极大影响产品使用体验的一些不可控场景,这是区别于需求功能设计的一种隐性问题。
边缘情况的出现往往是和硬件设备、系统、技术和使用环境有强关联的,和产品需求或交互设计本身关联较小,但是也有一些极少的场景,之后我们会给大家举简单的例子作为解释。
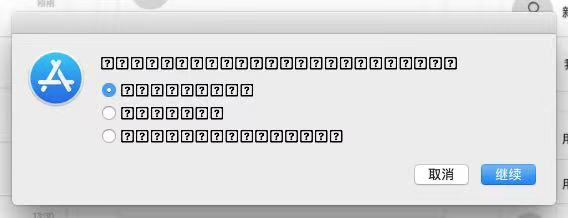
iOS 14 中遇到的边缘情况
对于所有的边缘情况来说,其实,不管哪一种因素导致的不可控的情况发生,作为交互设计师或产品经理来说,我们都可以用严谨的逻辑来将意外的边缘情况预先做出优化处理。
但是通常在产品设计的时候,边缘情况是很难被我们通过设计方法所避免的,同时,边缘情况也会随着网络技术、硬件设备、系统及技术的变化而变化的,而且有时候业内也会将“解决边缘情况问题”的能力作为一个产品经理或交互设计师是否有经验是否资深的一个评判标准。
所以,在日常的工作中,能主动应对或者在输出需求和交互方案时,可以先入为主地考虑和走查自己是否考虑到边缘情况的处理机制就显得格外重要了,这就是区别你和普通产品经理或交互设计师的一个直观评判标准了。

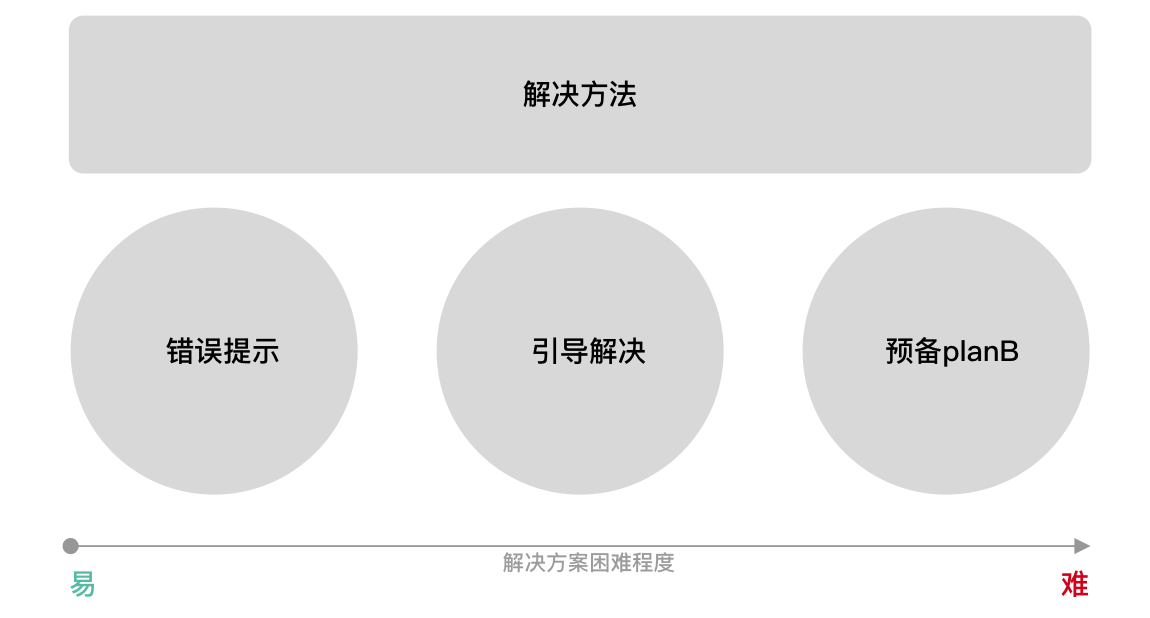
关于边缘情况的解决方案大致可分为3类。
该解决方案是相对研发成本最低的一种处理方法,但是,对于用户来说,体验感是最差的。这类解决方案往往以dialog或toast给予用户错误提示,如下图抖音断网提示:
抖音 v15.4.1
这是遇到边缘情况最常用的一种解决方案,也是一种比较“中庸”的方法,可同时坚顾研发成本和用户体验的平衡,也是对于一些环境主导的边缘情况的最佳解决方案,因为环境主导型的边缘情况有时候只能用户自己解决,APP是没有办法真正避免的。
该类解决方案往往会给出用户具体的解决步骤,如下图微信断网提示:

