

包括单行注释和块级注释。
// alert(“HelloWorld!”)
/*
这是一个
多行的
块级注释
*/
“use strict”;。
ECMA-262描述了一组具有特定用途的关键字和一组不能用做标识符的保留字。
var message,当然了,也可以直接在定义的时候对变量做一个初始化,例如var message = ‘hi’ ;
var message = ‘hi’ ;
message = 100 ; //有效,但不推荐
//这个例子代表变量message一开始保存了一个字符串“hi”,然后该值又被一个数字值100取代了。
function test(){
var message = ‘hi’ ; //局部变量
} ;
test();
alert(message); //错误
//为什么是错误?
//这里,变量message是在函数里用var定义的,当函数被调用时,就会创建该变量并为其赋值。而在此之后,这个变量会立即被销毁。所以在执行alerat()那行代码的时候message已经被销毁了,因此报错。
那么,该怎么解决呢?
function test(){
message = ‘hi’ ; //局部变量
} ;
test();
alert(message); // hi
//在函数内部不用var会创建全局变量。
//但我们并不提倡这种做法,因为局部作用域中定义的全局变量很难去维护。
//所以我们应该选择在开始就定义好所有的变量。转载: 原创作者: 呱?!

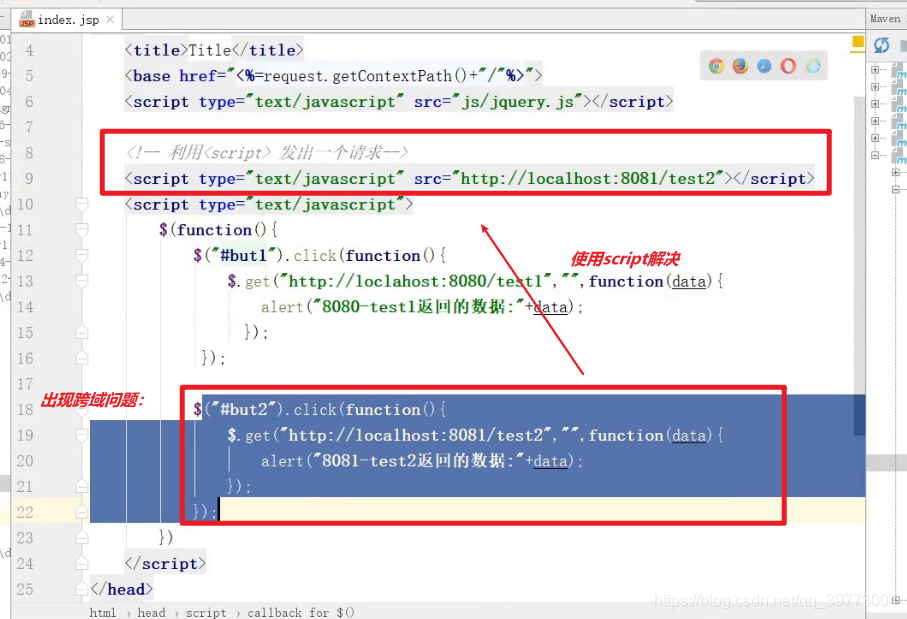
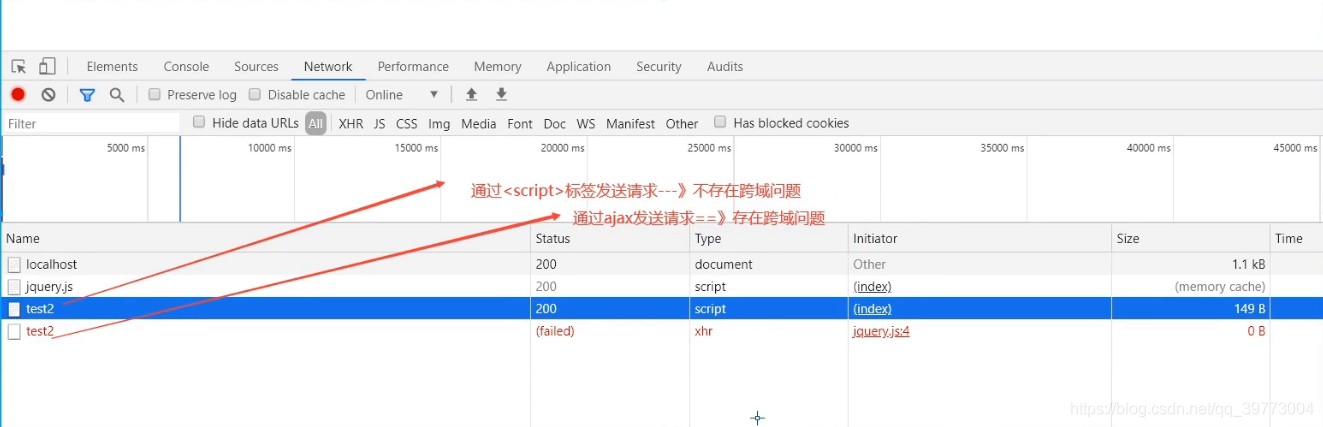
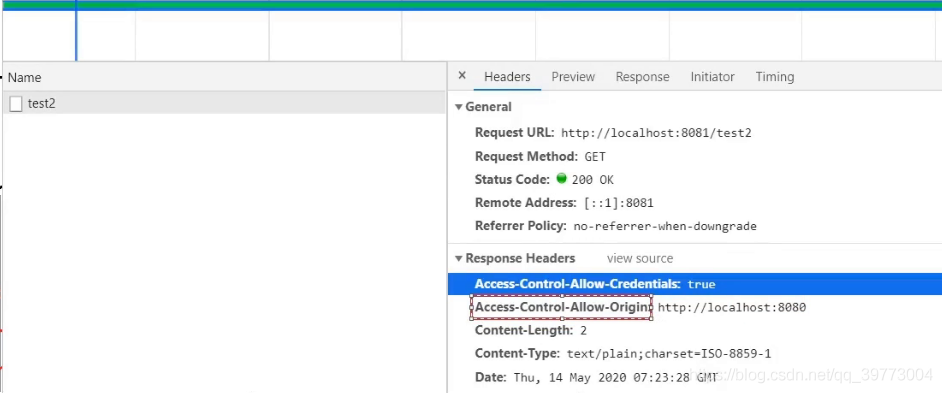
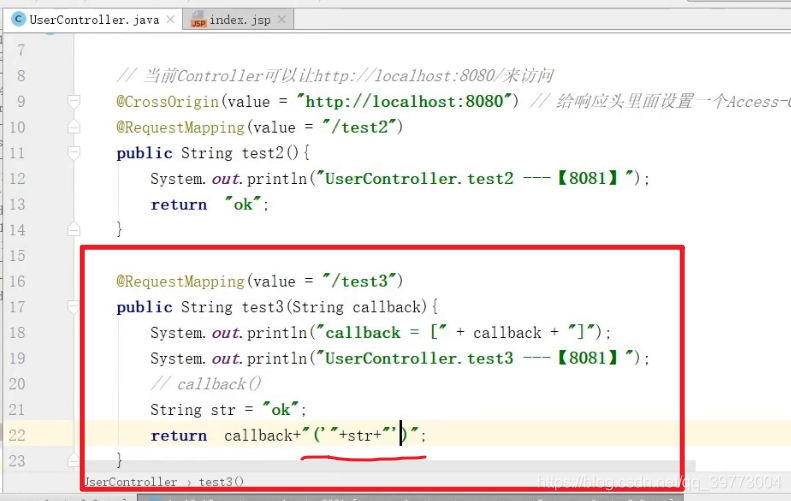
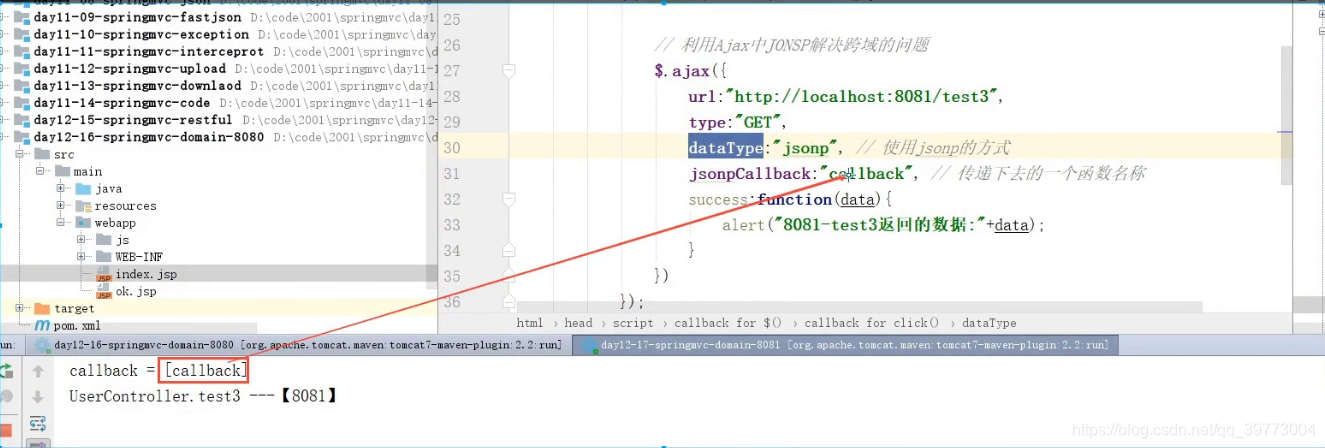
即:给响应头设置一个Access-Control-Allow-Origin属性

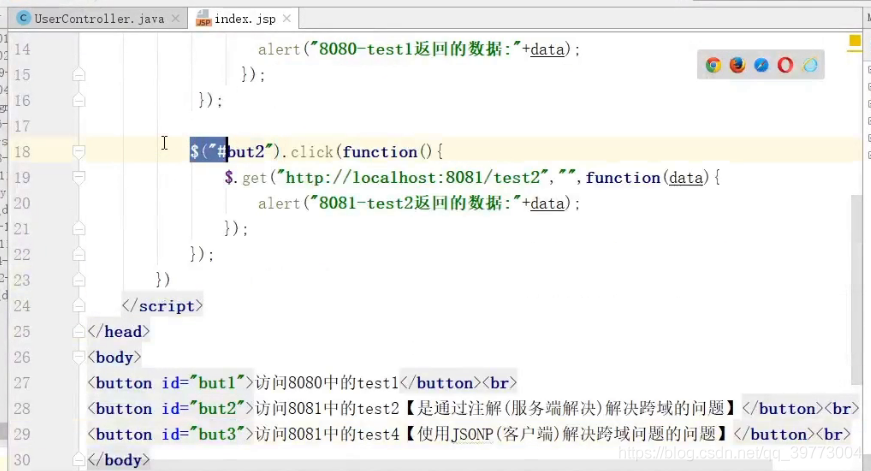
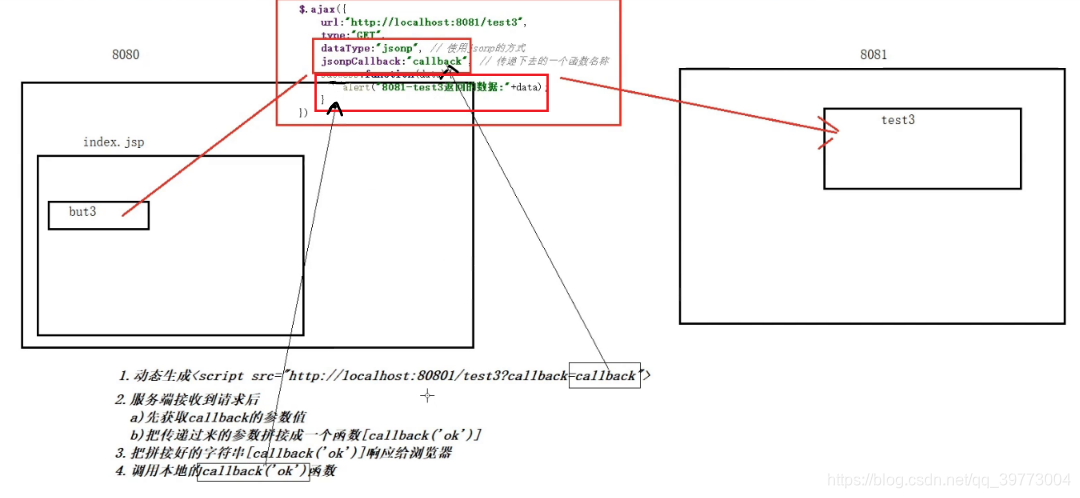
将callback当成一个参数传递下去
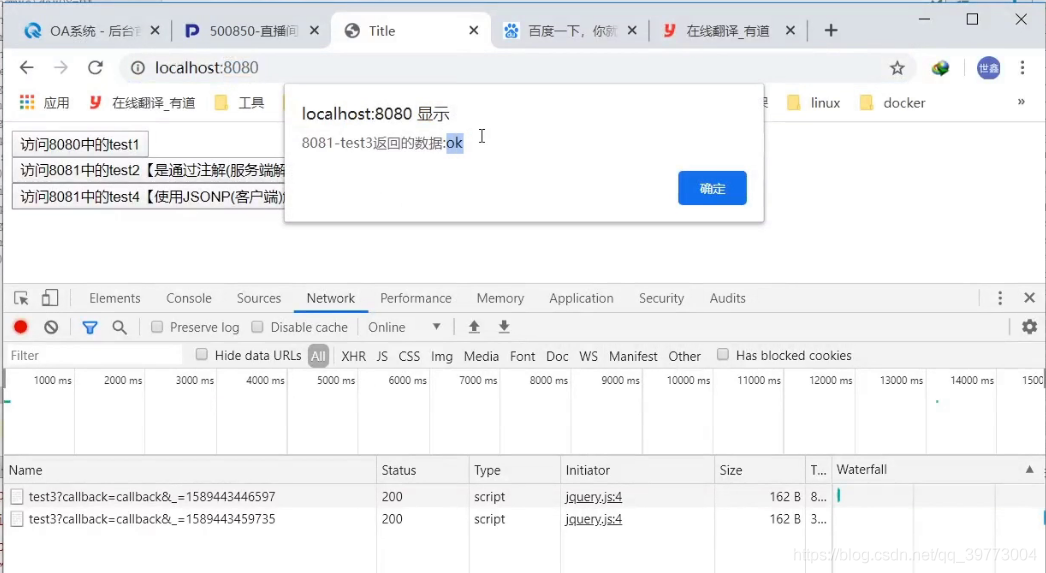
前后端运行结果

组件说明:
实现 Result 结果页。
效果展示:

实现的功能:
<template> <div> <el-result :item="item" @on-cancel="cancel" @on-submit="submit" /> </div> </template> <script> export default { name: "Result", data(){ return{ item: { title: '提交成功', submitText:"继续填写", cancelText:"退出应用", status:"success" }, } }, created(){ let item = this.$route && this.$route.query; if(item.status==='fail'){ this.item = { title: '提交失败,请联系开发人员', submitText:"重新填写", cancelText:"退出应用", status:"fail" } } }, methods:{ cancel(){ dd.biz.navigation.close({ onSuccess : function(result) { /*result结构
{}
*/ }, onFail : function(err) {} }) }, submit(){ this.$router.go(-1) } } } </script>
| 属性 | 说明 | 类型 | 默认值 |
|---|---|---|---|
| item | 页面展示的静态内容集合 | Array | [] |
| title | 描述标题 | String | – |
| submitText | 提交按钮文本 | String | – |
| cancelText | 取消按钮文本 | String | – |
| status | 输入值字段 | String | – |
| on-cancel | 取消按钮事件 | Function | – |
