简而言之:今年是人工智能 (AI) 接管用户体验 (UX) 的一年。在本文中,我将解释其中的原因,并更新我使用人工智能进行用户体验研究的方法,重点介绍 ChatGPT 的深度研究功能如何显著加速定性研究分析。
(注意:我将使用术语“AI”、“genAI”和“model”作为“生成性 AI”的简写,主要指大型语言模型 (LLM),即创建文本的特定类型的生成性 AI。)
十个月前,我在 Medium 上发表了一篇关于AI 用户体验的原创文章,之后它迅速蹿红,阅读量达数千次,远超本博客迄今为止的任何其他文章。但在生成式人工智能领域,十个月就像十年狗年;日新月异的变化速度已经让那篇文章的部分内容显得过时。
因此,当我的母校伦敦大学城市圣乔治学院人机交互设计系联系我,邀请我在他们的年度会议上发言时,我抓住了这个机会,重新开始我对这个学科的兴趣,尤其是当我的老教授透露他们联系我的部分原因是我的 Medium 文章很受欢迎时。
这是我对 UX 的 AI 的第二次看法,已更新至 2025 年,并涵盖了我在 HCID 2025 会议上的演讲(即使是我自己这么说,这次演讲也进行得相当顺利)。

2024年初,当我开始在工作中使用人工智能时,我感觉自己就像一位勇敢的探险家,踏入了陌生的领域。诚然,人工智能已经存在了一段时间,我们大多数人也只是在家里用它来制作储藏室菜谱或视觉效果图。但我们中很少有人有机会让人工智能真正地重塑我们的工作,这主要是因为“人工智能会以你给它的任何东西为食”的数据隐私问题,以及由此产生的对人工智能用于工作的严格禁令。

但2024年是私有AI的黎明。最终,像OpenAI和Anthropic这样的提供商“封锁”了他们的法学硕士课程,以确保其数据不会泄露,从而为像我这样的机构打开了以订阅方式使用私有AI的大门。
2025年即将到来,尼尔森诺曼集团的一项研究告诉我,用户体验专业人士是有史以来最重度的人工智能用户之一。这项研究得出的一项关键统计数据显示,如今用户体验专业人士使用法学硕士(LLM)的比例是其他样本职业的750倍之多!
你有一把锤子,但你看到的并非都是钉子。从学习作业作弊(说实话,正在读这篇文章的HCID/UX学生,如果你尝试过用AI生成用户访谈记录——请停止吧),到一位不幸的音乐爱好者向Nick Cave发送了一首“模仿Nick Cave风格”的ChatGPT歌曲,激怒了他,在很多情况下,使用AI都不是好主意。

媒体喜欢夸大此类故事,随着时间的推移,这在时代精神中形成了一种层次化的“感觉”,即无论人工智能应用于何处,它都是无用或有害的。
我不同意。

因为我们可以用这把锤子敲出一些钉子。GenAI 的局限性和功能与某些类型的用户体验研究的局限性和要求非常匹配。具体来说:
女士们、先生们、朋友们,这就是用户体验设计师们热爱人工智能的原因。它与我们完美契合,并且是真正有用的工具。除了数据隐私限制(现已基本解决)之外,业界对使用人工智能没有任何争议*。只要你的研究报告写得好,并且提供了所需的数据,没有人会在意它是否由人工智能生成。
*然而,关于人工智能的伦理问题绝对应该引发更多争议。我个人对用户体验行业对此的关注如此之少感到困惑,并将继续通过强调人工智能技术过去和现在的伦理缺陷来引发争议。
无论如何,继续介绍菜谱。
我给你举一个真实案例,关于一个用户体验研究,我最近在一个项目中用到了人工智能来分析用户数据。所有身份信息都是匿名的。
我正在使用 ChatGPT Enterprise——一个私密的“隔离”版本,配备了最新的深度研究功能。这是OpenAI 于 2025 年 2 月推出的一款专业 AI“代理” ,号称“非常适合从事高强度知识工作的人”。

