

做项目的时候准备把js项目重构成ts项目,需要把文件后缀改成ts,一个bat脚本搞定,命令如下:
@echo off
rem 正在搜索...
for /f "delims=" %%i in ('dir /b /a-d /s "*.js"') do ren "%%i" "%%~ni.ts" rem 搜索完毕 @pause把脚本放到根目录下,双击运行完就可以了
最近正火的新拟物化风格(Neumorphism)在 2019 年底,设计师 Alexander Plyuto 所提出的「Skeuomorph Mobile Banking」作品中亮相。之后不仅被选为 2020 年界面趋势,又称为 soft UI。但这种风格在真实世界落地时,可视性上受到许多争议。
确实,新拟物化风格它算是一种风格,但又不是只有视觉上的风格这么简单,它延伸出来的议题,其实是扁平化跟拟物化之间的战争。
拟物化是 Apple 在早期设计中大量使用在界面上呈现对象属性、材质的方式。然而在 2013 年 ios7 发布时,Apple 开始为了画面简洁大量将界面元素扁平化,紧接着 Google 在 2015 年发布了 Material Design,宣示扁平化在 UI 设计中扮演着主导趋势的角色。2020 年真是百家争鸣的一年,首先是 BMW 发表的扁平化新 logo,接着是这一波新拟物化的反击。究竟代表新拟物化可能夺回界面风格主导权?或仅是 2020 年昙花一现的视觉风格呢?
我认为新拟物化的概念其实是融合扁平化与拟物化的集大成,它建立在扁平化风格之上,又将组件带入了拟物化的元素,提高用户的判断力。不过在纠结于扁平化与拟物化哪个比较好时,有五个议题是可以让 UI、UX 设计师去思考的。
大家身边一定都有那种已经把 Line 操作得滚瓜烂熟,但是每次要用 Line 加好友时,还是不知道怎么操作的长辈。最早期当人类还没进入屏幕时代前,我们所使用的界面大多是实体产品上的控制界面,而这些界面上的每个开关、按钮,都只有一个输入源,对应到一个功能(一对一),我们因此就这样与产品进行简单的交互动作。然而在屏幕上这个简单的交互模式被改变了,像是用键盘跟鼠标可以辅助我们,在系统中进行抽象与复杂的无限多任务(一对多)。

△ 你偏好用哪个微波炉加热咖啡呢?Image credit:Bence Mózer
让我们再来看看对长辈最重要的 Line 加好友功能,我们先不论这个功能在整个 APP 中被埋得多深,因为找到加好友的入口真的对长辈来说是看缘分~
在我引导长辈找出二维码画面的经验中,发现他们都是用死记的方式,把下一步要按哪个键、在画面的哪一个角落,记下来。但由于加好友功能并不是每天都会操作的,因此在学习上的效果,就像是高中时没有把课文理解、吸收就硬死背下来一样困难。
我们来看看「显示行动条码」在扫描二维码画面中,是否真的具有可以被点选的暗示。在扫描画面背景单纯的时候(如下图情况 1),「显示行动条码」的 button 底色是有透明度的黑、扁平化后没有阴影提供可以按的暗示,不过因为有大圆角的造型,勉强还是可以诱使人点点看;但一般情况下,扫面画面背景不会那么理想的无其他干扰(如下图情况2),button 原本的透明黑完全融入了后面的背景,这时候只剩下「显示行动条码」的文字,已经不具备可以被点选的提示。

△ 情况 2 中,显示行动条码的 button 看起来可以按吗?
扫描画面中的外框有一定的透明度,在可操作暗示(affordance)上已经不具有实体的特征,如果又放上有透明度的 button 在上面,让人充满不确定性,年长者无法将这样的情况与现实生活中的经验联想在一起。
你知道同一个颜色,每个人看起来会不一样吗?而不同颜色在不同环境下,却又能看起来像同一个颜色吗?
不同意新拟物化设计的人中,有人主张运用颜色的引导用户操作界面的色彩元素不能从界面设计中抽离。但事实上,不同年龄、性别,视觉锥细胞中的活跃程度不一样。同一个颜色,不同人看,明度跟彩度会有差异。基于种种现实,由色彩的引导是好还是坏呢?
例子1:关于人类的视觉锥细胞
同一个颜色,不同人居然会看成不同颜色?

为什么阿嬷喜欢买大红大紫的衣服?这个偏好除了受到个人喜好影响外,也关系到阿嬷视觉锥细胞的活跃度。老年人在上了年纪后,部分视觉锥细胞开始退化,因此对于蓝色、绿色这类冷色系的颜色,老年人会开始接受不到这个区段的光带来的刺激。因为视觉锥细胞对冷色系的刺激降低,导致阿嬷在菜市场逛街时会被偏暖色系的物品吸引。所以会买热情系服饰不是阿嬷本人的意图,而是老化的锥细胞在作祟。
例子2:关于学习观察颜色这件事
不同颜色居然看成同一个颜色?
不同颜色却看起来很像,有可能是光线造成,也有可能是使用者必须学习去观察才知道的。日本的 JR 跟 Metro 系统,有着完整且细腻的视觉辨识系统。设计师理想中的情况是,我们将每条路线定义成不同颜色,可以让使用者更容易学习辨识路线。

但实地走访过东京的地下铁跟 JR,常常会发现跟错指示,才发现是潜意识辨认错文字或是颜色。我自己遇到过的经验是,在新宿站想要找都营大江户线时,因为在改札口看到了同样粉红色的标志,原本已经要哔卡进去,才发现那是京王新线的 IC 入口标志。

△ 新宿驶的改札口前,有两个同为粉红色的引导指标
所以说,高龄者或是天生视觉锥细胞有缺陷的人对于颜色无法清楚辨认外;大部分人可以借由学习来增强色彩辨识,除了可以对相似颜色进行更细节的判别外,也可以学着辨认不同光线(暖光、冷光)下造成的色彩差异。
但是,当我们在设计中,迫使用户学习、习惯我们制定颜色的意义。可能会在新手 onboarding 时造成适应上的负担,也有可能让他们在使用别的系统造成错乱。
在不同文化之下,对于色彩的观察与运用也不一样,举个大家可能都有发现的例子,当你在不同城市旅游的时候,有没有发现不同城市的优先座颜色不一样?你能猜得出来,哪一个是台北捷运上优先座的颜色吗?

△ Image credit:wikipedia.org
当颜色在不同约定成俗下,有不一样的意义,又刚好缺乏文字或图像引导的时候,可能会让使用者解读成不同的意义。例如:红色具有热情、喜气、带来财运的意涵,但同时又具有危险的警示意义。
当设计师觉得红色可以引起使用者的注意,而把 button 设计为红色时,却可能让没看清楚文字的用户,认为按下这个 button 是危险的举动。

△ Image credit:photoAC
新拟物化设计中假设了人在使用界面时,会运用与生俱来能判断光影效果的能力。这是真的吗?让我们来做个小实验:
为什么在台北车大厅席地而坐的人,会选择坐在黑色的棋盘格上呢?如果根据人类从大自然中所得到的可操作暗示来说,有阴影的地方可以提供人类休憩的功能,例如树阴下的阴影处。

△ Image credit:中央社、wikipedia.org
如果这样说得通的话,代表光亮的区域对人来说是可以行走、活动的地方;而阴影处则是休息与暂停处。
根据以上的推测,我们做个小实验,把车站中的 2 个不同区域的地面上分别涂上白色与黑色,来让受测者选出哪些区域可以暂停,哪些区域可以走动:
问题A:假设你要在车站的大厅等朋友,你会选择站在哪里等他呢?
假设:受测者会选 2,因黑色区域(影子)让人觉得可以暂停、休憩。

结果:符合假设
1:白色柱子前的白地面 32.5%; 2:白色柱子前的黑地面 67.5%
问题B:哪一边的楼梯是往上的方向呢?
假设:大家会选 1,因为黑色区域(影子)让人觉得可以踩上去。