| on-submit | 提交按钮事件 | Function | – |
Result.vue
文件路径:share/result/Result.vue
<template> <div class="cm-tx-c cm-mt-08 cm-p-02"> <el-image :src="item.status==='success'?successBg:failBg" style="width: 250px" > <div slot="placeholder" class="image-slot"> 图片加载中<span class="dot">...</span> </div> </el-image> <div :class="item.status==='success'?'success-title':'fail-title'">{{item.title}}</div> <div>{{item.describe}}</div> <div class="cm-flex cm-jc-sa"> <div @click="cancel()" class="cm-btn-cancel">{{item.cancelText}}</div> <div @click="submit()" class="cm-btn-submit">{{item.submitText}}</div> </div> </div> </template> <script> import successBg from '../images/result-success.png'; import failBg from '../images/result-fail.png'; export default { name: "ElResult", data(){ return{ successBg, failBg } }, props:{ item:{ type:Object, default:{} } }, created(){ }, methods:{ cancel(){ this.$emit('on-cancel',''); }, submit(){ this.$emit('on-submit',''); } } } </script> <style scoped> .success-title{ padding: 0.4rem; font-size: 0.35rem; color:#15bc83; } .fail-title{ padding: 0.4rem; font-size: 0.35rem; color:#f25643; } </style> 6转载 作者:杏子_1024 2020-10-19 09:24:19 分类专栏: # Vue通用组件封装
开发中,遇到数组排序的需求很频繁,这篇文章会介绍几个常见排序思路。
如果要从大到小排列,则 while(arr[n] > arr[n - interval] && n > 0) 。
// 希尔排序算法 function xier(arr){ var interval = parseInt(arr.length / 2);//分组间隔设置 while(interval > 0){ for(var i = 0 ; i < arr.length ; i ++){ var n = i; while(arr[n] < arr[n - interval] && n > 0){ var temp = arr[n]; arr[n] = arr[n - interval]; arr[n - interval] = temp; n = n - interval; } } interval = parseInt(interval / 2); } return arr; } // Array var arr = [10, 20, 40, 60, 60, 0, 30] // 打印排序后的数组 console.log(xier(arr))//[0, 10, 20, 30, 40, 60, 60]
一堆数组排序
// Array var arr = [10, 20, 40, 60, 60, 0, 30] // 排序方法 arr.sort(function(a,b){ /*
* return b-a; —> 降序排序
* return a-b; —> 升序排列
*/ return a-b; })//括号里不写回调函数则默认按照字母逐位升序排列 // 打印排序后的数组 console.log(arr)//[0, 10, 20, 30, 40, 60, 60]