如果您无法访问 Enterprise,您可以通过 20 美元的 ChatGPT Plus 订阅获得 Deep Research(不过,据我所知,您的数据不会被“隔离”)。
我的 2025 方法与之前的方法相同,分为三个步骤:
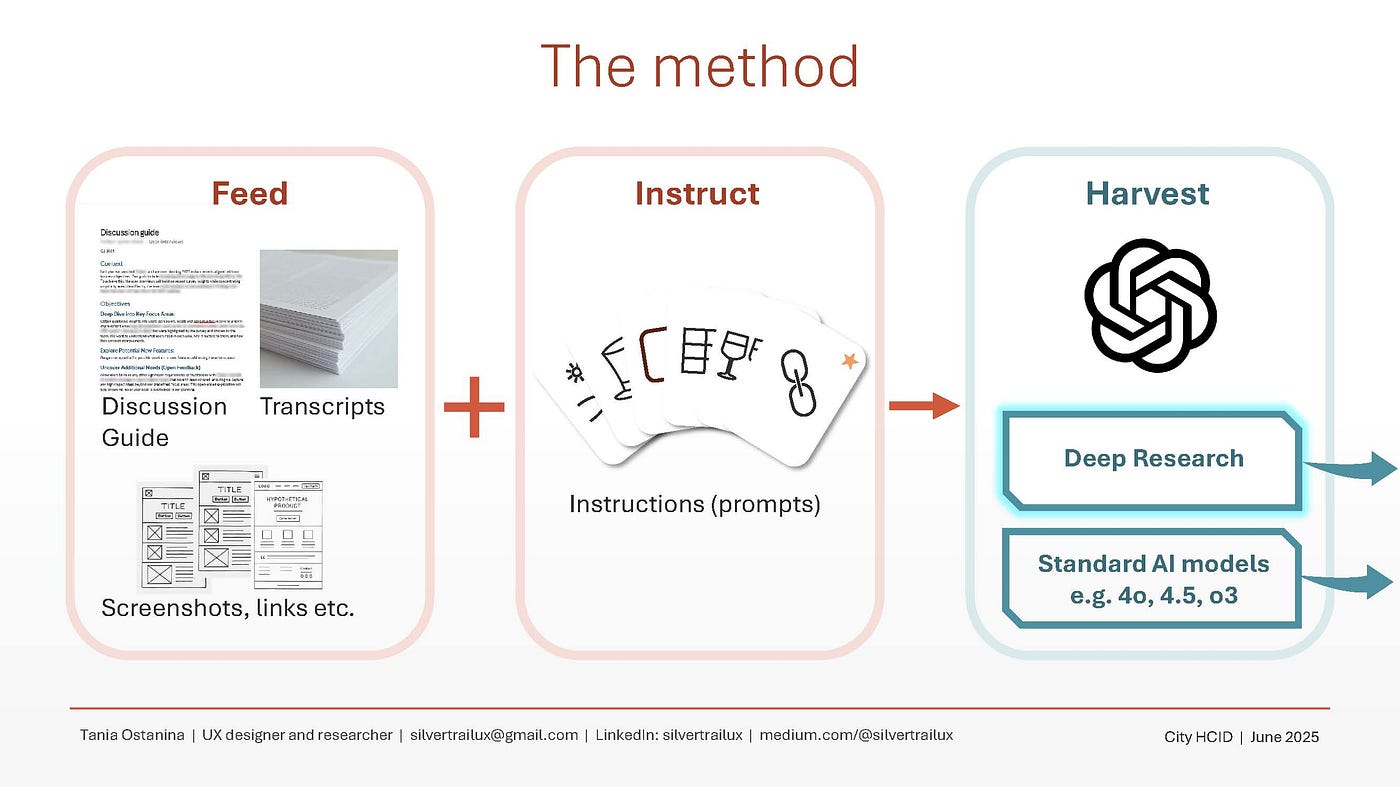
Deep Research 的优点在于它可以处理大量数据,并且比大多数传统模型(如 4o、Claude 3.7 Sonnet 等)具有更高的准确度。正如我所发现的,虽然你可以向其输入诸如访谈记录和原型截图之类的文档,但你也可以告诉它锚定到一个特定的文档,并让该文档决定模型思考和分析的方向。
在我的案例研究中,该文档是讨论指南/研究计划。

讨论指南通常由用户体验师与产品经理合作创建,通常包含以下内容:
那么,你把访谈记录、截图和讨论指南输入到了模型中。你该如何告诉模型如何处理这些内容呢?
深度研究与传统模型的一个关键区别在于,深度研究消除了大量的反复沟通。您只需进行一次操作,在回答几个澄清问题后,模型就会开始执行其“任务”,根据您的指示生成一份高度详细的报告。您只有一次提示机会,因此最好确保您的提示符合要求。

