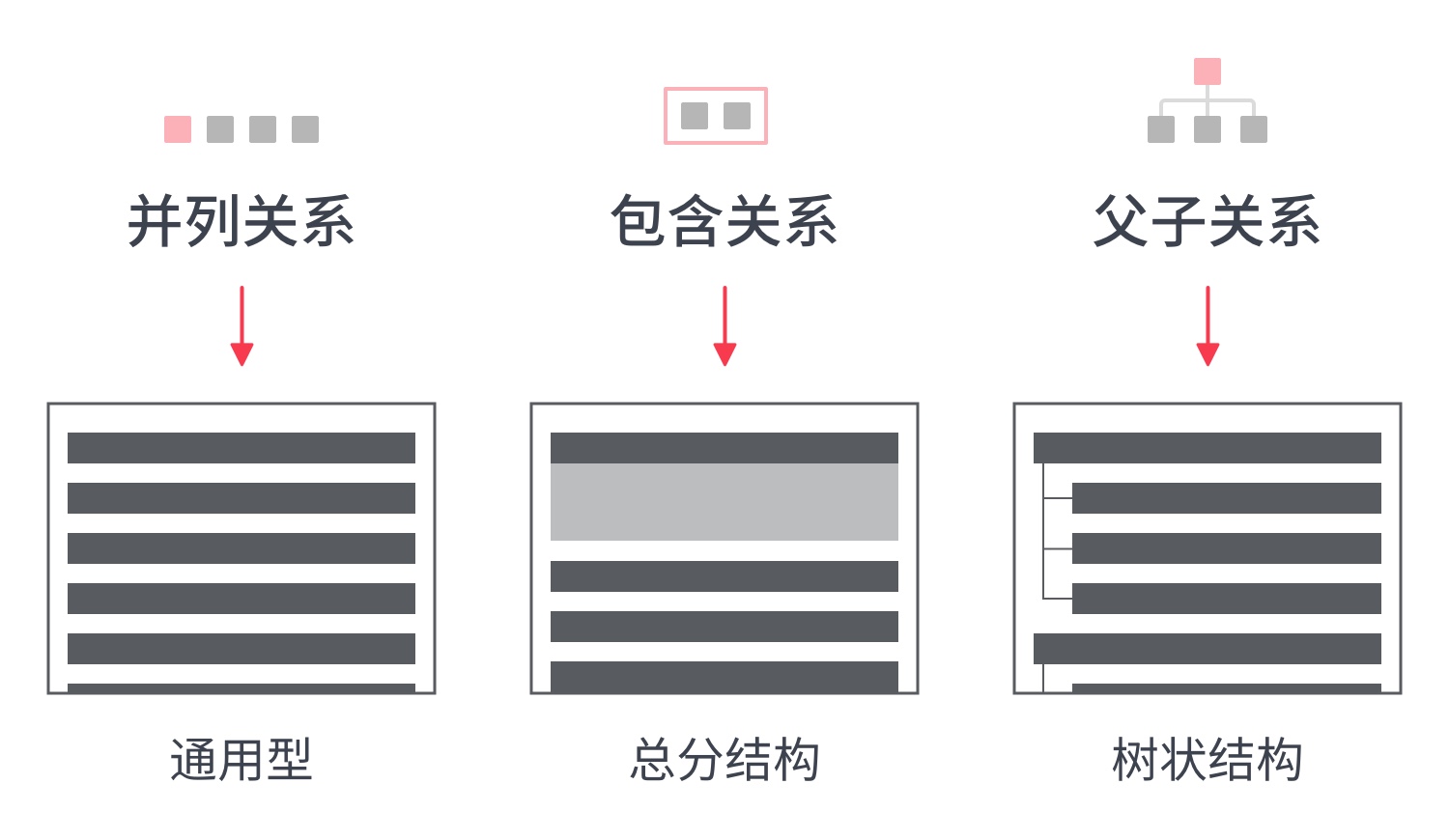
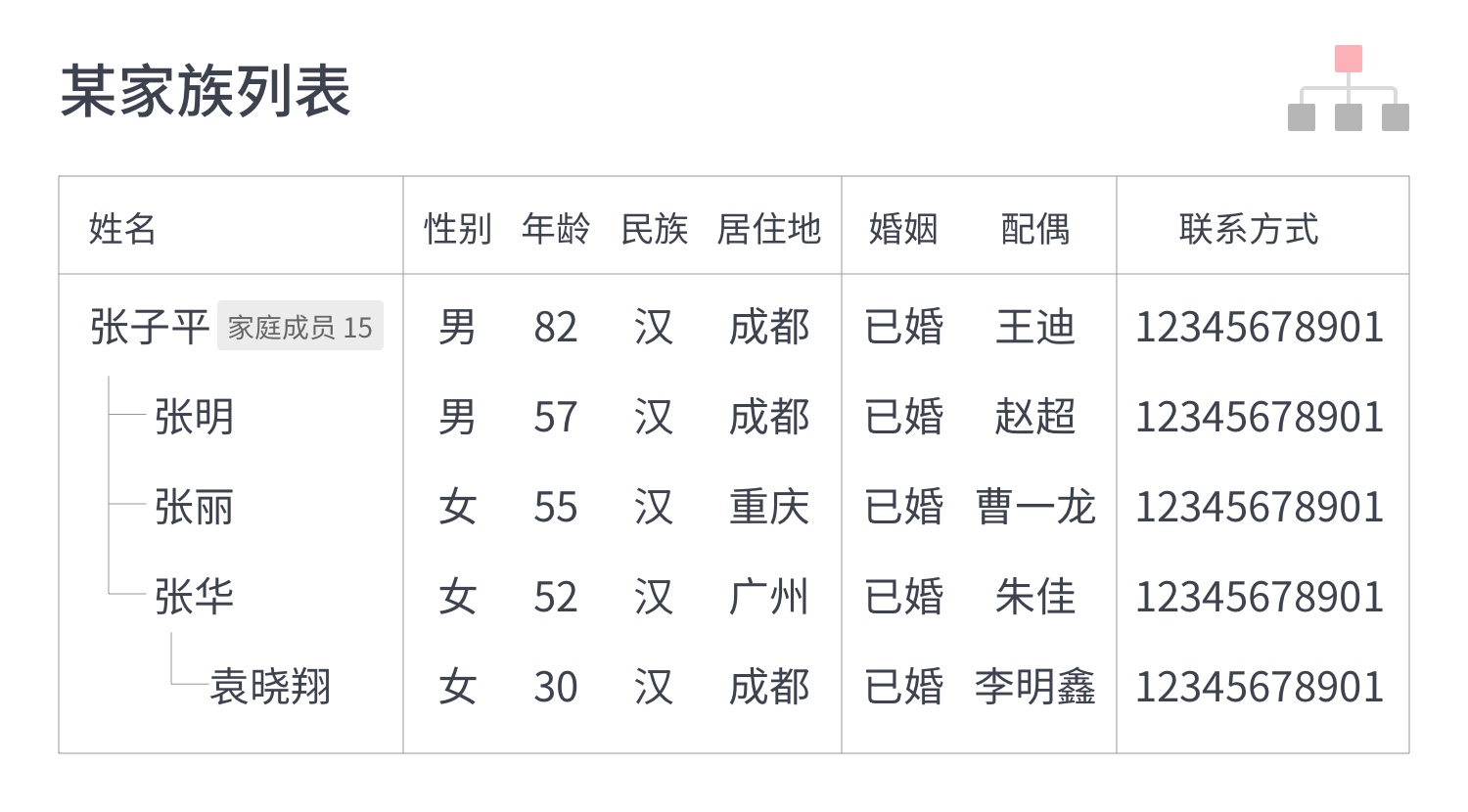
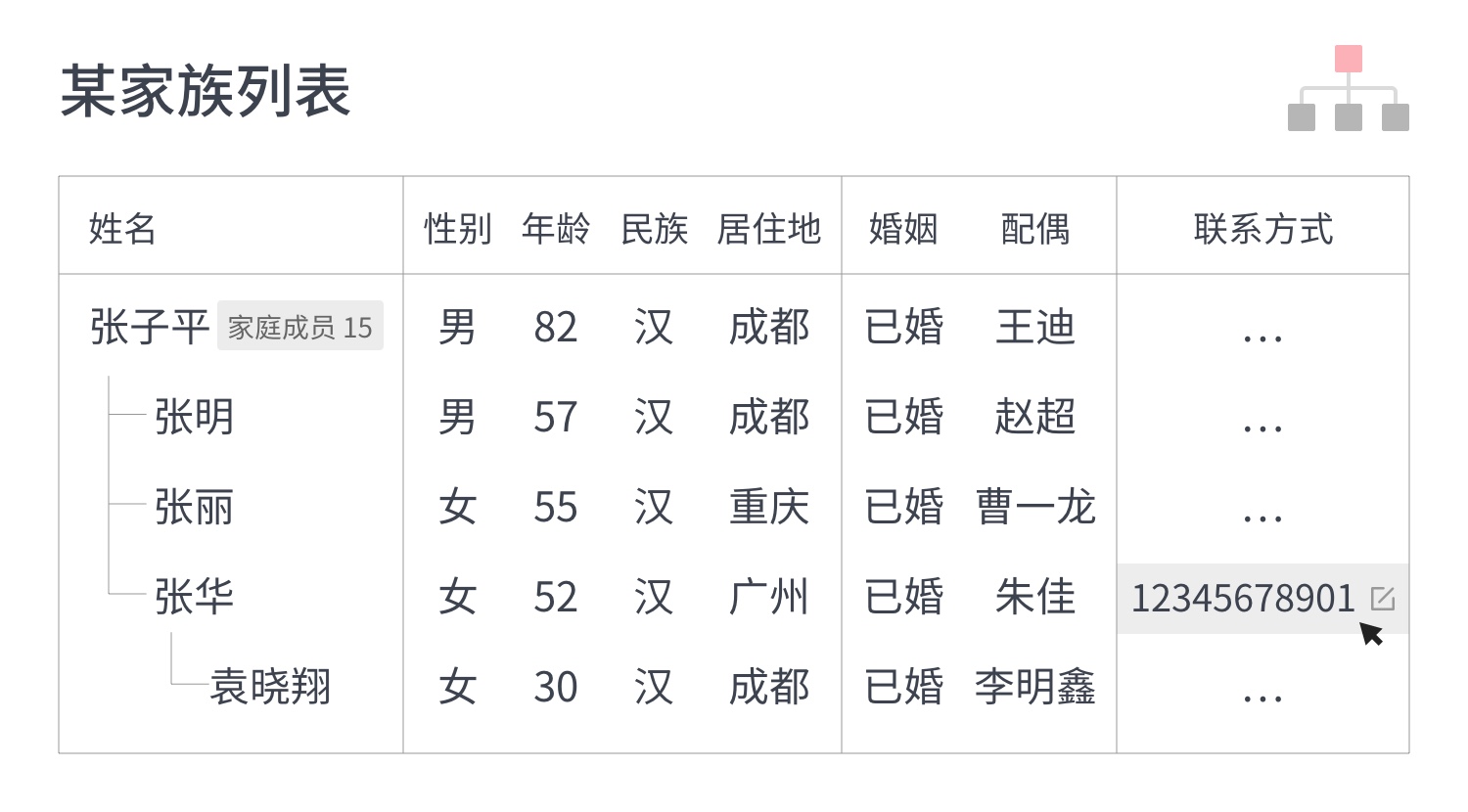
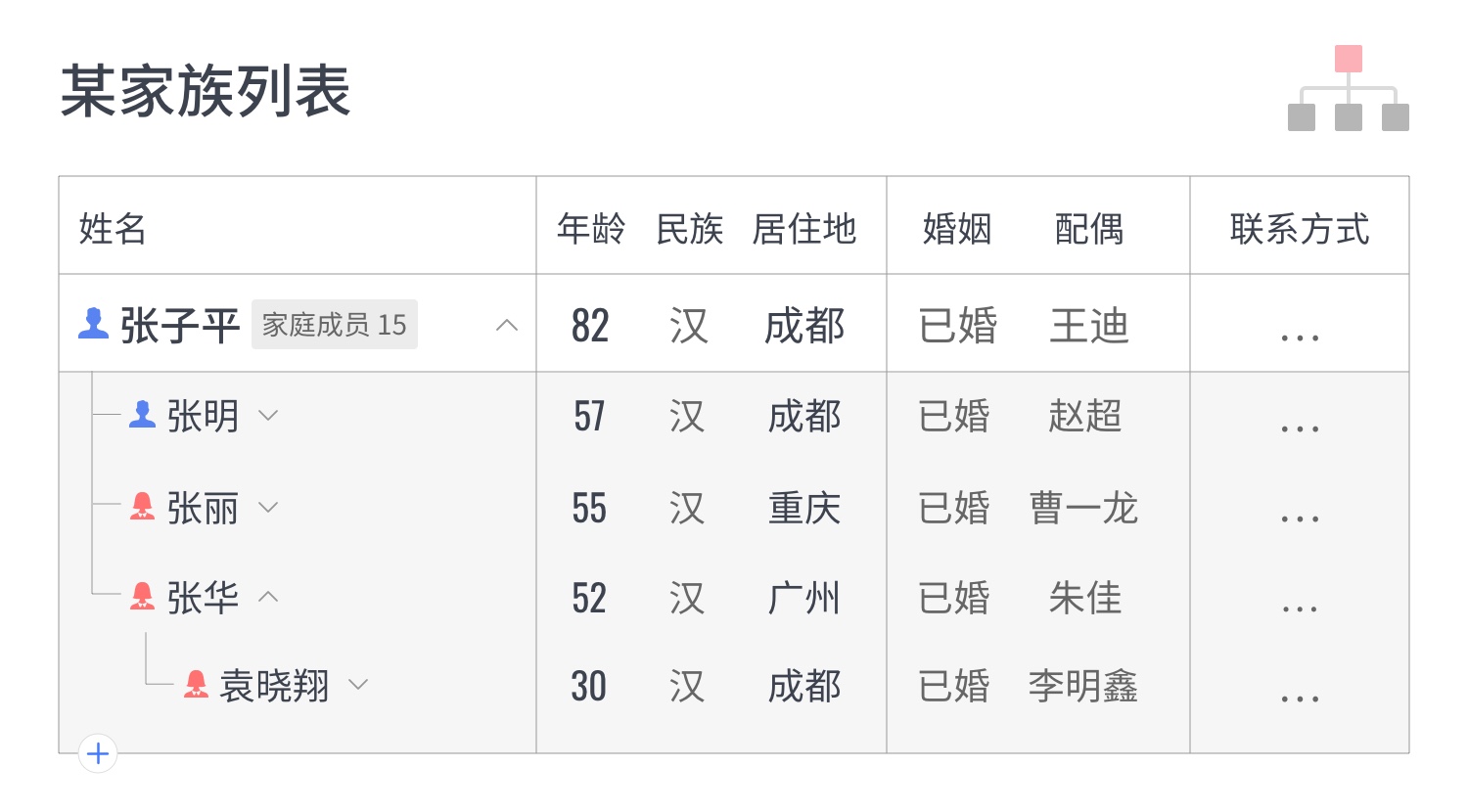
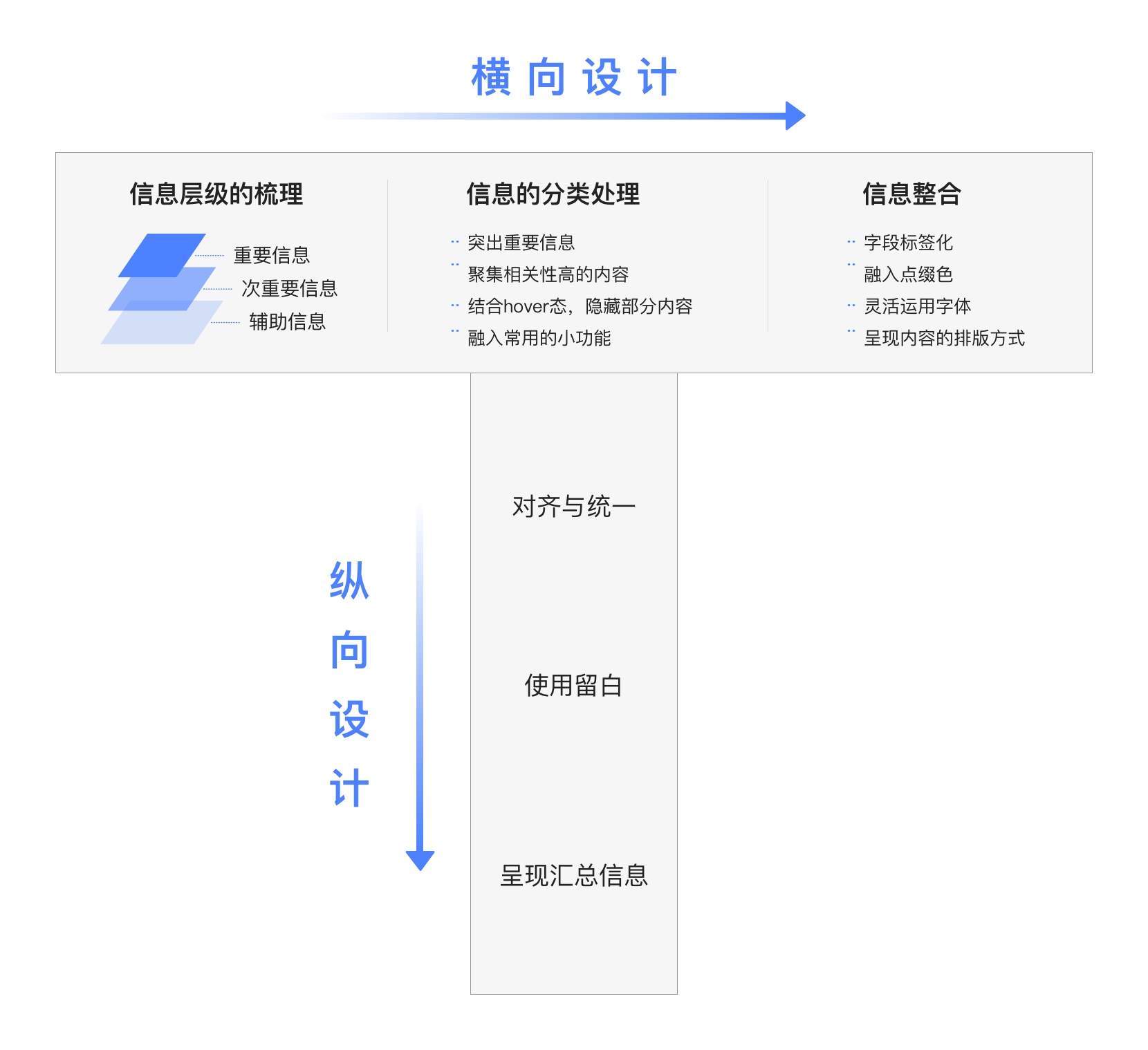
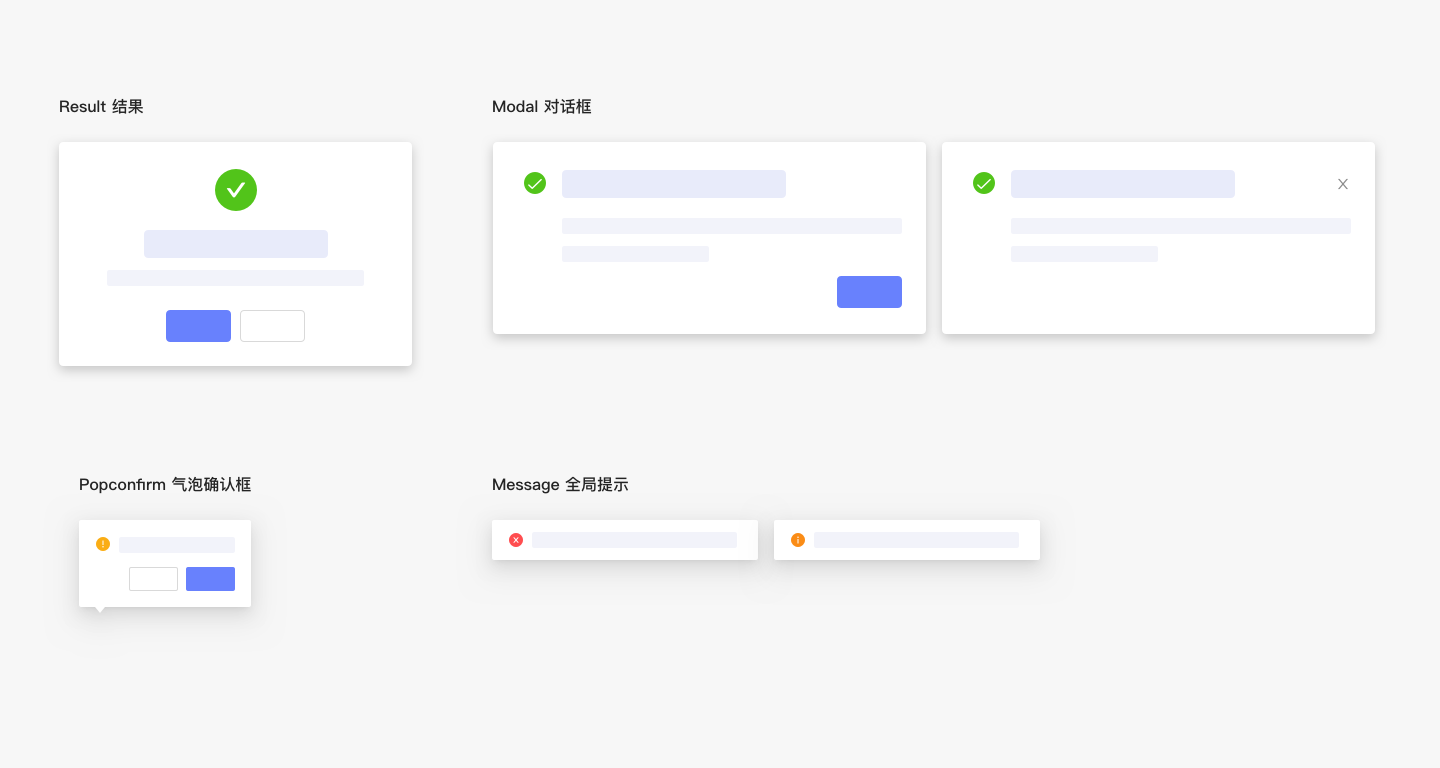