对象数组排序(数组套对象)
//对象数组排序 var arr = [ {name:'syy', age:0}, {name:'wxy', age:18}, {name:'slj', age:8}, {name:'wj', age:20} ]; // 排序方法 function compare(property) {//property:根据什么属性排序 return function(a,b){ var value1 = a[property]; var value2 = b[property]; /*
* value2 - value1; ——> 降序
* value1 - value2; ——> 升序
*/ return value1 - value2;//升序排序 } } // 打印排序后的数组 console.log(arr.sort(compare('age'))) /*
0: {name: "syy", age: 0}
1: {name: "slj", age: 8}
2: {name: "wxy", age: 18}
3: {name: "wj", age: 20}
*/
特点:简单,但非常浪费内存,几乎不用。
桶中出现的数组元素都做个标记 1,然后将桶数组中有 1 标记的元素依次打印。
// Array var arr = [] // 每个数组项做标记(1) for(let i = 0; i < arr.length; i++) { let key = arr[i] arr[key] = 1 } // 遍历打印出每项 for(let j in arr) { debugger console.log(j) }
性能:一般(需要每项进行比较)。
每一趟找出最大的值。
// Array var arr = [10, 20, 40, 60, 60, 0, 30] /*
* 总共比较次数为arr.length-1次
* 每次的比较次数为arr.length-1次
* 依次递减
*/ var temp;//交换变量标识 // 两层for分别表示当前项与第二项 for(let i = 0; i < arr.length - 1; i++) { for(let j = 0; j < arr.length - 1; j++) { // 如果当前项大于第二项(后一项)则交换 if(arr[j] > arr[j+1]) { temp = arr[j] arr[j] = arr[j+1]; arr[j+1] = temp; } } } // 打印排序后的数组 console.log(arr)//[0, 10, 20, 30, 40, 60, 60]
性能:一般(需要每项进行比较)。
假定某个位置的值是最小值,与冒泡排序类似。
// Array var arr = [10, 20, 40, 60, 60, 0, 30] var temp;//交换变量标识 // 两层for分别表示当前项与第二项 for(let i = 0; i < arr.length - 1; i++) { for(let j = i + 1; j < arr.length; j++) { // 假设第二项是最小值(是则交换/否则继续比较) if(arr[i] > arr[j]) { temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } } } // 打印排序后的数组 console.log(arr)//[0, 10, 20, 30, 40, 60, 60]
// Array var arr = [10, 20, 40, 60, 60, 0, 30] // 排序算法 for(var i = 0; i < arr.length; i++) { var n = i; while(arr[n] > arr[n+1] && n >= 0) { var temp = arr[n]; arr[n] = arr[n+1]; arr[n+1] = temp; n--; } } // 打印排序后的数组 console.log(arr)//[0, 10, 20, 30, 40, 60, 60]
作者:王佳斌
了解拷贝背后的过程,避免不必要的错误,Js专题系列之深浅拷贝,我们一起加油~
当我们在操作数据之前,可能会遇到这样的情况:
当我们遇到类似需要场景时,首先想到的就是拷贝它,殊不知拷贝也大有学问哦~
下面简单的例子,你是否觉得熟悉?