结果:符合假设
1:白色立面+黑色地面 61.3%;2:黑色立面+白色地面 37.8%
由实验A、B可得证,虽然实验结果符合先前假设,大多数的受测者可从阴影判断要走哪条路,但还是有不少(30%以上)的受测者不认同。所以在用使用光亮阴影的设计暗示时,还是会遇到使用者感知的不同的问题。
新拟物化设计中,将界面组件以类 3D 的方式呈现,使用户在操作界面时必须去感知界面组件的远近以判断重要性,而在深度认知上有障碍的用户此时就会受到挑战。用户可能会遇到,不知道哪个组件才是浮在最上面、最重要的;若界面中的组件有三种以上的阴影深浅,会让用户在判断时要更花脑力判定物件在立体空间中的深浅。
新拟物化风格中的光影表现提供了使用者人类最原始的操作意图:可操作暗示,是一个好的出发点,然而必须针对 APP 性质的不同而有所改良。在设计较走生活风格理念,而操作界面不复杂的 APP 时,非常适合用新拟物化风格来诠释:例如电子书服务、音乐软件;但在设计功能导向,且有大量信息化图表的界面,例如:移动网银,还是需要以扁平化的界面为主要信息架构,新拟物风格可能会是极少量界面元素中,拿来呈现生活中真实物的质感(例如:用户的信用卡)、或是作为亮点(例如:优惠卡片)的呈现方式,此类型 APP 中最重要的卡片与图表对于此种风格,一定要谨慎使用,必定三思三思再三思。
文章来源:优设 作者:Muse Chang
可能对于一些人来说,流利说是一份工作,而对于我来说,流利说却是一段深刻的旅程,改变了我的生活,也塑造了我的性情、人格。从 2013 年作为第 7 号员工加入流利说,为之效力6年,从最早期民房创业,到纳斯达克 IPO,这段经历,我自认为颇具一个理想主义者的传奇色彩,有些故事,是我愿意,也值得分享的。
老王(流利说 CEO 王翌)以前总借他恩师的话说,人这一辈子能做一两件漂亮事就不错了。我觉得,流利说,算我过去做的一件漂亮事。以前,我也常和同事说,如果你现在一切的经历,在日后不足以用故事说与人听,可能你现在经历的还不够痛,你还不够刻苦。所幸,过去的经历,给我留下了几个故事。
这一次,我想分享当初选择加入流利说的故事,分享这个过程中我的思考、行动。一方面,单纯的想记录这段故事。因为随着年岁增加,记性却是退减的。文字是最好的保存记忆的方式;另一方面,常常遇到设计师朋友们聊如何选择工作机会,遇到创业的邀约机会怎么判断、决策的问题,我希望这个故事,能给遇到此类问题的朋友一些启发。
好,听故事吧。

2012 年,我退出了联合创立一年半的公司。而在一年半以前,我从阿里云公司离开,放弃了一笔可观的 RSU 股票,当时,我是阿里云最早的 28 位设计师之一。结束创业后,2012 年 11 月 14 日 19:17,我发了一条微博,表示想看看新的机会。这条微博,有 16 个转发。其中有 1 个转发,被流利说联合创始人 Ben 看到,他把这条微博转发给了联合创始人王翌(流利说 CEO)。
在此之前,我和 Ben、王翌素不相识,网友都谈不上。Ben 之所以看到那条转发,是因为他关注好友里面,有一位正是我一款浏览器插件产品 – 微博急简 的用户。

△ 使用「微博急简」前后,微博主页的对比
容我多说几句,介绍一下微博急简这款产品。2011 年左右,新浪微博的使用体验,非常糟糕,逐步商业化带来的各种广告,让原本不好的体验,变得更加让我无法容忍。很快,一个叫 stylish 的 Chrome 插件工具,在微博设计/技术圈子里流传。用户安装 stylish 插件后,通过修改 CSS 来定制自己的微博体验。同时,你还可以把 CSS 分享给其他用户。
这太好玩了!我按自己的使用喜好,给自己订制了一套极简体验的新浪微博。玩了几天后,我决定做一个改善微博体验的浏览器插件。为什么要重新做一个插件呢?我认为,stylish 的使用门槛、操作成本都太高,仅仅是专业人士的玩具。我希望普通人,也可以通过一键安装浏览器插件,获得舒服的微博体验。因此,我给插件取名 – 微博急简。看得出来,我是多么急迫的想简化微博的体验。

两周后,微博急简就上线了。几个版本后,体验就趋于稳定。高峰的时候,有 10 万左右的用户使用,相关微博话题有 600 万。有很多行业内的大咖成为我的用户,像冯大辉、少楠、方军等。获得了很多用户的好评,最让我嘚瑟的是现任丁香园产品总监少楠的评价:用一个插件秒杀了新浪UED团队。
通过微博急简这个产品,我想分享以下几点:
这三点,既是我的观点,也是我的特质。正是因为这样的特质,才遇到后面加入流利说的契机。
回到故事主线。
我发完那条微博后的 1 小时,王翌就给了我微博私信。老实说,今天是我第一次注意到这个「相隔 1 小时」的时间细节。王翌的行动力、执行力,对于人才的执着追求,着实让我佩服。这不仅仅是对我,对流利说早期的员工,以及后面的核心员工,都是如此。

他的消息里,有三个关键词:exciting、团队成立 2 个月、移动教育。对于这条消息,我礼貌的回应,但内心其实是「呵呵」的。即使,我看到他 LinkedIn 主页上 Google PM 的经历,很亮眼。呵呵的原因是,这个公司太早期了,才两个月。2013 年,移动教育是啥东西?而且,创始人还这么不务实,动不动就标榜是一个 exciting 的机会。
虽然,王翌后续一直联系我,但我基本是忽略的状态。期间,我短暂的加入了一个朋友的创业公司。2013 年 1 月底,春节前的几天,我再次收到王翌的私信:流利说 App 即将上架,想约我再聊一聊。于是,我们约在文二西路白鸦(有赞创始人)的贝塔咖啡。

△ 贝塔咖啡馆
那天晚上,王翌给我展示了流利说最早的 App,程序其实还不太稳定。但他仍旧极具信心的表达了对于语音互动的看好,以及发出盛情邀请。我对这个 App 的产品与交互的第一印象,是好的,但对于王翌的第一印象却是复杂的,既觉得这人有激情、有想法,同时又觉得不太靠得住,夸夸其谈,他太会说了。
深色模式该从何处着手设计又要考虑哪些因素?一起来看看~
其实回顾我们常用的APP,有很多都更新了深色模式,而且每个APP对深色的定义和设计都有差异。

实际上深色模式已经来临,而且在很多产品中都能发现它的身影,之后也会愈加流行。那么设计师面对深色模式,该从何处着手设计又要考虑哪些因素呢?
本文就为大家提供一份全面的总结。文章目录如下:

1. 需求趋势
过去一年以来,Android 10和iOS 13上都适配了深色模式,而且Apple和Google也一直致力于将资源和注意力投入到深色模式中,这也让深色模式备受用户的关注。

2. 专注内容
深色模式在弱光环境下具有更好的可读性,让我们更专注于眼前的屏幕。同时深色的背景会降低内容周围元素的影响,特别是以图片和视频为主的应用,让用户更专注于内容。
作为内容消费型应用的Netflix ,把深色背景作为默认设计样式,深色的设计让用户更能集中注意力,延长使用时间。

3. 减轻刺激
相对于其他颜色,深色系的设计在夜晚看着最舒服。可能晚上玩手机不用担心光线太刺眼,但是深色模式对护眼并没有什么帮助,只能说可以减少对眼睛的刺激。
4. 提高续航
深色模式更省电只适用于OLED屏幕。OLED面板的每个像素点可以单独发光,当使用深色模式时,部分像素点被熄灭,只点亮部分像素,屏幕的一部分相当于处在休眠状态,所以会更加省电。
在深色模式下,Apple重新审视了iOS中UI样式和颜色的含义,让我们来看看在iOS上设计深色模式带来的变化。
语义化颜色(Semantic Colors)
所谓语义化颜色,就是不再通过某一固定的RGB色值来描述颜色,而是根据用途来描述,让界面元素可以自动适配当前的外观模式。

