iOS作为UI/UE设计的风向标,一直是行业的引领者,不管你愿不愿意承不承认,他的每一次更新变化总能带动UI设计行业的一些大大小小的变革,并且产生更多的追随者,比如当年的iOS7开始的扁平化设计风格,对后续设计风格的影响直到现在已经7年了。

在最近半年,iOS在UI设计风格上最大的变革莫过于DarkMode(深色模式),在DarkMode之前,我们熟悉的UI界面往往都是浅白色界面为主,而从iOS13开始正式使用了DarkMode,界面突然可以变深色了,苹果官方说这样设计可以让眼睛更舒服的长时间阅读,为革命保护视力,而且更加省电增长续航,具体结果我们不得而知,需要科学家们去验证了,但是对于我们设计师来说带来的挑战就是要“黑白无常”了。

其实DarkMode从测试版算起已经差不多推出了有半年的时间了,一些知名的APP产品早已经有了自己的兼容方案,同时iOS原生界面也给了我们很多最佳实践案例,按道理大家对于DarkMode的设计方式方法应该已经掌握了差不多了,但直到这几天微信正式推出了自己的DarkMode兼容方案,才发现对DarkMode的探索还需要设计师们多多努力。谨以此文表达一下自己的观点,不妥之处敬请海涵。
从一个“列表页面”说起:
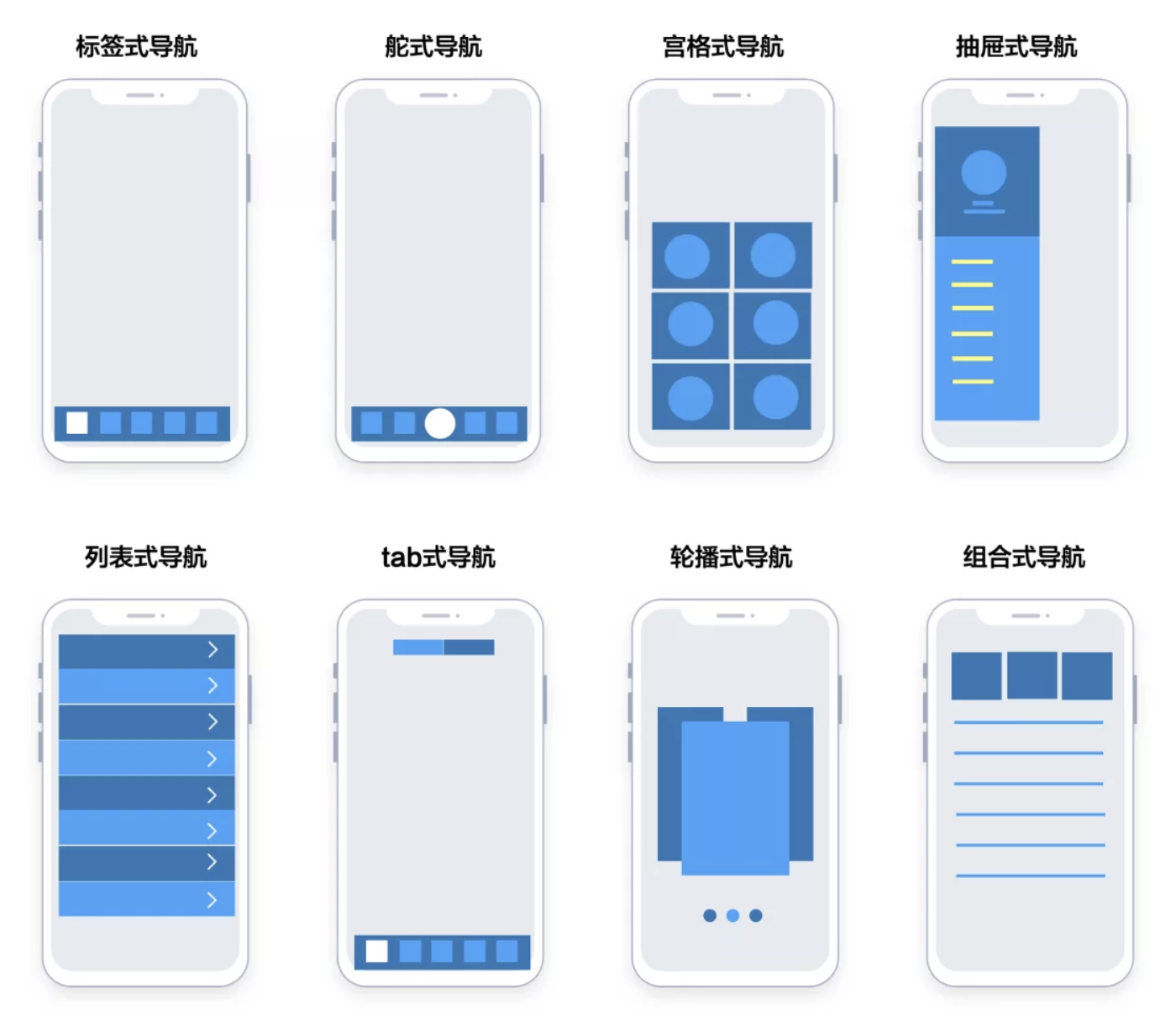
列表试图(TableView)是iOS中最常见的界面组件,一般常见于设置与栏目列表页面