var str = 'How are you'; var newStr = str; newStr = 10 console.log(str); // How are you console.log(newStr); // 10
大家都能想到,字符串是基本类型,它的值保存在栈中,在对它进行拷贝时,其实是为新变量开辟了新的空间。 str和newStr就好比两个一模一样的房间,布局一致却毫无关联。
var data = [1, 2, 3, 4, 5]; var newData = data; newData[0] = 100; console.log(data[0]); // 100 console.log(newData[0]); // 100
类似的代码段,但这次我们使用数组这个引用类型举例,你会发现修改赋值后的数据,原始数据也跟着改变了,这显然不满足我们的需要。本篇文章就来聊一聊引用数据拷贝的学问。
如果大家对Js的数据类型存在着疑问,不妨看看《JavaScript中的基本数据类型》

拷贝的划分都是针对引用类型来讨论的,浅拷贝——顾名思义,浅拷贝就是“浅层拷贝”,实际上只做了表面功夫:
var arr = [1, 2, 3, 4]; var newArr = arr; console.log(arr, newArr); // [1,2,3,4] [1,2,3,4] newArr[0] = 100; console.log(arr, newArr) // [100,2,3,4] [100,2,3,4]
不发生事情(操作)还好,一旦对新数组进行了操作,两个变量中所保存的数据都会发生改变。
发生这类情况的原因也是因为引用类型的基本特性:
数组中的slice和concat都会返回一个新数组,我们一起来试一下:
var arr = [1,2,3,4]; var res = arr.slice(); // 或者 res = arr.concat() res[0] = 100; console.log(arr); // [1,2,3,4]
这个问题这么快就解决了?虽然对这一层数据进行了这样的的处理后,确实解决了问题,但!
var arr = [ { age: 23 }, [1,2,3,4] ]; var newArr = arr.concat(); arr[0].age = 18; arr[1][0] = 100; console.log(arr) // [ {age: 18}, [100,2,3,4] ] console.log(newArr) // [ {age: 18}, [100,2,3,4] ]
果然事情没有那么简单,这也是因为数据类型的不同。
S 不允许我们直接操作内存中的地址,也就是说不能操作对象的内存空间,所以,我们对对象的操作都只是在操作它的引用而已。
既然浅拷贝达不到我们的要求,本着效率的原则,我们找找有没有帮助我们实现深拷贝的方法。

数据的方法失败了,还有没有其他办法?我们需要实现真正意义上的拷贝出独立的数据。
这里我们利用JSON的两个方法,JSON.stringify(),JSON.parse()来实现最简洁的深拷贝
var arr = ['str', 1, true, [1, 2], {age: 23}] var newArr = JSON.parse( JSON.stringify(arr) ); newArr[3][0] = 100; console.log(arr); // ['str', 1, true, [1, 2], {age: 23}] console.log(newArr); // ['str', 1, true, [100, 2], {age: 23}]
这个方法应该是实现深拷贝最简洁的方法,但是,它仍然存在问题,我们先来看看刚才都做了些什么:
arr
JSON 字符串
值或对象
理解:
我们可以理解为,将原始数据转换为新字符串,再通过新字符串还原为一个新对象,这中改变数据类型的方式,间接的绕过了拷贝对象引用的过程,也就谈不上影响原始数据。
限制:
这种方式成立的根本就是保证数据在“中转”时的完整性,而JSON.stringify()将值转换为相应的JSON格式时也有缺陷:
所以当我们拷贝函数、undefined等stringify转换有问题的数据时,就会出错,我们在实际开发中也要结合实际情况使用。
举一反三:
既然是通过改变数据类型来绕过拷贝引用这一过程,那么单纯的数组深拷贝是不是可以通过现有的几个API来实现呢?
var arr = [1,2,3]; var newArr = arr.toString().split(',').map(item => Number(item)) newArr[0] = 100; console.log(arr); // [1,2,3] console.log(newArr); // [100,2,3]
注意,此时仅能对包含纯数字的数组进行深拷贝,因为:
但我愿称它为纯数字数组深拷贝!

有的人会认为Object.assign(),可以做到深拷贝,我们来看一下
var obj = {a: 1, b: { c: 2 } } var newObj = Object.assign({}, obj) newObj.a = 100; newObj.b.c = 200; console.log(obj); // {a: 1, b: { c: 200 } } console.log(newObj) // {a: 100, b: { c: 200 } }
神奇,第一层属性没有改变,但第二层却同步改变了,这是为什么呢?
因为 Object.assign()拷贝的是(可枚举)属性值。
假如源值是一个对象的引用,它仅仅会复制其引用值。MDN传送门
既然现有的方法无法实现深拷贝,不妨我们自己来实现一个吧~
我们只需要将所有属性即其嵌套属性原封不动的复制给新变量一份即可,抛开现有的方法,我们应该怎么做呢?
var shallowCopy = function(obj) { if (typeof obj !== 'object') return; // 根据obj的类型判断是新建一个数组还是对象 var newObj = obj instanceof Array ? [] : {}; // 遍历obj,并且判断是obj的属性才拷贝 for (var key in obj) { if (obj.hasOwnProperty(key)) { newObj[key] = obj[key]; } } return newObj; }
我们只需要将所有属性的引用拷贝一份即可~
相信大家在实现深拷贝的时候都会想到递归,同样是判断属性值,但如果当前类型为object则证明需要继续递归,直到最后
var deepCopy = function(obj) { if (typeof obj !== 'object') return; var newObj = obj instanceof Array ? [] : {}; for (var key in obj) { if (obj.hasOwnProperty(key)) { newObj[key] = typeof obj[key] === 'object' ? deepCopy(obj[key]) : obj[key]; } } return newObj; }
我们用白话来解释一下deepCopy都做了什么
const obj = [1, { a: 1, b: { name: '余光'} } ]; const resObj = deepCopy(obj); obj,创建 第一个newObj
[]
0 (for in 以任意顺序遍历,我们假定按正常循序遍历)
1
obj[1]
另外请注意递归的方式虽然可以深拷贝,但是在性能上肯定不如浅拷贝,大家还是需要结合实际情况来选择。
作者: 余光
没有 switch 就没有复杂的代码块
switch很方便:给定一个表达式,我们可以检查它是否与一堆case子句中的其他表达式匹配。 考虑以下示例:
const name = "Juliana";
switch (name) {
case "Juliana":
console.log("She's Juliana");
break;
case "Tom":
console.log("She's not Juliana");
break;
}
当 name 为“Juliana”时,我们将打印一条消息,并立即中断退出该块。 在switch函数内部时,直接在 case 块使用 return,就可以省略break。
当没有匹配项时,可以使用 default 选项:
const name = "Kris";
switch (name) {
case "Juliana":
console.log("She's Juliana");
break;
case "Tom":
console.log("She's not Juliana");
break;
default:
console.log("Sorry, no match");
}
switch在 Redux reducers 中也大量使用(尽管Redux Toolkit简化了样板),以避免产生大量的if。 考虑以下示例:
const LOGIN_SUCCESS = "LOGIN_SUCCESS";
const LOGIN_FAILED = "LOGIN_FAILED";
const authState = {
token: "",
error: "",
};
function authReducer(state = authState, action) {
switch (action.type) {
case LOGIN_SUCCESS:
return { ...state, token: action.payload };
case LOGIN_FAILED:
return { ...state, error: action.payload };
default:
return state;
}
}
这有什么问题吗?几乎没有。但是有没有更好的选择呢?