我的提示方法与我在2024年的文章中基本相同:使用便捷的提示卡组来构建提示。我不会在这里再次介绍所有提示技巧,但您可以参考那篇文章来了解更多详情。
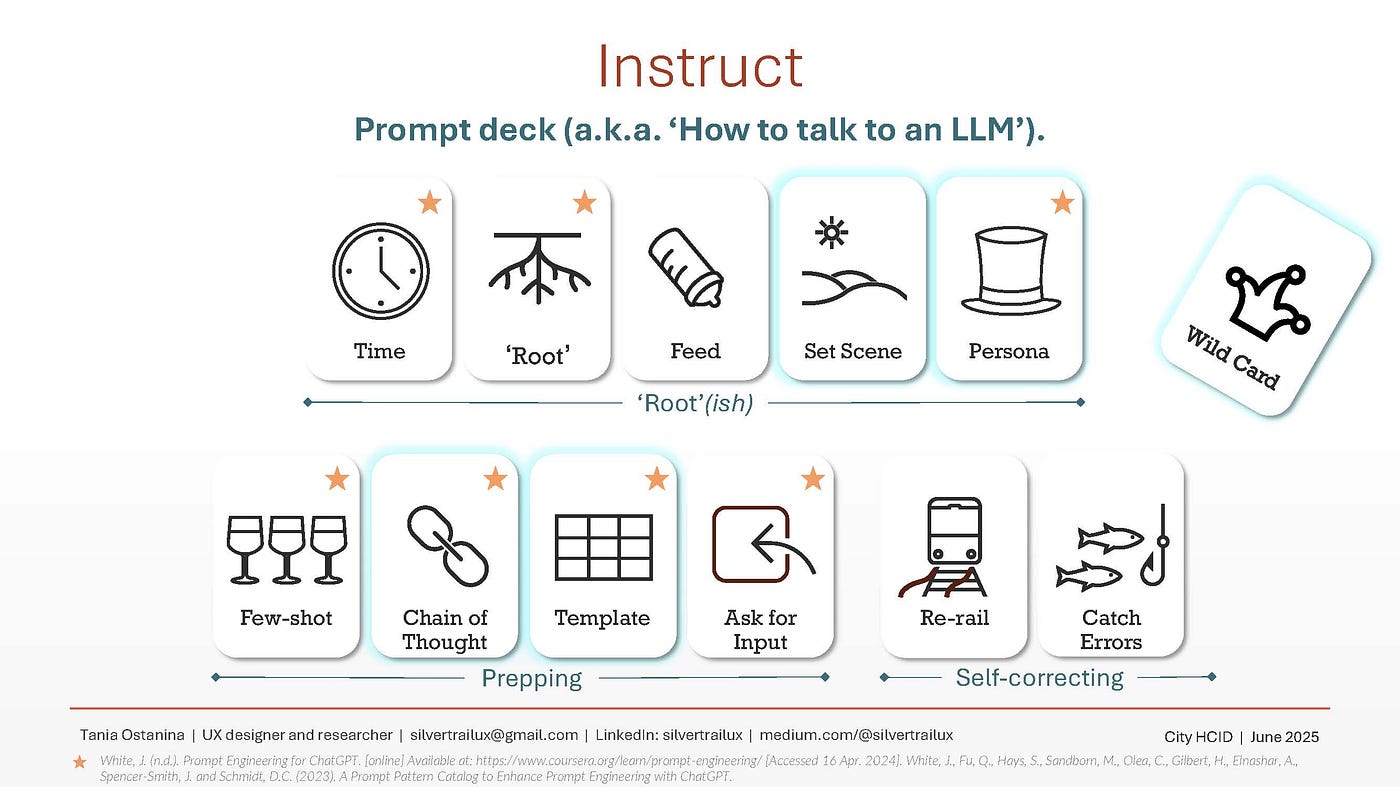
然而,一些提示“卡片”与其他卡片的权重发生了变化。以下是目前为止最有用的“卡片”:

解释研究目的、针对哪家公司和产品、用户是谁、模型将收到哪些文档;如果有的话,将其锚定到您的关键文档上(在本例中为讨论指南)。

描述你希望模型扮演的角色,例如“在一家科技公司(X 公司)工作的世界领先的用户体验研究员,为英国的一家数字信息和分析产品公司工作[职业]。 ”