淘宝团队就参考了苹果官方的适配建议,通过语义化颜色的方式进行适配,使适配成本大幅降低。设计师根据不同UI元素的特性先期制定颜色语义化规则,进而技术在框架层面通过「颜色自动反转」技术实现颜色反转。

系统颜色
除了语义化颜色,Apple还提供了9种预定义的系统颜色,在浅色和深色模式中,这些颜色会动态变化,支持整个系统的外观,同样也可以自适应选定的界面样式。

模糊与动态效果
在iOS13上,苹果引入了4种模糊效果和8种动态效果,它们自动适应iOS界面样式。这是在浅色和深色模式下不同的模糊效果。

苹果还在iOS深色模式排版套件中引入4种动态效果,其中3种为叠加效果,1种分隔效果。

谷歌提供了广泛的文档支持,帮助设计师了解深色主题如何在Android生态系统中运行。
Elevation(阴影)
UI界面元素间的投影最能让用户清晰地感知用户界面的深度。在设计深色主题时,组件将保留与浅色主题相同的默认阴影组件。Elevation越靠上, 颜色就会越浅。

无障碍性与对比
深色UI设计中的背景应足够暗以显示白色文本。设计师要注意背景和文字之间至少使用15.8:1的对比度。这样可以确保将正文放在最前面时,能通过WCAG(Web内容无障碍指南,使网站内容更容易访问)的AA标准。

颜色
深色模式必须避免饱和的颜色,以免引起眼睛疲劳。相反,设计师应专注于使用不饱和的颜色,以增加清晰度。主色和辅色的选择还取决于对浅色和深色UI主题的考虑。

文字不透明度
在深色背景上设计浅色文字时,高度强调的文字不透明度为87%;一般提示文字的不透明度为60%;禁用文字的不透明度为38%。

苹果和谷歌都利用各自的设计原则,为深色模式设计做准备工作。在实际设计过程中,不单需要这些基本原则,更重要的是要注意设计深色模式的实用要点。
设计深色背景时不是简单的把白变成黑,而是对背景使用比较暗的色调,以减少眼睛疲劳。
在浅色模式中,我们倾向于用细微的阴影来传达界面深度,使用起来更加自然。但是在大多数深色模式下,阴影的效果并不明显,通常用颜色的深浅来传达界面的层级关系。

关键点:注意应用场景
在知乎的深色模式中,背景的设计从深到浅使用了三级灰度,让页面的层级更分明。
一级灰度的应用场景主要是大的背景色,使用面积相对比较大颜色最深;二级灰度的应用场景是选项的背景色,根据选项的数量设置使用面积,位置排布比较灵活;三级灰度的颜色最浅,使用面积最小,通常用在分割线中。
白底黑字和黑底白字带给我们的用眼体验是不一样的。设计不当的深色模式常常因为强对比而变得很刺眼,同时为了提高对光线的吸收虹膜会张得更开,更容易造成眼部疲劳。

关键点:文字间的对比
深色模式中,文字的用色通常是纯灰色,不同位置的文字例如标题、正文和注释使用深浅不同的颜色作对比。上图是深色的微信,就利用这种方法来区分不同文字内容,展示文字层次关系。
另外每个应用的定位都不一样,界面中想传达的信息也有差异,所以要注意不同的设计思路。

关键点:文字与背景的对比
已经更新深色模式的应用主要分为两大类,一类属于工具型应用例如QQ、微信、百度网盘等,这类应用追求的是信息的有效传达,在设计时文字内容和背景色的区分比较明显。
上图是百度网盘的深色模式,可以看出来标题文字与背景有很明显的对比,保障了用户使用时的可操作性和易读性。
这样的设计不需要用户过于沉浸式的阅读,只需要帮助用户快速找到有用的信息并方便使用,这是工具型应用在设计深色模式时必备的原则。

另一类属于内容型应用例如知乎、简书等,这些应用更注重沉浸式的阅读体验,因为用户通常会在某个界面中停留很久来查看内容,所以需要文字与背景的低对比度为阅读营造柔和的氛围。
简书的深色模式中,文字与背景的对比关系就设计得很弱,整个界面呈现出灰色调,这样的设计有助于在弱光环境下的长时间阅读和浏览。
深色模式应该避免使用特别鲜艳的颜色,较高的明度和饱和度会与深色背景形成强烈的对比,让页面的可读性变差并加深刺激。

关键点:降低色彩明度
在由浅变深的过程中,知乎对改变了界面中所有图标的颜色。界面里面的图标和主题按钮的色彩,在色相、饱和度上都没有变化,但是明度被不同程度的降低,保证了在不同光照条件下的内容的可读性。
这是深色模式中处理色彩的一种方法,虽然在浅色界面中,我们更喜欢鲜艳的颜色,但明度低的颜色更适合深色主题。匹配这两个模式另一个比较好的方法是创建互补的色板。
无论深色或者浅色,都只是产品向用户呈现的一种界面状态,最终的目的是为了更良好的使用体验。
不管选择什么样的模式,都要记得从产品自身出发,并牢记这几点:
文章来源:优设 作者:Clip设计夹
蓝蓝设计 魏华写
在承担ui设计项目中,常常碰到一些客户不给设计师看己往的软件或本公司设计师设计但没有被客户认可的设计方案,怕限制设计师的思路。那究竟给设计师参考会不会限制设计师的思维呢?
实际上不会的,这是更多维度了解客户的思考和角度,排除己被尝试过的选项。
在进行一个ui 设计前,深度方面应该要了解业务,用户角色,环境生态,交互流程,关键功能,核心价值,用户体验的峰值点和难点在哪里…….总之了解的越深越好。
宽度方面,要看到竞品分析,行业趋势,国内外优秀案例欣赏,专业文章观点,应该是可以拓展设计师的思维。
设计最核心的目标应该在于解决问题,而不是单纯的让界面好看。
优秀的设计师要明确解决问题的目标,博采众长,独立思考,看众多的竞品是看众多的解题思路,多方位角度看问题。各产品资源,核心技术不同,取舍不同,理解信息架框,运营思路,用户特征,技术实现可能性,不会只照着您给的资料比猫画虎。
因此,我认为,放心的给设计师参考资料吧,互相的了解,沟通越多,越容易出好的作品。
这五张图是最近蓝蓝设计的稿件,展现从一个模糊的概念性需求到一个可视化概念性方案的设计过程。





关于循环设计,可持续发展是商业领域非常关注的话题,作为UX需提前转变思维,给企业带来更多价值,一线大厂已在运用这种思维

本文共 3589 字,预计阅读 10 分钟
译者推荐|本文从“可持续”和“设计”的两点谈起,来论述从线性经济向可持续经济的转变,以及“可持续设计”的四个主要阶段:理解、定义、制造、发布。
“循环设计”不是为了追求时髦或者抬升设计地位,而是将这个已经日益庸俗化的“设计”冠为自己的定语,是设计本身发展所趋,以及可持续发展所需,设计界需要对自己的责任有所承担,形成一个全局观、系统性看待设计问题的方式。让回收利用和可持续发展成为一种规范,从而做到一劳永逸。