微信 v8.0.4
该解决方案应该是对用户体验最友好的解决方法了,这就是一种难受自己、满足用户的“自虐行为”,它可以在最大限度不干扰用户的前提下,默默处理掉一些突发的边缘情况而用户却毫不知情,但是这种解决方案就会加大开发成本和损耗研发人员的大量脑细胞了。
这种预先做好planB的处理方法通常用户是对已经出现的边缘情况无感知的,比如微信(v8、v7)的朋友圈评论处理机制,在断网或弱网情况下,用户评论或点赞朋友圈是没有任何断网弱网提示的,这是因为微信将用户操作数据保存到本地,等有网的情况下再次请求数据知道评论或点赞成功为止,这样就很好地避免了打断了用户评论和点赞行为。
蓝蓝设计建立了UI设计分享群,每天会分享国内外的一些优秀设计,如果有兴趣的话,可以进入一起成长学习,请扫码ben_lanlan,报下信息,会请您入群。欢迎您加入噢~~希望得到建议咨询、商务合作,也请与我们联系。
分享此文一切功德,皆悉回向给文章原作者及众读者.
免责声明:蓝蓝设计尊重原作者,文章的版权归原作者。如涉及版权问题,请及时与我们取得联系,我们立即更正或删除。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
每一个设计需求的背后都必然有其商业逻辑在里面,所以在拿到设计需求后,尝试多去问几个为什么。有什么样的商业目标?为什么做这个功能?用户是谁...当你琢磨清楚这些之后,并以此为出发点的设计方案,必然是有据可依、有说服力的,多角度的参与产品设计也更能体现设计师的价值、培养全局观。
商业目标是个大方向,有了目标就会产生解决方案(需求),当然方案可能不只是一种类型(可能是APP、网站、宣传H5或宣传海报等),设计师负责的去做的可能只是其中的一种。
以我参与过的冬奥会某冰雪 APP TAB 栏的 ICON 风格设计为例:
01
业务沟通,商业目标分析,明确设计目标
这个阶段一定要多去沟通、沟通、再沟通,如果是产品公司,那么需要去和产品、研发、市场等多部门沟通;如果是外包项目,那么就需要和客户多次沟通。退而求其次,也要和负责该项目的直属领导多去沟通,以求更精准的了解商业目标,最终明确设计目标,从而为接下来的设计创意设计指明方向。

该项目为二次设计外包项目,着手出图之前,我和该项目负责人、项目小组成员多次深入的讨论了甲方为了什么目的去做?从而确认了商业目标:“传播冰雪文化,激发人们对冬季运动的兴趣和热情”。
这是个大方向,接下来去考虑用什么形式承载,可能是常见的APP、网站、小程序...(这个形式还需要考虑下目标用户的使用习惯)。以及更具体的有哪些内容分类、个性化主题设计、互动形式等。
最终,该项目负责人决定采取安全策略(作为项目负责人,对投入产出比等全局性因素的考量是极其重要的),先做一款内容型APP,内容分类借鉴、提炼几款APP的精华,暂不考虑独创功能。
虽然有时候结果未必和自己期待的一致,但积极去参与的过程是应该的。。

知晓了商业目标和产品内容,接下来就有方向了。我将设计目标定为:将设计与“水凝化冰、冰积成雪”的物理现象相结合,体现冰雪主旨,烘托冬季竞技氛围。

02
创意分析,设计推演
这个阶段重点在于说服力,或许关系到客户是否买单。由于是内容型产品,内容结构上和其它APP并无太大区别,那么客户会不会想:你们是不是抄了一个软件,改了改就发给我了。。基于此,我在设计创意推演前,做了内容分类由来的分析。
人类接受信息的三种方式:视觉、听觉、触觉,对用户传达冰雪文化采用这三种手段,规划APP内容,视觉:图文资讯、视觉画面;听觉:音视频、直播;触觉:榜单、互动等。