1. 什么是SUS ?
SUS 全称 System Usability Scale ,系统可用性量表。SUS最初是Brooke于1986年编制,可以科学地量化用户体验,用于完成一系列任务场景后,对产品或系统整体宏观的感知可用性测量。

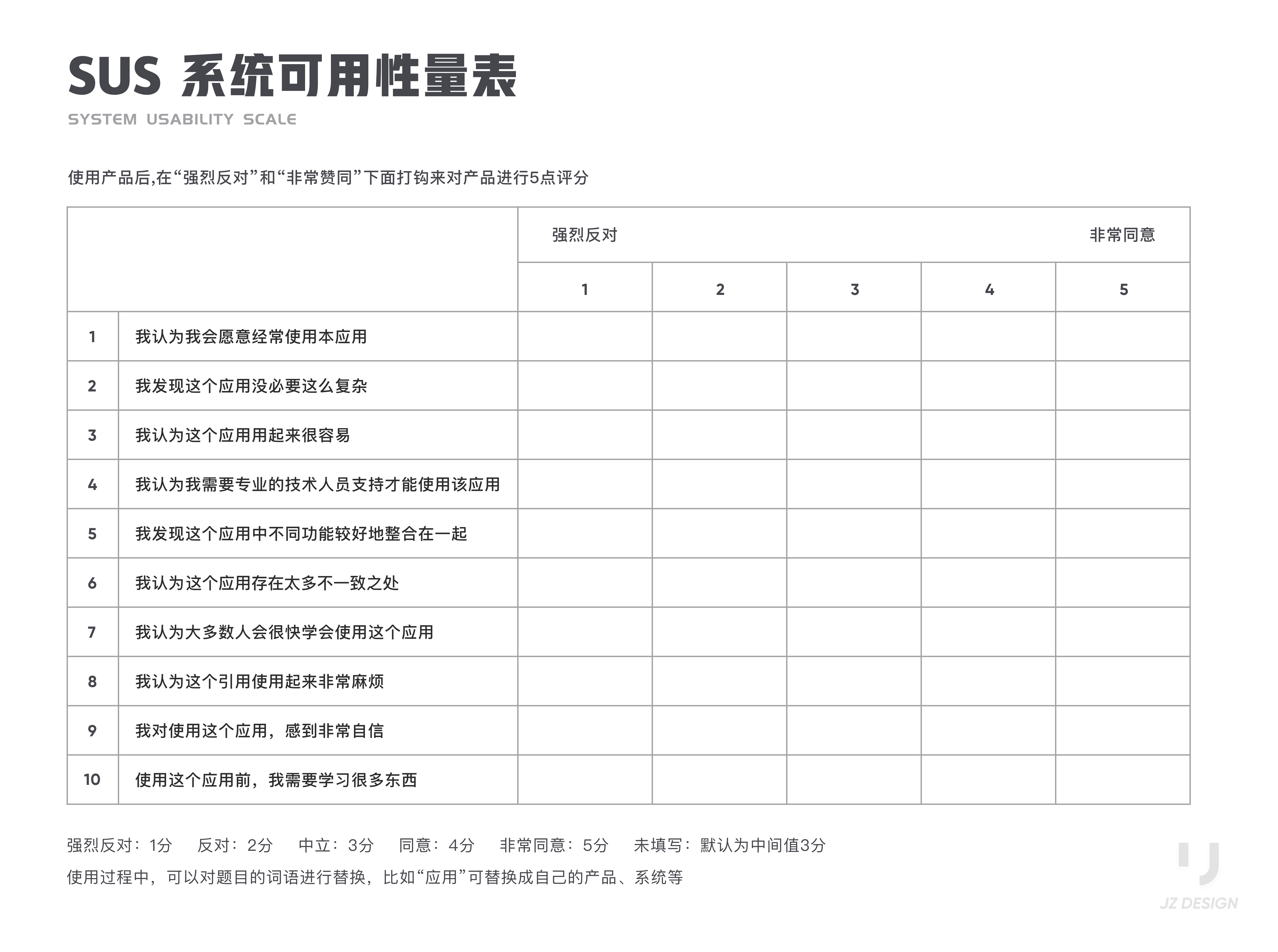
翻译过后可以得到下面的中文表,参与者在使用产品后对每个题目下面打钩来对产品进行5点评分。(小伙伴们可自行保存)
2. 问题组成
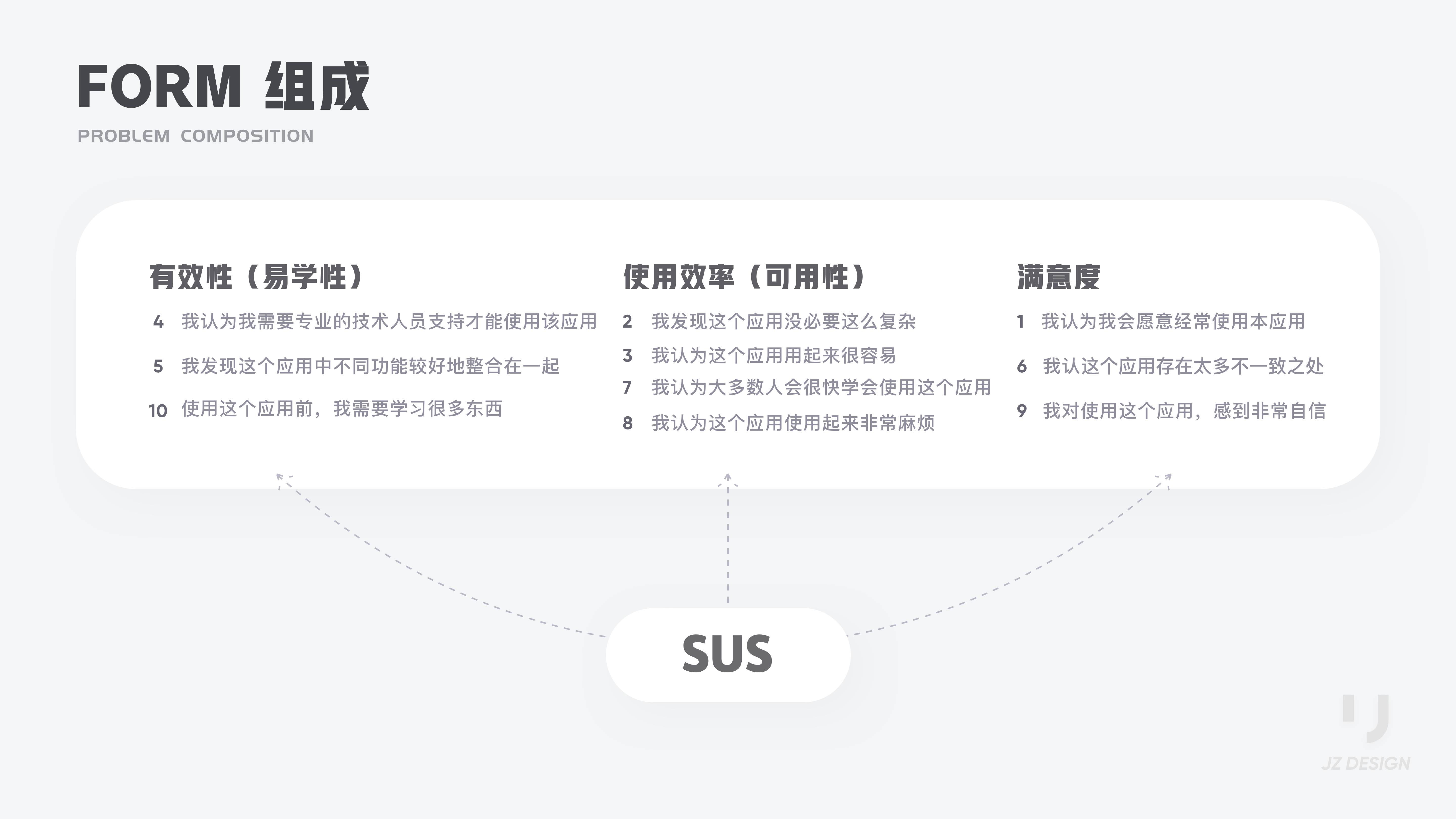