我们生活在一个呼唤变革的世界。在过去的50年中,现代社会所依赖的漫不经心和无休止的消费是不可持续的。我们从小就不关心自己的事情。如果有什么东西坏了,我们也就不修了。产品被设计成用完直接丢弃,而不是去修复。数字产品也不例外。然而,为了解决这些问题,出现了一种新的思维方式:循环设计(可持续设计)①。(益达说:其实这个理念和风格已经存在了很长的时间,大多应用在不为大众所知的能源、材料再生流程之中,然而随着时代的发展,循环设计可以变得更加普世。)
①注:循环设计是20世纪80-90年代产生的一种设计风格,他又称回收设计,是指实现广义收回和利用的方法,即在进行产品设计时,充分考虑产品零部件及材料回收的可能性,回收价值的大致方法,回收处理结构工艺性等于与回收有关的一系列问题,以达到零部件及材料资源和能源的再利用。它旨在通过设计来节约能源和材料,减少对环境的污染,使人类的设计物能多次反复利用,形成产品设计和使用的良性循环。
那么,循环设计方法意味着什么?在数字产品上要如何使用?在回答这些问题之前,首先,我们需要仔细观察我们是如何构建我们的世界,为什么这个世界已经不可持续了,并且要理解环保世界的需求是如何改变我们的思维方式,促使我们渴望从线性设计模型转变为循环设计模型。
向循环转变
我们的经济主要基于“按需配置”流程之上。在此线性系统中,我们构建了会在一段时间后淘汰的产品,并且将其组件视为垃圾。与此相反,循环设计方法将产品的生命周期视为一个闭环,其中资源不断地被重新利用。
在“经典”线性模型中,产品经历了生产、消费和破坏的各个阶段,最终以浪费告终。在设计一款循环产品过程中,我们使用的方法包含四大阶段,这四个阶段形成了一个闭环,并形成了一个恒定的循环,在这个循环中,不仅仅只有闪闪发亮的、新的,未使用过的材料才被受欢迎。
循环设计方法的四个阶段是:
理解 / 定义 / 制造 / 发布
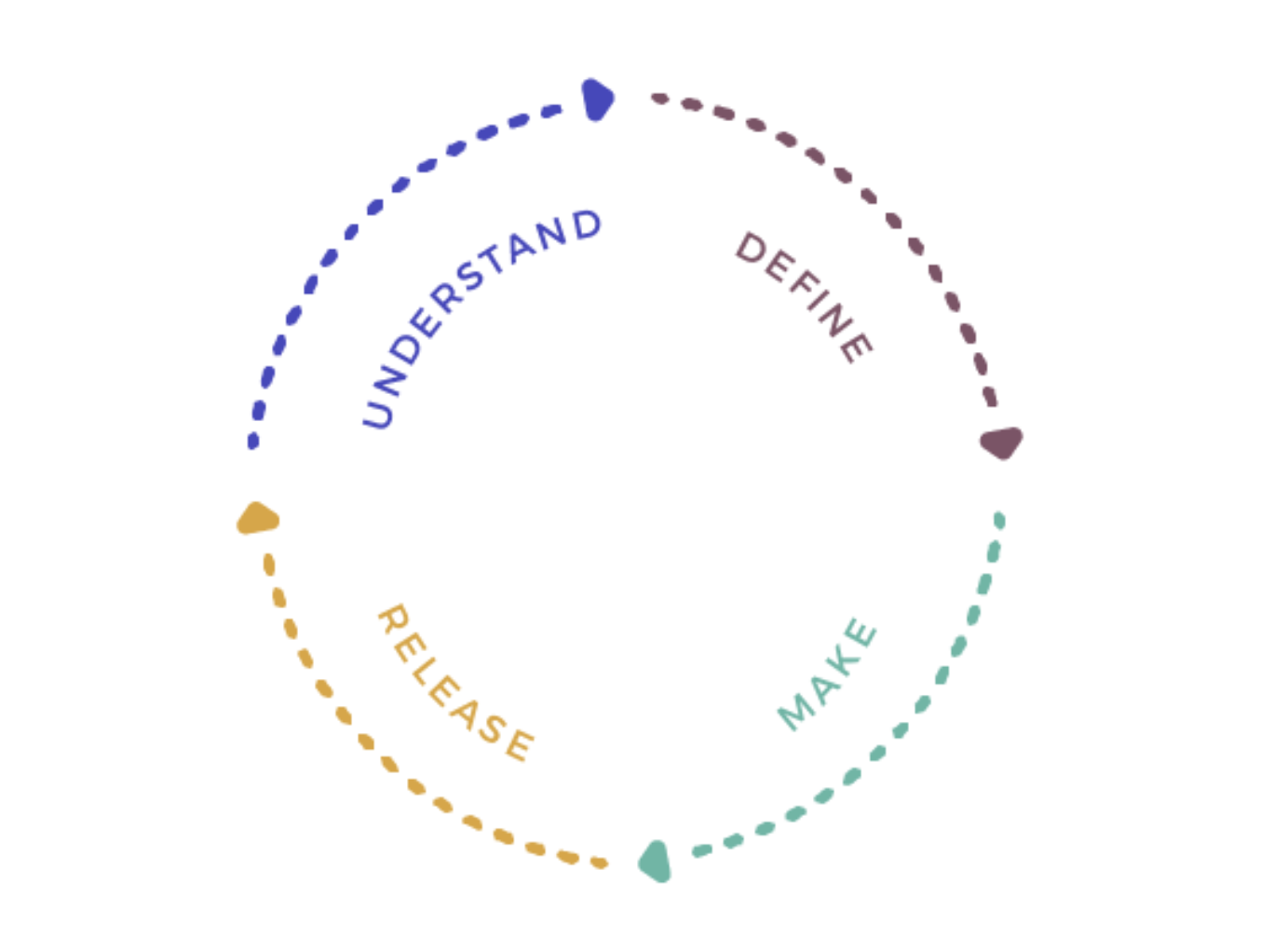
当我们同时看线性设计和循环设计模型方法时,有一点吸引人的是,开始设计东西的时候,方法的差异。从只是生产某种东西,到对我们将要生产的产品做出深思熟虑的决定,以及在实施过程中付出的努力和关心,这是一个大转变。
看看我们现在的立场
为什么做出这种转变如此的重要?我确信每个看新闻的人都听说过气候变化。NASA 致力于解决环境问题,因此我们都可以非常详细地了解人类行为和无限增长对我们生态系统的影响。
但好消息是我们不必继续这样做,因为我们可以很容易从数字世界中“产生”方式中学习事物的产生。电力废弃物已成为现代世界的主要废弃物来源之一。大量的手机和电脑被扔掉,随之经济是建立在每年都有新东西的基础上的。
当您的手机屏幕意外碎裂时,我们该怎么办?我们知道如何处理它吗?我们知道如何修理吗?我们并不知道……但是幸运的是,有些设计师对此问题提出了解决方案。Fairphone② 是一种合乎情理,模块化的智能手机,其组件数量很少,可以轻松更换和回收。大公司也应朝这个方向迈出一步,让回收利用和可持续发展成为一种时尚和规范,一劳永逸。
② Fairphone:这家公司生产的手机希望实现全球手机供应链的公平贸易,具体而言就是不使用“冲突矿物”并且确保生产手机的工人没有被奴役和压榨,目前仍然坚持在非洲贫困和战乱的国家进口材料,已经在刚果和卢旺达境内找到了一些矿山,用更好的商业实践推动当地经济更健康地发展。
设计和设计师的重要性
设计师,比任何其他专业人士,都更有可能在一转变中产生巨大的影响的人。我还敢说,我们有责任采用可持续设计的方式行动和思考。因为是我们创造了那些最终出现在传送带上的东西。我们也有责任教育我们的用户。幸运的是,越来越多的人重视具有可持续发展目标的产品或品牌,或者重视起在产品背后有意义的故事。同样,可持续发展不仅成为流行语,而且成为一种价值观,被越来越多的人意识到基于有限资源的无限增长是无法实现的目标。但是,要从线性经济向可持续经济转变,我们需要学习不同的思维方式。幸运的是,智能设备和数字产品的时代带来了一种复杂的设计思维方法,可以作为物理世界中生产链的范例。