借用“水凝化冰,冰积成雪”物理现象,结合基因创意法,对 ICON 进行设计推演,紧扣冰雪主旨。
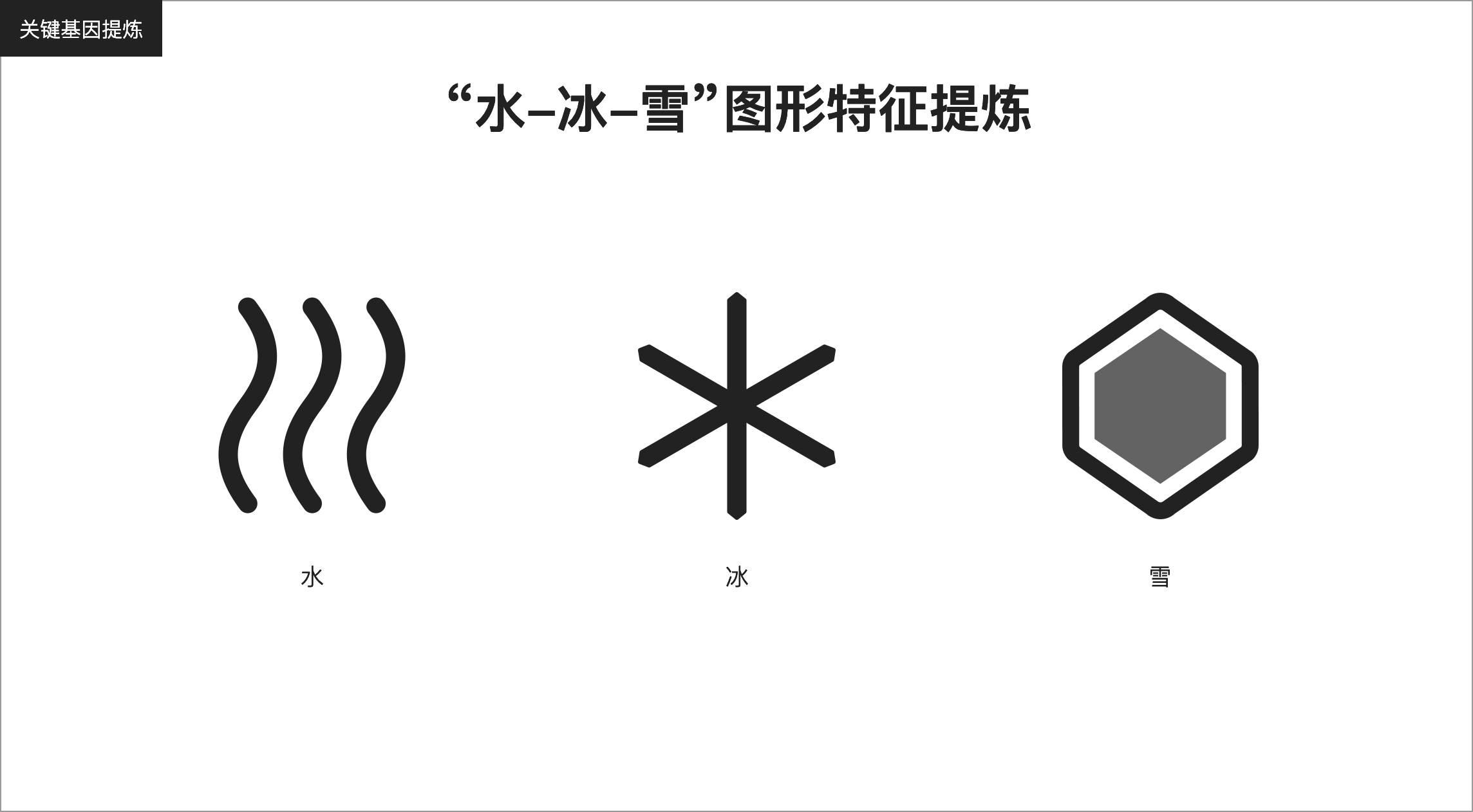
通过品牌LOGO取色法,提炼 ICON 配色。

03
设计执行
到了这个阶段,基本的设计思路应该是比较清晰了,剩下的细节打磨就可以自由发挥了。

至此,一个ICON的设计已完成。该过程的最大价值在于:帮助项目理清了整个项目的核心价值、创意思路与设计提案思路,甚至可以由此推测到未来产品的功能规划方向,当然最重要的是协助项目负责人成功拿下了项目。