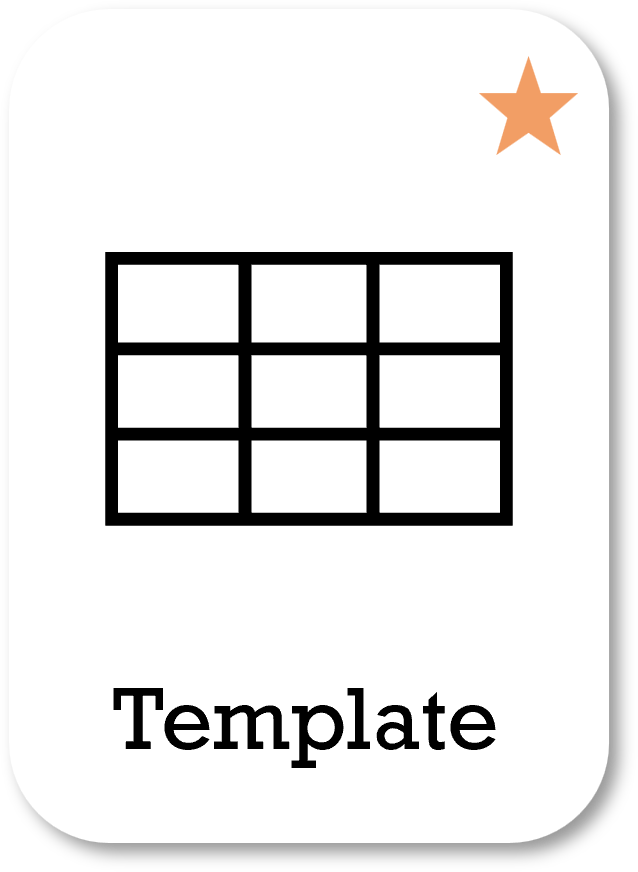
告诉AI如何构建其输出仍然是关键技术之一。您可以告诉它遵循讨论指南的结构(如果相关),或者给它一个包含所有标题的示例模板。

这项极其实用的技术如今已被人工智能工程师广泛应用。简单来说,如果你让人工智能解释它为什么得出某个结论,它得出的结论的准确性就会提高。

一位同事想出了这个主意。在我公司的许多用户研究中,包括这个例子,我们已经预设了想要从用户那里发现什么的框架。但是,如果用户说了一些我们意想不到的话怎么办?如果你不要求模型发现意想不到的事情,它就找不到。你应该自己寻找这些异常,但为什么不也让模型思考一下呢?

**这让我想起了OpenAI 发布的一段搞笑又令人毛骨悚然的视频:两个视觉/语音 AI 助手正在与一位人类主持人交谈,而另一个人则走到他身后,露出兔耳朵。两位助手都无视兔耳朵,直到明确提示。

输入你的题目和文档后,选择“深度研究”并按下“提交”按钮,然后给自己倒杯咖啡。根据“任务”的复杂程度,AI 生成所需的报告可能需要长达一小时。在我的案例研究中,这大约需要 30 分钟。
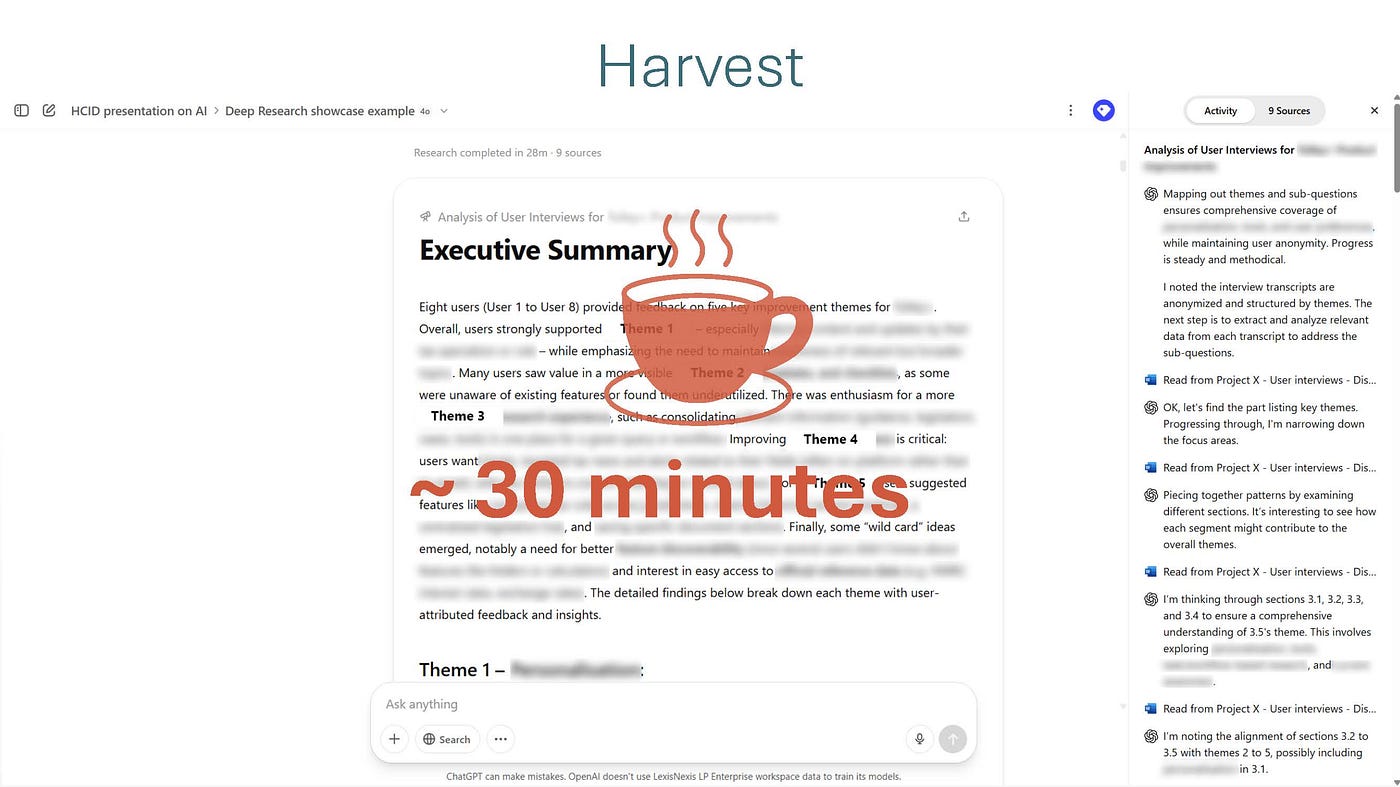
太棒了,你拿到了报告,足足50页!以下是整个过程中最无聊的部分:
!检查!每一个!字!!!
虽然深度研究的准确率高于大多数模型,但远未达到 100%,而且它产生的幻觉看起来尤其令人信服。所以,不要相信它。人工智能至今仍是一个热切但缺乏经验的助手,其工作必须接受审核。只有你,作为“知情人”,才拥有专业知识和解读能力,能够理解用户访谈中的真实情况,否决人工智能的错误结论,并发现任何“兔子耳朵”,即使你设置了“万能牌”,人工智能也可能遗漏了。
深度研究的一个巧妙功能是右侧面板,你可以在那里看到它是如何一步步得出结论的。最奇怪的幻觉可能会在这里出现,而且很搞笑。我注意到,这类幻觉很少出现在最终报告中,因为深度研究功能中已经内置了“思维链”流程。