从 Python 获得的启示
来自 Telmo 的这条 Tweet引起了我的注意。 他展示了两种“switch”风格,其中一种非常接近Python中的模式。
Python 没有开关,它给我们一个更好的替代方法。 首先让我们将代码从 JavaScript 移植到Python:
LOGIN_SUCCESS = "LOGIN_SUCCESS"
LOGIN_FAILED = "LOGIN_FAILED"
auth_state = {"token": "", "error": ""}
def auth_reducer(state=auth_state, action={}):
mapping = {
LOGIN_SUCCESS: {**state, "token": action["payload"]},
LOGIN_FAILED: {**state, "error": action["payload"]},
}
return mapping.get(action["type"], state)
在 Python 中,我们可以使用字典来模拟switch 。 dict.get() 可以用来表示 switch 的 default 语句。
当访问不存在的key时,Python 会触发一个 KeyError 错误:
>>> my_dict = {
"name": "John",
"city": "Rome",
"age": 44
}
>>> my_dict["not_here"]
# Output: KeyError: 'not_here'
.get()方法是一种更安全方法,因为它不会引发错误,并且可以为不存在的key指定默认值:
>>> my_dict = {
"name": "John",
"city": "Rome",
"age": 44
}
>>> my_dict.get("not_here", "not found")
# Output: 'not found'
因此,Pytho n中的这一行:
return mapping.get(action["type"], state)
等价于 JavaScript中的:
function authReducer(state = authState, action) {
...
default:
return state;
...
}
使用字典的方式替换 switch
再次思考前面的示例:
const LOGIN_SUCCESS = "LOGIN_SUCCESS";
const LOGIN_FAILED = "LOGIN_FAILED";
const authState = {
token: "",
error: "",
};
function authReducer(state = authState, action) {
switch (action.type) {
case LOGIN_SUCCESS:
return { ...state, token: action.payload };
case LOGIN_FAILED:
return { ...state, error: action.payload };
default:
return state;
}
}
如果不使用 switch 我们可以这样做:
function authReducer(state = authState, action) {
const mapping = {
[LOGIN_SUCCESS]: { ...state, token: action.payload },
[LOGIN_FAILED]: { ...state, error: action.payload }
};
return mapping[action.type] || state;
}
这里我们使用 ES6 中的计算属性,此处,mapping的属性是根据两个常量即时计算的:LOGIN_SUCCESS 和 LOGIN_FAILED。
属性对应的值,我们这里使用的是对象解构,这里 ES9((ECMAScript 2018)) 出来的。
const mapping = {
[LOGIN_SUCCESS]: { ...state, token: action.payload },
[LOGIN_FAILED]: { ...state, error: action.payload }
}
你如何看待这种方法?它对 switch 来说可能还能一些限制,但对于 reducer 来说可能是一种更好的方案。
但是,此代码的性能如何?
性能怎么样?
switch 的性能优于字典的写法。我们可以使用下面的事例测试一下:
console.time("sample");
for (let i = 0; i < 2000000; i++) {
const nextState = authReducer(authState, {
type: LOGIN_SUCCESS,
payload: "some_token"
});
}
console.timeEnd("sample");
测量它们十次左右,
for t in {1..10}; do node switch.js >> switch.txt;done
for t in {1..10}; do node map.js >> map.txt;done
clipboard.png
人才们的 【三连】 就是小智不断分享的最大动力,如果本篇博客有任何错误和建议,欢迎人才们留言,最后,谢谢大家的观看。
原文:https://codeburst.io/alternat...
代码部署后可能存在的BUG没法实时知道,事后为了解决这些BUG,花了大量的时间进行log 调试,这边顺便给大家推荐一个好用的BUG监控工具 Fundebug。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
最近在项目中遇到这样一个问题

当页面加载完毕后由于选项卡的另外两张属于display:none;状态 所以另外两张选项卡内echarts的宽高都会变成默认100*100
查阅了很多网上的案例,得出一下一些解决方案:
1:
原因很简单,在tab页中,图表的父容器div是隐藏的(display:none),图表在执行js初始化的时候找不到这个元素,所以自动将“100%”转成了“100”,最后计算出来的图表就成了100px
解决办法:
找一个在tab页的切换操作中不会隐藏的父容器,把它的宽度的具体值取出后在初始化图表之前直接赋给图表
1 $("#chartMain").css('width',$("#TabContent").width());//获取父容器的宽度具体数值直接赋值给图表以达到宽度100%的效果 2 var Chart = echarts.init(document.getElementById('chartMain')); 3 4 // 指定图表的配置项和数据 5 option = { ...配置项和数据 }; 6 7 // 使用刚指定的配置项和数据显示图表。 8 Chart.setOption(option);
2:mychart.resize() 重新渲染高度
3: 后来我想到了问题所在,既然高度是因为display:none;导致的 那大可不必设置这个属性,但是在页面渲染完毕后加上即可
所以取消了选项卡的display:none; 但在页面加载完毕后
window.οnlοad=function(){
根基id在添加css display:none;
}
即可解决,
分割线
---------------------------------------------------------------------
接下来解决一下ifram内外通讯 互相通讯赋值ifram src 和高度问题
统一资源定位符,缩写为URL,是对网络资源(网页、图像、文件)的引用。URL指定资源位置和检索资源的机制(http、ftp、mailto)。
举个例子,这里是这篇文章的 URL 地址:
https://dmitripavlutin.com/parse-url-javascript
很多时候你需要获取到一段 URL 的某个组成部分。它们可能是 hostname(例如 dmitripavlutin.com),或者 pathname(例如 /parse-url-javascript)。
一个方便的用于获取 URL 组成部分的办法是通过 URL() 构造函数。
在这篇文章中,我将给大家展示一段 URL 的结构,以及它的主要组成部分。
接着,我会告诉你如何使用 URL() 构造函数来轻松获取 URL 的组成部分,比如 hostname,pathname,query 或者 hash。
1. URL 结构
一图胜千言。不需要过多的文字描述,通过下面的图片你就可以理解一段 URL 的各个组成部分:
image
2. URL() 构造函数
URL() 构造函数允许我们用它来解析一段 URL:
const url = new URL(relativeOrAbsolute [, absoluteBase]);
参数 relativeOrAbsolute 既可以是绝对路径,也可以是相对路径。如果第一个参数是相对路径的话,那么第二个参数 absoluteBase 则必传,且必须为第一个参数的绝对路径。
举个例子,让我们用一个绝对路径的 URL 来初始化 URL() 函数:
const url = new URL('http://example.com/path/index.html');