SUS提供整体可用性评估度量,由10个题目组成,奇数项为正面陈述,偶数项为反面陈述。
第4,5,10三项构成的子量表为“有效性”(Effectiveness)&“易学性”(Learnability) ;第2,3,7,8四项构成的子量表为“使用效率”(Use Efficiency)&“可用性”(Usability);第1,6,9三项构成子量表“满意度”(Satisfaction)。
3. 使用场景
SUS适用范围广泛,产品新旧版本迭代之间对比,同类型竞品之间对比,同一产品不同终端之间对比均可使用。可采用线上线下问卷调研的方式,简单高效的采集真实用户反馈。避免在初期过早的关注细节。

4. 如何使用
当收集好用户问卷反馈过后,步骤如下:
1. 对于奇数序号的问题,将其得分减1;(比如第1题分数为4,得分为4-1=3分)
2. 对于偶数序号的问题,将其得分被5减去;(比如第2题分数为3,得分为5-3=2分)
3. 将所有问题最后的得分加在一起,然后乘以2.5;(每个题目的得分范围记为0~4,最大值为40,SUS可用性得分的范围在0~100,换算后乘以2.5)
4. 计算出的结果即为产品的SUS可用性得分。

Tips 注意事项:
1. 填写之前不要进行总结或讨论;
2. 应当要求用户快速完成各个题目,不要过多思考;
3. 第二题和第六题对于参与者可能难以理解,需要解释清楚;
4. 如果用户因为某些原因无法完成其中某个题目,就视为用户在该题上选择了中间值。
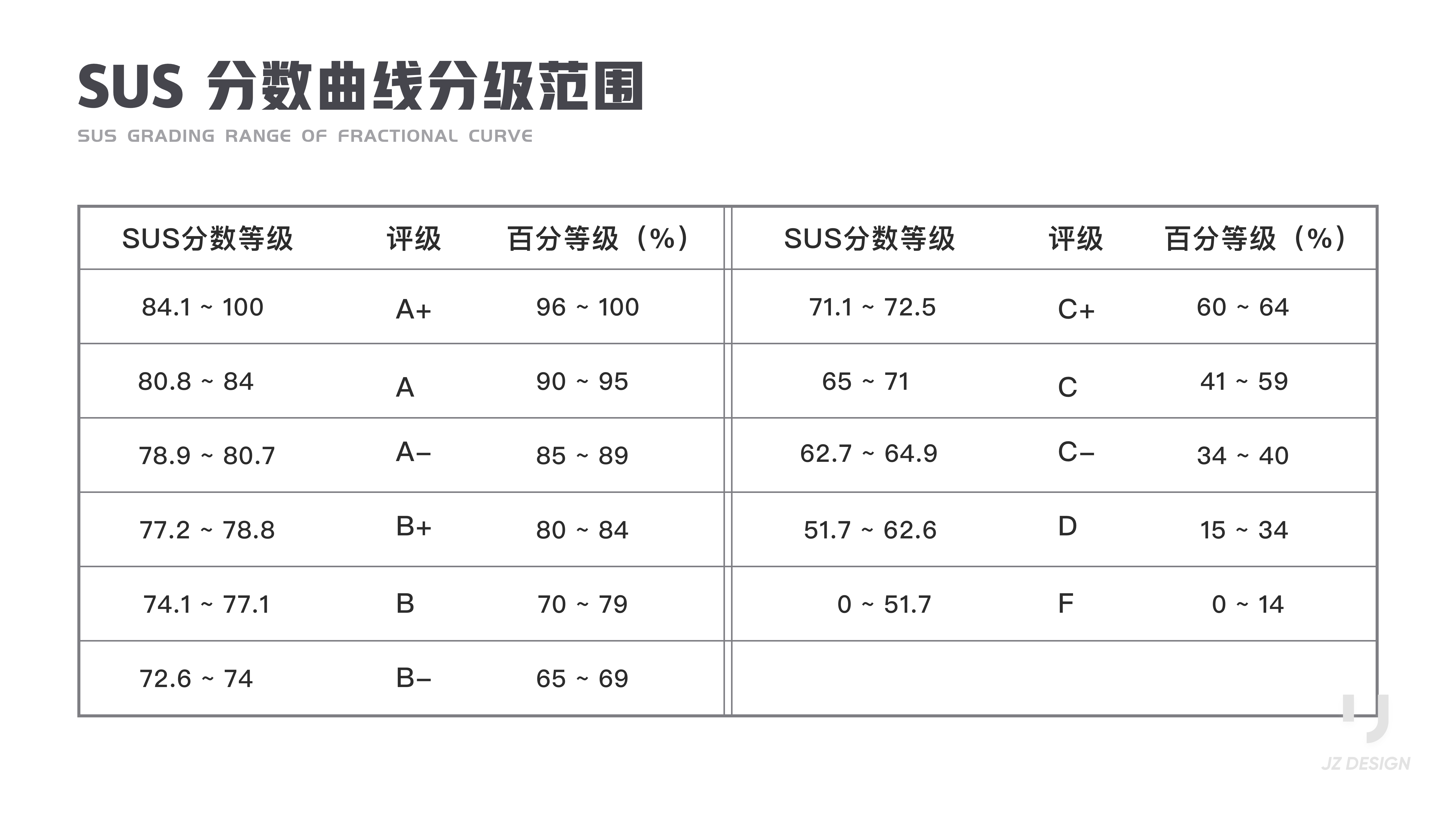
SUS分数等级与百分等级的区别:

我将其翻译过后得到中文表,可以大体上感知得出的SUS分数对应的用户可接受范围。