用户体验必须提供什么
地球上有一个地方,您不能随便丢东西:互联网。这是一个对已有产品进行再构思的地方,您只能去完善它,不能丢弃它,因为如果您一夜之间说:“我不喜欢我的网站,明天我将推出一个全新的网站”,那您便会失去用户。
如果我们看一下可持续发展设计方法的四个主要阶段,就会发现我们在用户体验设计中使用的方法与此很相似。
让我们再次看一下四个阶段,然后将其更详细地分解:
当我们谈论与循环设计相关的理解时,我们谈论的是在开始设计一个未来的产品之前就了解它的用户和环境。研究一直是数字产品设计的基础。与数字产品的连接比与实体产品的连接要更多的涉及到人类的心理。因此不可避免地要开发出新的研究方法,以帮助我们洞察用户在使用某种产品时的想法、感受和行为。但这不仅与用户有关, 研究还必须深入到经济领域,并研究未来产品的组成部分,同时牢记它们必须可被再次利用。
在此阶段,将定义(商业)目标,并构建一个商业模型画布作为生产过程的计划。用户体验使用这种方法已有一段时间了,让涉众参与其中,并在设计过程中更多地激活它们。为我们设计的产品设定一个目标是至关重要的,因为有了它,我们可以为用户创造额外的价值。因此,无论是制作商业模型画布还是举办精彩的价值主张研讨会,在生产方式中实施这些方法都会对当前的生产流程产生巨大的影响。
这是关键部分。现在我们正在做的事情就好像没有明天一样。随着每种无法回收的产品的出现,我们产生的废料越来越多。但是循环方法是为产品创建一个原型,并定义将需要使用那些材料反映在产品原型上,并在定义阶段概述的商业模型上定义材料。原型设计和构思是用户体验设计过程中的关键要素,这也是为什么需要制作原型。
根据循环设计模型,随着产品的发布,生产周期进入了第四阶段,然同时理解阶段又重新开始了。对于数字产品来说,这是自然发生的事前:你发布一个产品,基于该版本收集反馈,然后构思它,周而复始,这个循环再次产生。
但是,观察这个循环并建立这些连接仅仅是冰山一角。在数字时代发展起来的设计思维给世界带来了许多反思。
变革中的大佬
幸运的是,已经有许多大品牌意识到转变的必要性,并采取和提出了数字设计思维方法来支持转变,并建立循环设计的时代。根据《循环设计指南》,“我们应该把我们设计的所有东西都看作软件产品和服务——这些产品和服务可以基于我们通过反馈得到的数据而不断的发。”
用户体验研究和用户体验设计一直是在做的一件事是:基于全面的研究和真实的用户需求来构建产品。上面的设计指南是非常复杂的工具,具有许多可能的方法。它强调了从产品到服务流程转变的重要性,并展示如何使用敏捷流程并将其实施到构建产品的方法之中。
IDEO(全球顶尖的设计咨询公司)与 Ellen Macarthur Foundation(艾伦·麦克阿瑟基金会)合作,试图“试图通过设计构建一个具有恢复性和再生性的经济框架”。在这里,您可以找到几乎每个生产方面和领域——例如食品、时装、经济和设计——并在每个领域中提出解决方案,以打破线性生产系统。
耐克还宣布了其基于循环设计模型生产高品质运动鞋的新方法原则。正如您已经看到的那样,无论您身处哪个经济领域,都可以为循环生产过程的蓬勃发展做贡献,并成为一支主导力量。
重要的结论
我认为,作为设计师,我们始终要为变革而努力,并始终努力与客户、产品或服务保持紧密的关系,并通过构思使其不断完善,以实现这一目标。这是因为伟大的事情只有通过时间和不断的反思才能实现。在离线世界中,数字设计过程也有很多东西可以贡献。希望通过教育,能有更多的大公司意识到用户真正想要的产品是具有更多功能并可持续使用的,而不仅仅是将它们当作一次性产品,一旦它们不像最初那样光鲜就把她扔掉。
转自:站酷-大猴儿er
网上可以找到前端开发社区贡献的大量工具,这篇文章列出了我最喜欢的一些工具,这些工具给我的工作带来了许多便利。
1. EnjoyCSS
老实说,虽然我做过许多前端开发,但我并不擅长 CSS。当我陷入困境时,EnjoyCSS 是我的大救星。EnjoyCSS 提供了一个简单的交互界面,帮助我设计元素,然后自动输出相应的 CSS 代码。
EnjoyCSS 可以输出 CSS、LESS、SCSS 代码,并支持指定需要支持哪些浏览器及其版本。开发简单页面时用起来比较方便,但不太适合复杂一点的前端项目(这类项目往往需要引入 CSS 框架)。
2. Prettier Playground
Prettier 是一个代码格式化工具,支持格式化 JavaScript 代码(包括 ES2017、JSX、Angular、Vue、Flow、TypeScript 等)。Prettier 会移除代码原本的样式,替换为遵循最佳实践的标准化、一致的样式。IDE 大多支持 Prettier 工具,不过 Prettier 也有在线版本,让你可以在浏览器里格式化代码。
如果工作电脑不在手边,使用移动端设备或者临时借用别人的电脑查看代码时,Prettier Playground 非常好用。相比在 IDE 或编辑器下使用 Prettier,个人更推荐通过 git pre-commit hook 配置 Prettier:hook 可以保证整个团队使用统一的配置,免去各自分别配置 IDE 或编辑器的麻烦。如果是老项目,hook 还可以设置只格式化有改动的单个文件甚至有改动的代码段,避免在 IDE 或编辑器下使用 Prettier 时不小心格式了大量代码,淹没了 commit 的主要改动,让 review 代码变得十分痛苦。
3. Postman
Postman 一直在我的开发工具箱里,测试后端 API 接口时非常好用。GET、POST、DELETE、OPTIONS、PUT 这些方法都支持。毫无疑问,你应该使用这个工具。
Postman 之外,Insomnia 也是很流行的 REST API 测试工具,亮点是支持 GraphQL。不过 Postman 从 去年夏天发布的 v7.2 起也支持了 GraphQL。
4. StackBlitz
Chidume Nnamdi 盛赞这是每个用户最喜欢的在线 IDE。StackBlitz 将大家最喜欢、最常用的 IDE Visual Studio Code 搬进了浏览器。
StackBlitz 支持一键配置 Angular、React、Ionic、TypeScript、RxJS、Svelte 等 JavaScript 框架,也就是说,只需几秒你就可以开始写代码了。
我觉得这个在线 IDE 很有用,特别是可以在线尝试一些样例代码或者库,否则仅仅尝试一些新特性就需要花很多时间在新项目初始化配置上。有了 StackBlitz,无需在本地从头搭建环境,花上几分钟就可以试用一个 NPM 包。很棒,不是吗?
微软官方其实也提供了在线版本的 VSCode,可以在浏览器内使用 VSCode,并且支持开发 Node.js 项目(基于 Azure)。不过 StackBlitz 更专注于优化前端开发体验,界面更加直观一点,也推出了 beta 版本的 Node.js 支持(基于 GCP,需要填表申请)。
5. Bit.dev
软件开发的基本原则之一就是代码复用。代码复用减少了开发量,让你不用从头开发组件。
这正是 Bit.dev 做的事,分享可重用的组件和片段,降低开发量,加速开发进程。
除了公开分享,它还支持在团队分享,让团队协作更方便。
正如 Bit.dev 的口号「组件即设计体系。协同开发更好的组件。」所言,Bit.dev 可以用来创建设计体系,允许团队内的开发者和设计师一起协作,从头搭建一套设计体系。
Bit.dev 目前支持 React、Vue、Angular、Node 及其他 JavaScript 框架。
在 Bit.dev 上不仅可以搜索组件,还可以直接查看组件的依赖,浏览组件的代码,甚至在线编辑代码并查看预览效果!选好组件后可以通过 Bit.dev 的命令行工具 bit 在本地项目引入组件,也可以通过 npm、yarn 引入组件。
6. CanIUse
CanIUse是非常好用的在线工具,可以方便地查看各大浏览器对某个特性的支持程度。
我过去经常碰到自己开发的应用的一些功能在其他浏览器下不支持的情况。比如我的作品集项目使用的某个特性在 Safari 下不支持,直到项目上线几个月后我才意识到。这些经验教训让我意识到需要检查浏览器兼容性。
我们来看一个例子吧。哪些浏览器支持 WebP 图像格式?
如你所见,Safari 和 IE 目前不支持 WebP。这意味着需要为不兼容的浏览器提供回退选项,比如:
<picture>
CanIUse 还可以在命令行下使用,例如,在命令行下查看 WebP 图像格式的浏览器兼容性:caniuse webp(运行命令前需要事先通过 npm install -g caniuse-cmd安装命令行工具。
方法参数的验证
JavaScript 允许你设置参数的默认值。通过这种方法,可以通过一个巧妙的技巧来验证你的方法参数。
const isRequired = () => { throw new Error('param is required'); };
const print = (num = isRequired()) => { console.log(`printing ${num}`) };
print(2);//printing 2
print()// error
print(null)//printing null
非常整洁,不是吗?
格式化 json 代码
你可能对 JSON.stringify 非常熟悉。但是你是否知道可以用 stringify 进行格式化输出?实际上这很简单。
stringify 方法需要三个输入。 value,replacer 和 space。后两个是可选参数。这就是为什么我们以前没有注意过它们。要对 json 进行缩进,必须使用 space 参数。
console.log(JSON.stringify({name:"John",Age:23},null,'\t'));
>>>
{
"name": "John",
"Age": 23
}
从数组中获取唯一值
要从数组中获取唯一值,我们需要使用 filter 方法来过滤出重复值。但是有了新的 Set 对象,事情就变得非常顺利和容易了。
let uniqueArray = [...new Set([1, 2, 3, 3, 3, "school", "school", 'ball', false, false, true, true])];
>>> [1, 2, 3, "school", "ball", false, true]
从数组中删除虚值(Falsy Value)
在某些情况下,你可能想从数组中删除虚值。虚值是 JavaScript 的 Boolean 上下文中被认定为为 false 的值。 JavaScript 中只有六个虚值,它们是:
undefined
null
NaN
0
"" (空字符串)
false
滤除这些虚值的最简单方法是使用以下函数。
myArray.filter(Boolean);
如果要对数组进行一些修改,然后过滤新数组,可以尝试这样的操作。请记住,原始的 myArray 会保持不变。
myArray
.map(item => {
// Do your changes and return the new item
})
.filter(Boolean);
合并多个对象
假设我有几个需要合并的对象,那么这是我的首选方法。
const user = {
name: 'John Ludwig',
gender: 'Male'
};
const college = {
primary: 'Mani Primary School',
secondary: 'Lass Secondary School'
};
const skills = {
programming: 'Extreme',
swimming: 'Average',
sleeping: 'Pro'
};
const summary = {...user, ...college, ...skills};