url.href; // => 'http://example.com/path/index.html'
或者我们可以使用相对路径和绝对路径:
const url = new URL('/path/index.html', 'http://example.com');
url.href; // => 'http://example.com/path/index.html'
URL() 实例中的 href 属性返回了完整的 URL 字符串。
在新建了 URL() 的实例以后,你可以用它来访问前文图片中的任意 URL 组成部分。作为参考,下面是 URL() 实例的接口列表:
interface URL {
href: USVString;
protocol: USVString;
username: USVString;
password: USVString;
host: USVString;
hostname: USVString;
port: USVString;
pathname: USVString;
search: USVString;
hash: USVString;
readonly origin: USVString;
readonly searchParams: URLSearchParams;
toJSON(): USVString;
}
上述的 USVString 参数在 JavaScript 中会映射成字符串。
3. Query 字符串
url.search 可以获取到 URL 当中 ? 后面的 query 字符串:
const url = new URL(
'http://example.com/path/index.html?message=hello&who=world'
);
url.search; // => '?message=hello&who=world'
如果 query 参数不存在,url.search 默认会返回一个空字符串 '':
const url1 = new URL('http://example.com/path/index.html');
const url2 = new URL('http://example.com/path/index.html?');
url1.search; // => ''
url2.search; // => ''
3.1 解析 query 字符串
相比于获得原生的 query 字符串,更实用的场景是获取到具体的 query 参数。
获取具体 query 参数的一个简单的方法是利用 url.searchParams 属性。这个属性是 URLSearchParams 的实例。
URLSearchParams 对象提供了许多用于获取 query 参数的方法,如get(param),has(param)等。
下面来看个例子:
const url = new URL(
'http://example.com/path/index.html?message=hello&who=world'
);
url.searchParams.get('message'); // => 'hello'
url.searchParams.get('missing'); // => null
url.searchParams.get('message') 返回了 message 这个 query 参数的值——hello。
如果使用 url.searchParams.get('missing') 来获取一个不存在的参数,则得到一个 null。
4. hostname
url.hostname 属性返回一段 URL 的 hostname 部分:
const url = new URL('http://example.com/path/index.html');
url.hostname; // => 'example.com'
5. pathname
url. pathname 属性返回一段 URL 的 pathname 部分:
const url = new URL('http://example.com/path/index.html?param=value');
url.pathname; // => '/path/index.html'
如果这段 URL 不含 path,则该属性返回一个斜杠 /:
const url = new URL('http://example.com/');
url.pathname; // => '/'
6. hash
最后,我们可以通过 url.hash 属性来获取 URL 中的 hash 值:
const url = new URL('http://example.com/path/index.html#bottom');
url.hash; // => '#bottom'
当 URL 中的 hash 不存在时,url.hash 属性会返回一个空字符串 '':
const url = new URL('http://example.com/path/index.html');
url.hash; // => ''
7. URL 校验
当使用 new URL() 构造函数来新建实例的时候,作为一种副作用,它同时也会对 URL 进行校验。如果 URL 不合法,则会抛出一个 TypeError。
举个例子,http ://example.com 是一段非法 URL,因为它在 http 后面多写了一个空格。
让我们用这个非法 URL 来初始化 URL() 构造函数:
try {
const url = new URL('http ://example.com');
} catch (error) {
error; // => TypeError, "Failed to construct URL: Invalid URL"
}
因为 http ://example.com 是一段非法 URL,跟我们想的一样,new URL() 抛出了一个 TypeError。
8. 修改 URL
除了获取 URL 的组成部分以外,像 search,hostname,pathname 和 hash 这些属性都是可写的——这也意味着你可以修改 URL。
举个例子,让我们把一段 URL 从 red.com 修改成 blue.io:
const url = new URL('http://red.com/path/index.html');
url.href; // => 'http://red.com/path/index.html'
url.hostname = 'blue.io';
url.href; // => 'http://blue.io/path/index.html'
注意,在 URL() 实例中只有 origin 和 searchParams 属性是只读的,其他所有的属性都是可写的,并且会修改原来的 URL。
9. 总结
URL() 构造函数是 JavaScript 中的一个能够很方便地用于解析(或者校验)URL 的工具。
new URL(relativeOrAbsolute [, absoluteBase]) 中的第一个参数接收 URL 的绝对路径或者相对路径。当第一个参数是相对路径时,第二个参数必传且必须为第一个参数的基路径。
在新建 URL() 的实例以后,你就能很轻易地获得 URL 当中的大部分组成部分了,比如:
url.search 获取原生的 query 字符串
url.searchParams 通过 URLSearchParams 的实例去获取具体的 query 参数
url.hostname获取 hostname
url.pathname 获取 pathname
url.hash 获取 hash 值
那么你最爱用的解析 URL 的 JavaScript 工具又是什么呢?
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
React是Facebook开发的一款JS库,那么Facebook为什么要建造React呢,主要为了解决什么问题,通过这个又是如何解决的?
从这几个问题出发我就在网上搜查了一下,有这样的解释。
Facebook认为MVC无法满足他们的扩展需求,由于他们非常巨大的代码库和庞大的组织,使得MVC很快变得非常复复杂,每当需要添加一项新的功能或特性时,系统的复杂度就成级数增长,致使代码变得脆弱和不可预测,结果导致他们的MVC正在土崩瓦解。认为MVC不适合大规模应用,当系统中有很多的模型和相应的视图时,其复杂度就会迅速扩大,非常难以理解和调试,特别是模型和视图间可能存在的双向数据流动。
解决这个问题需要“以某种方式组织代码,使其更加可预测”,这通过他们(Facebook)提出的Flux和React已经完成。
Flux是一个系统架构,用于推进应用中的数据单向流动。React是一个JavaScript框架,用于构建“可预期的”和“声明式的”Web用户界面,它已经使Facebook更快地开发Web应用
对于Flux,目前还没怎么研究,不怎么懂,这里就先把Flux的图放上来,有兴趣或者了解的可以再分享下,这里主要说下React。

那么React是解决什么问题的,在官网可以找到这样一句话:
We built React to solve one problem: building large applications with data that changes over time.