蓝蓝设计建立了UI设计分享群,每天会分享国内外的一些优秀设计,如果有兴趣的话,可以进入一起成长学习,请扫码ben_lanlan,报下信息,会请您入群。欢迎您加入噢~~希望得到建议咨询、商务合作,也请与我们联系。
分享此文一切功德,皆悉回向给文章原作者及众读者.
免责声明:蓝蓝设计尊重原作者,文章的版权归原作者。如涉及版权问题,请及时与我们取得联系,我们立即更正或删除。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
一个简单的汉堡菜单就可以包括多种不同的样式,可能有的样式甚至没有官方的名称,但因为样式的差异在功能上这些菜单也会出现差异性。
我们可以通过分析这些样式,来思考不同的样式代表着怎样的设计含义和设计目的,不能因为简单常见而忽视了功能的内核。

关键词:横条、多个菜单选项
这个图标的样式简洁易懂,通常位于网页和 App 的上下角,用来告知用户这个按钮之外还有更多内容可以探索。
当产品有多个菜单选项时,考虑使用汉堡图标来显示,但尽可能避免在桌面视图中使用。

关键词:垂直、内嵌菜单
通常位于屏幕或窗口的右上角或顶部,是用于打开带有附加选项的图标,打开的内容往往是一个较小的内嵌菜单而不是整个全新的页面。

关键词:水平、内嵌菜单、web
水平三点式菜单同样常位于屏幕或窗口的右上角,用于打开菜单或显示相关项的操作。
因为图标样式是水平的,所以更容易在 web 上或者在表格等水平方向中使用。

关键词:子分类、子功能
九宫格菜单通常用于打开同一产品中包含不同子产品或子功能,可以在它们之间快速切换,此图标常位于产品主页的右上角。

关键词:过滤、排序
过滤式菜单由三行不同长度的线段水平叠放而成,是最广泛使用的过滤符号。可以将过滤式菜单与“排序方式”选项结合使用,或者与全局过滤器结合使用。

关键词:样式特殊、时尚感更强
作为汉堡图标的替代品,与显示列表菜单的目的相同吗,但是这些样式我们平常见的可能会比较少,更常用在充满现代感、时尚感和艺术感的网站上。

不同的样式可能代表着截然不同的设计目的,常思考这些小而精的细节,是保证产品体验提升的关键。
蓝蓝设计建立了UI设计分享群,每天会分享国内外的一些优秀设计,如果有兴趣的话,可以进入一起成长学习,请扫码ben_lanlan,报下信息,会请您入群。欢迎您加入噢~~希望得到建议咨询、商务合作,也请与我们联系。
分享此文一切功德,皆悉回向给文章原作者及众读者.
免责声明:蓝蓝设计尊重原作者,文章的版权归原作者。如涉及版权问题,请及时与我们取得联系,我们立即更正或删除。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务

大部分客户都是很挑剔的,所以一稿过是很多设计师的梦想,其实客户也不是刻意要刁难设计师,如果你的设计方案能够把设计需求展现出来,同时还有一套正确的设计逻辑,那么客户也是很容易被说服的。这篇文章总结了让客户埋单的设计思路:

设计师面对的客户千奇百怪,以设计师自身对于审美和需求的理解往往容易产生误解和矛盾,那么要怎么了解客户的审美以及深层的需求?看看高手是怎么做的:

改稿绝对算得上是设计师的一项日常操作,这一点我们都深有体会,至于改稿的原因则五花八门,不是客户嫌弃太小气、没创意,就是上级嫌弃太土、太单薄等等。可是大气的设计可不仅仅是 LOGO 要大、字要大、图要大,那么真正的大气要怎么做呢?看这个:

很多同学可能都碰到过一个很头疼的问题,比如来公司时间不短了,但是在公司毫无话语权可言,不论是所在团队还是业务方,甚至连对接的开发,都可以对他的设计稿提出质疑。而且总是无法顺利得说服对方,导致无穷无尽得改改改。那么这个问题要怎么解决呢?这个套路一定要了解:

酸梅干超人的新系列文章来了!这次,他要输出一部完整的 UI 零基础学习指南,根据 UI 新手系统学习 UI 设计的顺序,陆续会输出 12-15 篇不同模块的系列性文章,而这篇是这个系列的第一篇:

在如今的产品设计团队中,体验设计师需要做的事情已经跨越了职能边界,为了寻求更好的设计方案,常常要承上启下地连接整个团队。这篇文章将设计流程中定义问题、创意发散、原型 & 测试、复盘反思四大设计流程细化为 12 个步骤,详细讲述了每个步骤用户体验设计师涉及的职能任务和思考:

很多人对 APP 中的卡片设计习以为常,但对于卡片设计流行的原因、优点,以及如何做好卡片设计却可能不甚了解。这篇国外大佬写的文章,算是从为什么这样做的角度来分析卡片设计,一起来学习吧:

这篇文章出自资深 B端设计师 Taras Bakusevych,他深耕 B端设计多年,对于表单、可视化设计、UI/UX 都有着丰富的经验。这篇梳理了 20 个可视化设计的常见技巧,实用性和指向性都非常强:

当下移动 APP 产品缺少对老年人体验的深层次关注与设计,只通过单一加大字号与简化功能等解决基础体验,缺乏通过新技术应用和更全面的适老化设计服务老年群体,老年人的需求依旧未得到关注和满足。百度基于自身的 AI 技术和精细、系统的适老化设计,适时推出百度大字版,使老年人更平等地获取信息和服务、获得情感陪伴:

怎么样的交互说明才是最好的,是大家都喜欢的?这个问题想必很多同学都想知道,因为不少同学将写的交互说明文档提交给需求评审会的成员审核时,总会碰到「写的更合理些」的建议,这确实让人透了脑筋。来看看高手是怎么解决问题的吧:

移动互联网在悄然改变着用户的社交方式和社交需求,这篇文章根据近一两年技术创新和用户代际更迭导致的用户需求差异化,来探索社交的设计趋势,帮助我们应对变幻莫测的互联网:

蓝蓝设计建立了UI设计分享群,每天会分享国内外的一些优秀设计,如果有兴趣的话,可以进入一起成长学习,请扫码ben_lanlan,报下信息,会请您入群。欢迎您加入噢~~希望得到建议咨询、商务合作,也请与我们联系。
分享此文一切功德,皆悉回向给文章原作者及众读者.
免责声明:蓝蓝设计尊重原作者,文章的版权归原作者。如涉及版权问题,请及时与我们取得联系,我们立即更正或删除。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
最近在使用vue el-date-picker时间控件,发现直接获取的时间是日期格式,而我需要的格式是
yyyy-MM-dd HH:mm
那么如何转换时间控件格式呢
<el-date-picker
v-model="selectDatetime"
type="datetime" placeholder="选择时间"
@change="dataSearch" value-format="yyyy-MM-dd HH:mm"
format="yyyy-MM-dd HH:mm"> </el-date-picker>
在日期控件中,加入上述加粗格式即可
分享此文一切功德,皆悉回向给文章原作者及众读者.
免责声明:蓝蓝设计尊重原作者,文章的版权归原作者。如涉及版权问题,请及时与我们取得联系,我们立即更正或删除。
来源:csdn
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Todolist</title>
<script src="./js/vue.js"></script>
</head>
<body>
<div id="app">
{{msg}}
<div>
<input v-model="txtValue">
<button type="button" @click="handleSubmit">提交</button>
<ul>
<li v-for="(item,index) of list"
:key="index"
:index="index" @click="deleteItem(index)" //传递下标值 >
{{item}}
</li>
</ul>
</div>
</div>
<script>
new Vue({
el: '#app',
data: {
msg: 'hello Vue!!',
txtValue: '',
list: []
},
methods: {
handleSubmit: function () {
this.list.push(this.txtValue)
this.txtValue =''
},
deleteItem: function (index) {
//alert(index)
this.list.splice(index,1) //通过下标删除 }
}
})
</script>
</body>
</html>
分享此文一切功德,皆悉回向给文章原作者及众读者.
免责声明:蓝蓝设计尊重原作者,文章的版权归原作者。如涉及版权问题,请及时与我们取得联系,我们立即更正或删除。
来源:csdn
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
蓝蓝设计的小编 http://www.lanlanwork.com