这三个点在 JavaScript 中也称为展开运算符。你可以在这里学习更多用法。
对数字数组进行排序
JavaScript 数组有内置的 sort 方法。默认情况下 sort 方法把数组元素转换为字符串,并对其进行字典排序。在对数字数组进行排序时,这有可能会导致一些问题。所以下面是解决这类问题的简单解决方案。
[0,10,4,9,123,54,1].sort((a,b) => a-b);
>>> [0, 1, 4, 9, 10, 54, 123]
这里提供了一个将数字数组中的两个元素与 sort 方法进行比较的函数。这个函数可帮助我们接收正确的输出。
Disable Right Click
禁用右键
你可能想要阻止用户在你的网页上单击鼠标右键。
<body oncontextmenu="return false">
<div></div>
</body>
这段简单的代码将为你的用户禁用右键单击。
使用别名进行解构
解构赋值语法是一种 JavaScript 表达式,可以将数组中的值或对象的值或属性分配给变量。解构赋值能让我们用更简短的语法进行多个变量的赋值。
const object = { number: 10 };
// Grabbing number
const { number } = object;
// Grabbing number and renaming it as otherNumber
const { number: otherNumber } = object;
console.log(otherNumber); //10
获取数组中的最后一项
可以通过对 splice 方法的参数传入负整数,来数获取组末尾的元素。
let array = [0, 1, 2, 3, 4, 5, 6, 7]
console.log(array.slice(-1));
>>>[7]
console.log(array.slice(-2));
>>>[6, 7]
console.log(array.slice(-3));
>>>[5, 6, 7]
等待 Promise 完成
在某些情况下,你可能会需要等待多个 promise 结束。可以用 Promise.all 来并行运行我们的 promise。
const PromiseArray = [
Promise.resolve(100),
Promise.reject(null),
Promise.resolve("Data release"),
Promise.reject(new Error('Something went wrong'))];
Promise.all(PromiseArray)
.then(data => console.log('all resolved! here are the resolve values:', data))
.catch(err => console.log('got rejected! reason:', err))
关于 Promise.all 的主要注意事项是,当一个 Promise 拒绝时,该方法将引发错误。这意味着你的代码不会等到你所有的 promise 都完成。
如果你想等到所有 promise 都完成后,无论它们被拒绝还是被解决,都可以使用 Promise.allSettled。此方法在 ES2020 的最终版本得到支持。
const PromiseArray = [
Promise.resolve(100),
Promise.reject(null),
Promise.resolve("Data release"),
Promise.reject(new Error('Something went wrong'))];
Promise.allSettled(PromiseArray).then(res =>{
console.log(res);
}).catch(err => console.log(err));
//[
//{status: "fulfilled", value: 100},
//{status: "rejected", reason: null},
//{status: "fulfilled", value: "Data release"},
//{status: "rejected", reason: Error: Something went wrong ...}
//]
即使某些 promise 被拒绝,Promise.allSettled 也会从你所有的 promise 中返回结果。
XML(Extensible Markup Language 可扩展标记语言),XML是一个以文本来描述数据的文档。
<?xml version="1.0" encoding="UTF-8"?>
<people>
<person personid="E01">
<name>Tony</name>
<address>10 Downing Street, London, UK</address>
<tel>(061) 98765</tel>
<fax>(061) 98765</fax>
<email>tony@everywhere.com</email>
</person>
<person personid="E02">
<name>Bill</name>
<address>White House, USA</address>
<tel>(001) 6400 98765</tel>
<fax>(001) 6400 98765</fax>
<email>bill@everywhere.com</email>
</person>
</people>
(1)充当显示数据(以XML充当显示层)
(2)存储数据(存储层)的功能
(3)以XML描述数据,并在联系服务器与系统的其余部分之间传递。(传输数据的一样格式)
从某种角度讲,XML是数据封装和消息传递技术。
3.解析XML:// 创建SAX解析器工厂对象 SAXParserFactory spf = SAXParserFactory.newInstance(); // 使用解析器工厂创建解析器实例 SAXParser saxParser = spf.newSAXParser(); // 创建SAX解析器要使用的事件侦听器对象 PersonHandler handler = new PersonHandler(); // 开始解析文件 saxParser.parse( new File(fileName), handler);
3.2. DOM解析XML:
DOM:Document Object Model(文档对象模型)
DOM的特性:
定义一组 Java 接口,基于对象,与语言和平台无关将 XML 文档表示为树,在内存中解析和存储 XML 文档,允许随机访问文档的不同部分。
DOM解析XML
DOM的优点,由于树在内存中是持久的,因此可以修改后更新。它还可以在任何时候在树中上下导航,API使用起来也较简单。
DocumentBuilderFactory builder = DocumentBuilderFactory.newInstance();
DocumentBuilder db = builder.newDocumentBuilder();
db.parse("person.xml");
NodeList node_person = doc.getElementsByTagName("person");
3.3. JDOM解析XML:
JDOM是两位著名的 Java 开发人员兼作者,Brett Mclaughlin 和 Jason Hunter 的创作成果, 2000 年初在类似于Apache协议的许可下,JDOM作为一个开放源代码项目正式开始研发了。
JDOM 简化了与 XML 的交互并且比使用 DOM 实现更快,JDOM 与 DOM 主要有两方面不同。首先,JDOM 仅使用具体类而不使用接口。这在某些方面简化了 API,但是也限制了灵活性。第二,API 大量使用了 Collections 类,简化了那些已经熟悉这些类的 Java 开发者的使用。
解析步骤: (1)SAXBuilder sax = new SAXBuilder(); (2)Document doc = sax.build(….); (3)Element el = doc.getRootElement();(4)List list = el.getChildren(); (5)遍历内容
解析步骤:
(1)SAXReader sax = new SAXReader();
(2)Document doc = sax.read(Thread.currentThread().getContextClassLoader()
.getResourceAsStream("person.xml"));
(3)Element root = doc.getRootElement();
(4)Iterator iterator = root.elementIterator();
(5)遍历迭代器
public class Person {
private String personid;
private String name;
private String address;
private String tel;
private String fax;
private String email;
@Override
public String toString() {
return "Person{" +
"personid='" + personid + '\'' +
", name='" + name + '\'' +
", address='" + address + '\'' +
", tel='" + tel + '\'' +
", fax='" + fax + '\'' +
", email='" + email + '\'' +
'}';
}
public String getPersonid() {
return personid;
}
public void setPersonid(String personid) {
this.personid = personid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getTel() {
return tel;
}
public void setTel(String tel) {
this.tel = tel;
}
public String getFax() {
return fax;
}
public void setFax(String fax) {
this.fax = fax;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}
<?xml version="1.0" encoding="UTF-8"?>
<people>
<person personid="E01">
<name>Tony Blair</name>
<address>10 Downing Street, London, UK</address>
<tel>(061) 98765</tel>
<fax>(061) 98765</fax>
<email>blair@everywhere.com</email>
</person>
<person personid="E02">
<name>Bill Clinton</name>
<address>White House, USA</address>
<tel>(001) 6400 98765</tel>
<fax>(001) 6400 98765</fax>
<email>bill@everywhere.com</email>