构建那些数据会随时间改变的大型应用,做这些,React有两个主要的特点:
另外在React官网上,通过《Why did we build React?》为什么我们要建造React的文档中还可以了解到以下四点:
Virtual DOM 虚拟DOM
传统的web应用,操作DOM一般是直接更新操作的,但是我们知道DOM更新通常是比较昂贵的。而React为了尽可能减少对DOM的操作,提供了一种不同的而又强大的方式来更新DOM,代替直接的DOM操作。就是Virtual DOM,一个轻量级的虚拟的DOM,就是React抽象出来的一个对象,描述dom应该什么样子的,应该如何呈现。通过这个Virtual DOM去更新真实的DOM,由这个Virtual DOM管理真实DOM的更新。
为什么通过这多一层的Virtual DOM操作就能更快呢? 这是因为React有个diff算法,更新Virtual DOM并不保证马上影响真实的DOM,React会等到事件循环结束,然后利用这个diff算法,通过当前新的dom表述与之前的作比较,计算出最小的步骤更新真实的DOM。

component 的使用在 React 里极为重要, 因为 components 的存在让计算 DOM diff 更。
State 和 Render
React是如何呈现真实的DOM,如何渲染组件,什么时候渲染,怎么同步更新的,这就需要简单了解下State和Render了。state属性包含定义组件所需要的一些数据,当数据发生变化时,将会调用Render重现渲染,这里只能通过提供的setState方法更新数据。
好了,说了这么多,下面看写代码吧,先看一个官网上提供的Hello World的示例:
<!DOCTYPE html> <html> <head> <script src="http://fb.me/react-0.12.1.js"></script> <script src="http://fb.me/JSXTransformer-0.12.1.js"></script> </head> <body> <div id="example"></div> <script type="text/jsx"> React.render( <h1>Hello, world!</h1>,
document.getElementById('example')
); </script> </body> </html>
这个很简单,浏览器访问,可以看到Hello, world!字样。JSXTransformer.js是支持解析JSX语法的,JSX是可以在Javascript中写html代码的一种语法。如果不喜欢,React也提供原生Javascript的方法。
再来看下另外一个例子:
<html>
<head>
<title>Hello React</title>
<script src="http://fb.me/react-0.12.1.js"></script>
<script src="http://fb.me/JSXTransformer-0.12.1.js"></script>
<script src="http://code.jquery.com/jquery-1.10.0.min.js"></script>
<script src="http://cdnjs.cloudflare.com/ajax/libs/showdown/0.3.1/showdown.min.js"></script>
<style>
#content{
width: 800px;
margin: 0 auto;
padding: 5px 10px;
background-color:#eee;
}
.commentBox h1{
background-color: #bbb;
}
.commentList{
border: 1px solid yellow;
padding:10px;
}
.commentList .comment{
border: 1px solid #bbb;
padding-left: 10px;
margin-bottom:10px;
}
.commentList .commentAuthor{
font-size: 20px;
}
.commentForm{
margin-top: 20px;
border: 1px solid red;
padding:10px;
}
.commentForm textarea{
width:100%;
height:50px;
margin:10px 0 10px 2px;
}
</style>
</head>
<body>
<div id="content"></div>
<script type="text/jsx">
var staticData = [
{author: "张飞", text: "我在写一条评论~!"},
{author: "关羽", text: "2货,都知道你在写的是一条评论。。"},
{author: "刘备", text: "哎,咋跟这俩逗逼结拜了!"}
];
var converter = new Showdown.converter();//markdown
/** 组件结构:
<CommentBox>
<CommentList>
<Comment />
</CommentList>
<CommentForm />
</CommentBox>
*/
//评论内容组件
var Comment = React.createClass({
render: function (){
var rawMarkup = converter.makeHtml(this.props.children.toString());
return (
<div className="comment">
<h2 className="commentAuthor">
{this.props.author}:
</h2>
<span dangerouslySetInnerHTML={{__html: rawMarkup}} />
</div>
);
}
});
//评论列表组件
var CommentList = React.createClass({
render: function (){
var commentNodes = this.props.data.map(function (comment){
return (
<Comment author={comment.author}>
{comment.text}
</Comment>
);
});
return (
<div className="commentList">
{commentNodes}
</div>
);
}
});
//评论表单组件
var CommentForm = React.createClass({
handleSubmit: function (e){
e.preventDefault();
var author = this.refs.author.getDOMNode().value.trim();
var text = this.refs.text.getDOMNode().value.trim();
if(!author || !text){
return;
}
this.props.onCommentSubmit({author: author, text: text});
this.refs.author.getDOMNode().value = '';
this.refs.text.getDOMNode().value = '';
return;
},
render: function (){
return (
<form className="commentForm" onSubmit={this.handleSubmit}>
<input type="text" placeholder="Your name" ref="author" /><br/>
<textarea type="text" placeholder="Say something..." ref="text" ></textarea><br/>
<input type="submit" value="Post" />
</form>
);
}
});
//评论块组件
var CommentBox = React.createClass({
loadCommentsFromServer: function (){
this.setState({data: staticData});
/*
方便起见,这里就不走服务端了,可以自己尝试
$.ajax({
url: this.props.url + "?_t=" + new Date().valueOf(),
dataType: 'json',
success: function (data){
this.setState({data: data});
}.bind(this),
error: function (xhr, status, err){
console.error(this.props.url, status, err.toString());
}.bind(this)
});
*/
},
handleCommentSubmit: function (comment){
//TODO: submit to the server and refresh the list
var comments = this.state.data;
var newComments = comments.concat([comment]);
//这里也不向后端提交了
staticData = newComments;
this.setState({data: newComments});
},
//初始化 相当于构造函数
getInitialState: function (){
return {data: []};
},
//组件添加的时候运行
componentDidMount: function (){
this.loadCommentsFromServer();
this.interval = setInterval(this.loadCommentsFromServer, this.props.pollInterval);
},
//组件删除的时候运行
componentWillUnmount: function() {
clearInterval(this.interval);
},
//调用setState或者父级组件重新渲染不同的props时才会重新调用
render: function (){
return (
<div className="commentBox">
<h1>Comments</h1>
<CommentList data={this.state.data}/>
<CommentForm onCommentSubmit={this.handleCommentSubmit} />
</div>
);
}
});
//当前目录需要有comments.json文件
//这里定义属性,如url、pollInterval,包含在props属性中
React.render(
<CommentBox url="comments.json" pollInterval="2000" />,
document.getElementById("content")
);
</script>
</body>
</html>
乍一看挺多,主要看脚本部分就可以了。方便起见,这里都没有走后端。定义了一个全局的变量staticData,可权当是走服务端,通过浏览器的控制台改变staticData的值,查看下效果,提交一条评论,查看下staticData的值的变化。
国外应用的较多,facebook、Yahoo、Reddit等。在github可以看到一个列表Sites-Using-React,国内的话,查了查,貌似比较少,目前知道的有一个杭州大搜车。大多技术要在国内应用起来一般是较慢的,不过React确实感觉比较特殊,特别是UI的组件化和Virtual DOM的思想,我个人比较看好,有兴趣继续研究研究。