重要提示:由于深度研究每次只允许执行一项任务,而不是来回对话,因此您无法在与AI对话时进行更正。请使用传统方法,将报告下载到Word中。
修改完成后,您可以将 Word 报告上传回 ChatGPT,让它将 50 页的文档精简成简洁的 PowerPoint 风格演示文稿。这是最简单的步骤:只需使用“模板”提示技术,并结合传统的 AI 模型(例如 4o、o3 等)即可。
根据我的经验,传统的人工智能模型在从访谈记录中提取用户原话方面表现糟糕,它们只会选择进行解释。相信我,我什么方法都试过了!相比之下,Deep Research 的引文直接引用了原文,因此用户引文更容易进行交叉核对。我仍然建议手动检查,尤其是那些最终报告会用到的内容。

因此,深度研究花了大约 30 分钟来编写分析报告。即使考虑到人工参与快速撰写、文档准备、检查和修改的时间,这也比手动完成整个分析过程要快——而且绝对比我之前依赖传统 AI 模型的方法要快。
需要注意的是:你可能很容易将分析工作完全外包给深度研究,而跳过检查步骤。这将是一个大错误。最终,如果深度研究出错,承担风险的是你,而不是人工智能。即使模型越来越先进,保持警惕并在出错的地方进行干预仍然至关重要。
在我的HCID会议演讲中,这是我最喜欢的幻灯片。告诉听众一堆有用、可操作的信息,然后让他们把它们扔进垃圾桶,这其中有一种令人愉悦的反常之处。
但这就是人工智能领域的现实。事物每周都在变化,跟上潮流的唯一方法就是与时俱进。例如,我的演讲中还没有提到代理人工智能 (Agentic AI),但在撰写本文时,它是 2025 年规模最大(也是最模糊的概念!)的人工智能盛事。如果我在为 UX v3.0 撰写人工智能文章时,很可能会谈论代理人工智能。
或许不是!谁知道呢!

兰亭妙微(www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的大数据可视化界面设计、B端界面设计、桌面端界面设计、APP界面设计、图标定制、用户体验设计、交互设计、UI咨询、高端网站设计、平面设计,以及相关的软件开发服务,咨询电话:01063334945。我们建立了一个微信群,每天分享国内外优秀的设计,有兴趣请加入一起学习成长,咨询及进群请加蓝小助微信ben_lanlan。