</person>
</people>
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import java.util.ArrayList;
import java.util.List;
/**
* Created by Hu Guanzhong
* SAX解析的特点:
* 1、基于事件驱动
* 2、顺序读取,速度快
* 3、不能任意读取节点(灵活性差)
* 4、解析时占用的内存小
* 5、SAX更适用于在性能要求更高的设备上使用(Android开发中)
*
*/
public class PersonHandler extends DefaultHandler{
private List<Person> persons = null;
private Person p;//当前正在解析的person
private String tag;//用于记录当前正在解析的标签名
public List<Person> getPersons() {
return persons;
}
//开始解析文档时调用
@Override
public void startDocument() throws SAXException {
super.startDocument();
persons = new ArrayList<>();
System.out.println("开始解析文档...");
}
//在XML文档解析结束时调用
@Override
public void endDocument() throws SAXException {
super.endDocument();
System.out.println("解析文档结束.");
}
/**
* 解析开始元素时调用
* @param uri 命名空间
* @param localName 不带前缀的标签名
* @param qName 带前缀的标签名
* @param attributes 当前标签的属性集合
* @throws SAXException
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
if ("person".equals(qName)){
p = new Person();
String personid = attributes.getValue("personid");
p.setPersonid(personid);
}
tag = qName;
System.out.println("startElement--"+qName);
}
//解析结束元素时调用
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
super.endElement(uri, localName, qName);
if ("person".equals(qName)) {
persons.add(p);
}
tag = null;
System.out.println("endElement--"+qName);
}
//解析文本内容时调用
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
super.characters(ch, start, length);
if (tag != null) {
if ("name".equals(tag)) {
p.setName(new String(ch,start,length));
}else if("address".equals(tag)){
p.setAddress(new String(ch,start,length));
}else if("tel".equals(tag)){
p.setTel(new String(ch,start,length));
}else if("fax".equals(tag)){
p.setFax(new String(ch,start,length));
}else if("email".equals(tag)){
p.setEmail(new String(ch,start,length));
}
System.out.println(ch);
}
}
}
public class XMLDemo {
/**
* 使用第三方xstream组件实现XML的解析与生成
*/
@Test
public void xStream(){
Person p = new Person();
p.setPersonid("1212");
p.setAddress("北京");
p.setEmail("vince@163.com");
p.setFax("6768789798");
p.setTel("13838389438");
p.setName("38");
XStream xStream = new XStream(new Xpp3Driver());
xStream.alias("person",Person.class);
xStream.useAttributeFor(Person.class,"personid");
String xml = xStream.toXML(p);
System.out.println(xml);
//解析XML
Person person = (Person)xStream.fromXML(xml);
System.out.println(person);
}
/**
* 从XML文件中读取对象
*/
@Test
public void xmlDecoder() throws FileNotFoundException {
BufferedInputStream in = new BufferedInputStream(new FileInputStream("test.xml"));
XMLDecoder decoder = new XMLDecoder(in);
Person p = (Person)decoder.readObject();
System.out.println(p);
}
/**
* 把对象转成XML文件写入
*/
@Test
public void xmlEncoder() throws FileNotFoundException {
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("test.xml"));
XMLEncoder xmlEncoder = new XMLEncoder(bos);
Person p = new Person();
p.setPersonid("1212");
p.setAddress("北京");
p.setEmail("vince@163.com");
p.setFax("6768789798");
p.setTel("13838389438");
p.setName("38");
xmlEncoder.writeObject(p);
xmlEncoder.close();
}
/**
* DOM4J解析XML
* 基于树型结构,第三方组件
* 解析速度快,效率更高,使用的JAVA中的迭代器实现数据读取,在WEB框架中使用较多(Hibernate)
*
*/
@Test
public void dom4jParseXML() throws DocumentException {
//1 创建DOM4J的解析器对象
SAXReader reader = new SAXReader();
InputStream is = Thread.currentThread().getContextClassLoader()
.getResourceAsStream("com/vince/xml/person.xml");
org.dom4j.Document doc = reader.read(is);
org.dom4j.Element rootElement = doc.getRootElement();
Iterator<org.dom4j.Element> iterator = rootElement.elementIterator();
ArrayList<Person> persons = new ArrayList<>();
Person p = null;
while(iterator.hasNext()){
p = new Person();
org.dom4j.Element e = iterator.next();
p.setPersonid(e.attributeValue("personid"));
Iterator<org.dom4j.Element> iterator1 = e.elementIterator();
while(iterator1.hasNext()){
org.dom4j.Element next = iterator1.next();
String tag = next.getName();
if("name".equals(tag)){
p.setName(next.getText());
}else if("address".equals(tag)){
p.setAddress(next.getText());
}else if("tel".equals(tag)){
p.setTel(next.getText());
}else if("fax".equals(tag)){
p.setFax(next.getText());
}else if("email".equals(tag)){
p.setEmail(next.getText());
}
}
persons.add(p);
}
System.out.println("结果:");
System.out.println(Arrays.toString(persons.toArray()));
}
/**
* JDOM解析 XML
* 1、与DOM类似基于树型结构,
* 2、与DOM的区别:
* (1)第三方开源的组件
* (2)实现使用JAVA的Collection接口
* (3)效率比DOM更快
*/
@Test
public void jdomParseXML() throws JDOMException, IOException {
//创建JDOM解析器
SAXBuilder builder = new SAXBuilder();
InputStream is = Thread.currentThread().getContextClassLoader()
.getResourceAsStream("com/vince/xml/person.xml");
org.jdom2.Document build = builder.build(is);
Element rootElement = build.getRootElement();
List<Person> list = new ArrayList<>();
Person person = null;
List<Element> children = rootElement.getChildren();
for(Element element: children){
person = new Person();
String personid = element.getAttributeValue("personid");
person.setPersonid(personid);
List<Element> children1 = element.getChildren();
for (Element e: children1){