和其他一些js框架相比,React怎样,比如Backbone、Angular等。
数组——最简单的内存数据结构
数组存储一系列同一种数据类型的值。( Javascript 中不存在这种限制)
对数据的随机访问,数组是更好的选择,否则几乎可以完全用 「链表」 来代替
在很多编程语言中,数组的长度是固定的,当数组被填满时,再要加入新元素就很困难。Javascript 中数组不存在这个问题。
但是 Javascript 中的数组被实现成了对象,与其他语言相比,效率低下。
数组的一些核心方法
方法 描述
push 方法将一个或多个元素添加到数组的末尾,并返回该数组的新长度。(改变原数组)
pop 方法从数组中删除最后一个元素,并返回该元素的值。(改变原数组)
shift 方法从数组中删除第一个元素,并返回该元素的值,如果数组为空则返回 undefined 。(改变原数组)
unshift 将一个或多个元素添加到数组的开头,并返回该数组的新长度(改变原数组)
concat 连接两个或多个数组,并返回结果(返回一个新数组,不影响原有的数组。)
every 对数组中的每个元素运行给定函数,如果该函数对每个元素都返回 true,则返回 true。若为一个空数组,,始终返回 true。 (不会改变原数组,[].every(callback)始终返回 true)
some 对数组中的每个元素运行给定函数,如果任一元素返回 true,则返回 true。若为一个空数组,,始终返回 false。(不会改变原数组,)
forEach 对数组中的每个元素运行给定函数。这个方法没有返回值,没有办法中止或者跳出 forEach() 循环,除了抛出一个异常(foreach不直接改变原数组,但原数组可能会被 callback 函数该改变。)
map 对数组中的每个元素运行给定函数,返回每次函数调用的结果组成的数组(map不直接改变原数组,但原数组可能会被 callback 函数该改变。)
sort 按照Unicode位点对数组排序,支持传入指定排序方法的函数作为参数(改变原数组)
reverse 方法将数组中元素的位置颠倒,并返回该数组(改变原数组)
join 将所有的数组元素连接成一个字符串
indexOf 返回第一个与给定参数相等的数组元素的索引,没有找到则返回 -1
lastIndexOf 返回在数组中搜索到的与给定参数相等的元素的索引里最大的值,没有找到则返回 -1
slice 传入索引值,将数组里对应索引范围内的元素(浅复制原数组中的元素)作为新数组返回(原始数组不会被改变)
splice 删除或替换现有元素或者原地添加新的元素来修改数组,并以数组形式返回被修改的内容(改变原数组)
toString 将数组作为字符串返回
valueOf 和 toString 类似,将数组作为字符串返回
栈是一种遵循后进先出(LIFO)原则的有序集合,新添加或待删除的元素都保存在栈的同一端,称作栈顶,另一端就叫栈底。在栈里,新元素都靠近栈顶,旧元素都接近栈底。
通俗来讲,就是你向一个桶里放书本或者盘子,你要想取出最下面的书或者盘子,你必须要先把上面的都先取出来。
栈也被用在编程语言的编译器和内存中保存变量、方法调用等,也被用于浏览器历史记录 (浏览器的返回按钮)。
代码实现
// 封装栈队列是遵循先进先出(FIFO,也称为先来先服务)原则的一组有序的项。队列在尾部添加新
元素,并从顶部移除元素。添加的元素必须排在队列的末尾。
生活中常见的就是排队
代码实现
function Queue() {代码实现
链表——存储有序的元素集合,但在内存中不是连续放置的。
链表(单向链表)中的元素由存放元素本身「data」 的节点和一个指向下一个「next」 元素的指针组成。牢记这个特点
相比数组,链表添加或者移除元素不需要移动其他元素,但是需要使用指针。访问元素每次都需要从表头开始查找。
代码实现:
单向链表
表头、表尾 和 存储数据的 节点,其中节点包含三部分:一个链向下一个元素的next, 另一个链向前一个元素的prev 和存储数据的 data。牢记这个特点
function doublyLinkedList() {
this.head = null // 表头:始终指向第一个节点,默认为 null
this.tail = null // 表尾:始终指向最后一个节点,默认为 null
this.length = 0 // 链表长度
function Node(data) {
this.data = data
this.prev = null
this.next = null
}
doublyLinkedList.prototype.append = function (data) {
let newNode = new Node(data)
if (this.length === 0) {
// 当插入的节点为链表的第一个节点时
// 表头和表尾都指向这个节点
this.head = newNode
this.tail = newNode
} else {
// 当链表中已经有节点存在时
// 注意tail指向的始终是最后一个节点
// 注意head指向的始终是第一个节点
// 因为是双向链表,可以从头部插入新节点,也可以从尾部插入
// 这里以从尾部插入为例,将新节点插入到链表最后
// 首先将新节点的 prev 指向上一个节点,即之前tail指向的位置
newNode.prev = this.tail
// 然后前一个节点的next(及之前tail指向的节点)指向新的节点
// 此时新的节点变成了链表的最后一个节点
this.tail.next = newNode
// 因为 tail 始终指向的是最后一个节点,所以最后修改tail的指向
this.tail = newNode
}
this.length++
}
doublyLinkedList.prototype.toString = function () {
return this.backwardString()
}
doublyLinkedList.prototype.forwardString = function () {
let current = this.tail
let str = ''
while (current) {
str += current.data + ''
current = current.prev
}
return str
}
doublyLinkedList.prototype.backwardString = function () {
let current = this.head
let str = ''
while (current) {
str += current.data + ''
current = current.next
}
return str
}
doublyLinkedList.prototype.insert = function (position, data) {
if (position < 0 || position > this.length) return false
let newNode = new Node(data)
if (this.length === 0) {
this.head = newNode
this.tail = newNode
} else {
if (position == 0) {
this.head.prev = newNode
newNode.next = this.head
this.head = newNode
} else if (position == this.length) {
newNode.prev = this.tail
this.tail.next = newNode
this.tail = newNode
} else {
let current = this.head
let index = 0
while( index++ < position){
current = current.next
}
newNode.next = current
newNode.prev = current.prev
current.prev.next = newNode
current.prev = newNode
}
}
this.length++
return true
}
doublyLinkedList.prototype.get = function (position) {
if (position < 0 || position >= this.length) return null
let current = this.head
let index = 0
while (index++) {
current = current.next
}
return current.data
}
doublyLinkedList.prototype.indexOf = function (data) {
let current = this.head
let index = 0
while (current) {
if (current.data === data) {
return index
}
current = current.next
index++
}
return -1
}
doublyLinkedList.prototype.update = function (position, newData) {
if (position < 0 || position >= this.length) return false
let current = this.head
let index = 0
while(index++ < position){
current = current.next
}
current.data = newData
return true
}
doublyLinkedList.prototype.removeAt = function (position) {
if (position < 0 || position >= this.length) return null
let current = this.head
if (this.length === 1) {
this.head = null
this.tail = null
} else {
if (position === 0) { // 删除第一个节点
this.head.next.prev = null
this.head = this.head.next
} else if (position === this.length - 1) { // 删除最后一个节点
this.tail.prev.next = null
this.tail = this.tail.prev
} else {
let index = 0
while (index++ < position) {
current = current.next
}
current.prev.next = current.next
current.next.prev = current.prev
}
}
this.length--
return current.data
}
doublyLinkedList.prototype.remove = function (data) {
let index = this.indexOf(data)
return this.removeAt(index)
}
}
感谢你的阅读~
————————————————
版权声明:本文为CSDN博主「重庆崽儿Brand」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/brand2014/java/article/details/106134844
蓝蓝设计的小编 http://www.lanlanwork.com