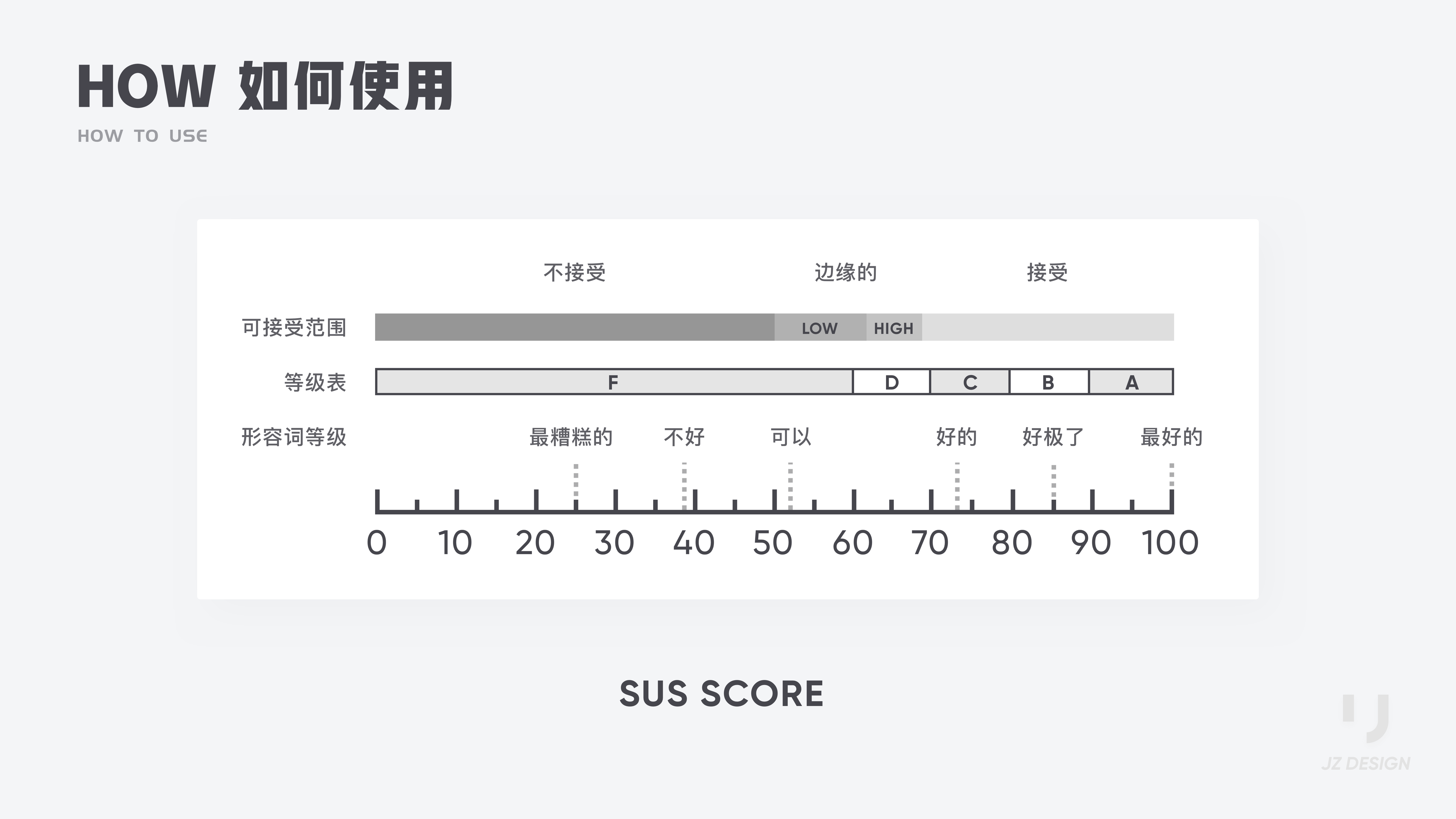
更加细化的SUS用户感知,可参照SUS分数曲线分级范围表:
注意到这里SUS分数等级与百分等级的区别。对照SUS分数曲线分级范围表,如果你的SUS分数为68,说明你的产品比市面上50%的产品可用性要好。也就是说这个产品的用户体验算是合格了,表明需要进行较小的改进。50%中值点对应SUS分数68。((59-41)/ (71-65)= 3 故中值点为65+10/3≈68 ,68分是均值,因此对应百分比是50%。)
5. SUS的优点
1. 量表公开免费,题目简单,只需参与者打分,实施便捷,操作简单;
2. 适用范围广泛,产品初期测试验证,竞品分析,新旧版本对比等等;
3. 研究证明SUS在样本量有限时,可以最快达到效果,可信度系数高;
4. 快速宏观有效区分可用系统(产品)和不可用系统(产品),避免在初期过早的关注细节;
5. 当团队内产生分歧时,SUS让更多的人员参与代替少数意见领袖说了算的形式,定量不追求定性。
6. 小样本量时依然呈现高度的内部一致性,产生真实可靠的反馈结果。
蓝蓝设计建立了UI设计分享群,每天会分享国内外的一些优秀设计,如果有兴趣的话,可以进入一起成长学习,请扫码ben_lanlan,报下信息,会请您入群。欢迎您加入噢~~希望得到建议咨询、商务合作,也请与我们联系。
分享此文一切功德,皆悉回向给文章原作者及众读者.
免责声明:蓝蓝设计尊重原作者,文章的版权归原作者。如涉及版权问题,请及时与我们取得联系,我们立即更正或删除。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务