String tag = e.getName();
if("name".equals(tag)){
person.setName(e.getText());
}else if("address".equals(tag)){
person.setAddress(e.getText());
}else if("tel".equals(tag)){
person.setTel(e.getText());
}else if("fax".equals(tag)){
person.setFax(e.getText());
}else if("email".equals(tag)){
person.setEmail(e.getText());
}
}
list.add(person);
}
System.out.println("结果:");
System.out.println(Arrays.toString(list.toArray()));
}
/**
* DOM解析XML
* 1、基于树型结构,通过解析器一次性把文档加载到内存中,所以会比较占用内存,可以随机访问
* 更加灵活,更适合在WEB开发中使用
*/
@Test
public void domParseXML() throws ParserConfigurationException, IOException, SAXException {
//1、创建一个DOM解析器工厂对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//2、通过工厂对象创建解析器对象
DocumentBuilder documentBuilder = factory.newDocumentBuilder();
//3、解析文档
InputStream is = Thread.currentThread().getContextClassLoader()
.getResourceAsStream("com/vince/xml/person.xml");
//此代码完成后,整个XML文档已经被加载到内存中,以树状形式存储
Document doc = documentBuilder.parse(is);
//4、从内存中读取数据
//获取节点名称为person的所有节点,返回节点集合
NodeList personNodeList = doc.getElementsByTagName("person");
ArrayList<Person> persons = new ArrayList<>();
Person p = null;
//此循环会迭代两次
for (int i=0;i<personNodeList.getLength();i++){
Node personNode = personNodeList.item(i);
p = new Person();
//获取节点的属性值
String personid = personNode.getAttributes().getNamedItem("personid").getNodeValue();
p.setPersonid(personid);
//获取当前节点的所有子节点
NodeList childNodes = personNode.getChildNodes();
for (int j = 0;j<childNodes.getLength();j++){
Node item = childNodes.item(j);
String nodeName = item.getNodeName();
if ("name".equals(nodeName)) {
p.setName(item.getFirstChild().getNodeValue());
}else if("address".equals(nodeName)){
p.setAddress(item.getFirstChild().getNodeValue());
}else if("tel".equals(nodeName)){
p.setTel(item.getFirstChild().getNodeValue());
}else if("fax".equals(nodeName)){
p.setFax(item.getFirstChild().getNodeValue());
}else if("email".equals(nodeName)){
p.setEmail(item.getFirstChild().getNodeValue());
}
}
persons.add(p);
}
System.out.println("结果:");
System.out.println(Arrays.toString(persons.toArray()));
}
/**
* SAX解析的特点:
* 1、基于事件驱动
* 2、顺序读取,速度快
* 3、不能任意读取节点(灵活性差)
* 4、解析时占用的内存小
* 5、SAX更适用于在性能要求更高的设备上使用(Android开发中)
* @throws ParserConfigurationException
* @throws SAXException
* @throws IOException
*/
@Test
public void saxParseXML() throws ParserConfigurationException, SAXException, IOException {
//1、创建一个SAX解析器工厂对象
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
//2、通过工厂对象创建SAX解析器
SAXParser saxParser = saxParserFactory.newSAXParser();
//3、创建一个数据处理器(需要我们自己来编写)
PersonHandler personHandler = new PersonHandler();
//4、开始解析
InputStream is = Thread.currentThread().getContextClassLoader()
.getResourceAsStream("com/vince/xml/person.xml");
saxParser.parse(is,personHandler);
List<Person> persons = personHandler.getPersons();
for (Person p:persons){
System.out.println(p);
}
}
}
1. 加载和执行
尽量将所有的<script>标签放在</body>标签之前,确保脚本执行前页面已经完成了渲染,避免脚本的下载阻塞其他资源(例如图片)的下载。
合并脚本,减少页面中的<script>标签
使用<script>标签的defer和async属性(两者的区别见这里)
通过Javascript动态创建<script>标签插入文档来下载,其不会影响页面其他进程
2.数据存取
由于作用域链的机制,访问局部变量比访问跨作用域变量更快,因此在函数中若要多次访问跨作用域变量,则可以用局部变量保存。
避免使用with语句,其会延长作用域链
嵌套的对象成员会导致引擎搜索所有对象成员,避免使用嵌套,例如window.location.href
对象的属性和方法在原型链的位置越深,访问的速度也越慢
3.Dom编程
进行大段HTML更新时,推荐使用innerHTML,而不是DOM方法
HTML集合是一个与文档中元素绑定的类数组对象,其长度随着文档中元素的增减而动态变化,因此避免在每次循环中直接读取HTML集合的length,容易导致死循环
使用节点的children属性,而不是childNodes属性,前者访问速度更快,且不包含空白文本和注释节点。
浏览器的渲染过程包括构建DOM树和渲染树,当DOM元素的几何属性变化时,需要重新构造渲染树,这一过程称为“重排”,完成重排后,浏览器会重新绘制受影响的部分到屏幕中,这一过程称为“重绘”。因此应该尽量合并多次对DOM的修改,或者先将元素脱离文档流(display:none、文档片段),应用修改后,再插入文档中。
每次浏览器的重排时都会产生消耗,大多数浏览器会通过队列化修改并批量执行来优化重排过程,可当访问元素offsetTop、scrollTop、clientTop、getComputedStyle等一系列布局属性时,会强制浏览器立即进行重排返回正确的值。因此不要在dom布局信息改变时,访问这些布局属性。
当修改同个元素多个Css属性时,可以使用CssText属性进行一次性修改样式,减少浏览器重排和重绘的次数
当元素发生动画时,可以使用绝对定位使其脱离文档流,动画结束后,再恢复定位。避免动画过程中浏览器反复重排文档流中的元素。
多使用事件委托,减少监听事件
4.算法和流程控制
for循环和while循环性能差不多,除了for-in循环最慢(其要遍历原型链)
循环中要减少对象成员及数组项的查询次数,可以通过倒序循环提高性能
循环次数大于1000时,可运用Duff Devices减少迭代次数
switch比if-else快,但如果具有很多离散值时,可使用数组或对象来构建查找表
递归可能会造成调用栈溢出,可将其改为循环迭代
如果可以,对一些函数的计算结果进行缓存
5.字符串和正则表达式
进行大量字符串的连接时,+和+=效率比数组的join方法要高
当创建了一个正则表达式对象时,浏览器会验证你的表达式,然后将其转化为一个原生代码程序,用户执行匹配工作。当你将其赋值给变量时,可以避免重复执行该步骤。
当正则进入使用状态时,首先要确定目标字符串的起始搜索位置(字符串的起始位置或正则表达式的lastIndex属性),之后正则表达式会逐个检查文本和正则模式,当一个特定的字元匹配失败时,正则表达式会试着回溯到之前尝试匹配的位置,然后尝试其他路径。如果正则表达式所有的可能路径都没有匹配到,其会将起始搜索位置下移一位,重新开始检查。如果字符串的每个字符都经历过检查,没有匹配成功,则宣布彻底失败。
当正则表达式不那么具体时,例如.和[\s\S]等,很可能会出现回溯失控的情况,在js中可以应用预查模拟原子组(?=(pattern))\1来避免不必要的回溯。除此之外,嵌套的量词,例如/(A+A+)+B/在匹配"AAAAAAAA"时可能会造成惊人的回溯,应尽量避免使用嵌套的量词或使用预查模拟原子组消除回溯问题。
将复杂的正则表达式拆分为多个简单的片段、正则以简单、必需的字元开始、减少分支数量|,有助于提高匹配的效率。
setTimeout(function(){
process(todo.shift());
if (todo.length > 0) {
setTimeout(arguments.callee, 25);
} else {
callback();
}
})
setTimeout(function(){
let start = +new Date();
do {
process(todo.shift());
} while(todo.length > 0 && (+new Date() - start) < 50)
if (todo.length > 0) {
setTimeout(arguments.callee, 25);
} else {
callback();
}
})
WebWork进行计算
Expires: Mon,28 Jul 2018 23:30:30 GMT
eval、Function进行双重求值
Object/Array字面量定义,不要使用构造函数
if (i & 1) {
className = 'odd';
} else {
className = 'even';
}
Math对象等
蓝蓝设计的小编 http://www.lanlanwork.com