iOS设置界面的浅色模式和深色模式看起来都非常协调。
下面我们看看微信发现页面,这个页面和iOS设置是很相似的。
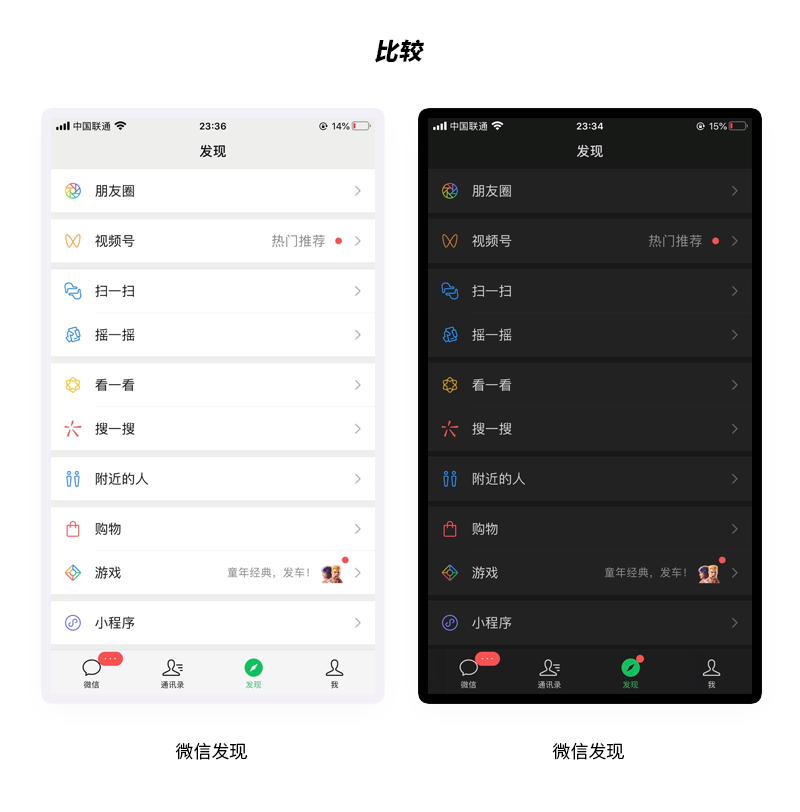
如果单独看微信发现页面的浅色模式实际效果还是不错的。
但是直接转换到深色模式下就感觉突然差的很多了,甚至可以说是有点难看,这次微信真的做了一次黑天鹅?
到底是什么原因让微信发现页面在深色模式下视觉体验如此之差呢?
我们不妨将两个功能布局都相似的深色进行放在一起进行一下比较

组成色彩分析:

在色彩这块在这两个页面中微信和iOS基本保持一致,四层灰度设计能更好的保持页面整体干净整洁且层次分明,但是被A背景色上,微信的背景色选择了黑色偏绿的颜色,应该是微信设计师还是想体现出产品的标志色原色。
文字的颜色也较iOS略微深一点,但是在整体上影响并不大。

看来在主要色彩上并没有什么问题,那么为什么微信这个界面与iOS界面比起来视觉上要感觉差一些呢?
下面来看一下图标
图标设计分析:

图标上的差别主要在于线宽与外框,微信采用无外框统一线宽的线形图标,iOS采用的是有外框剪影图标。
我们我们把图标进行互换会怎么样呢?
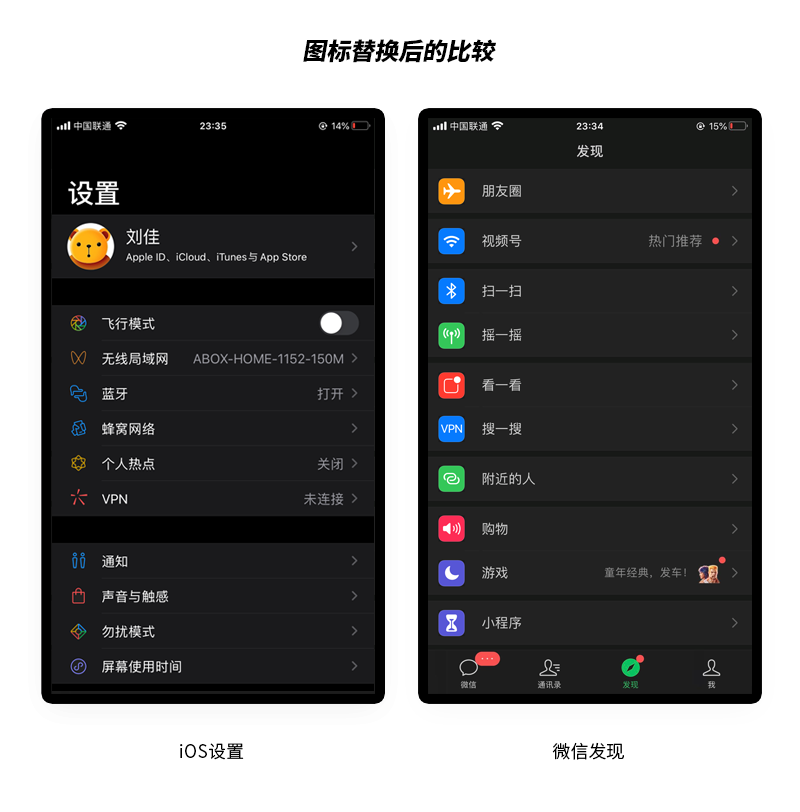
观察到了吗?别看错了!
是的,我把故意位置做了对调,左边是iOS,右边是微信。替换图标后的微信明显加分不少,整个界面都整齐多了,而iOS换了图标后明显变得不够整齐了,潦草很多。
那么结论是微信的无框线性图标在深色模式下兼容有问题?是的的确如此。但是等一下,还有一些细节你注意到吗?换了图标的微信界面和之前的iOS界面比起来明显还是有点不够整齐,为什么呢?
来我们回过头来从细节再看一下iOS界面。

我们按照这个思路把刚才微信替换图标界面再排序一下!
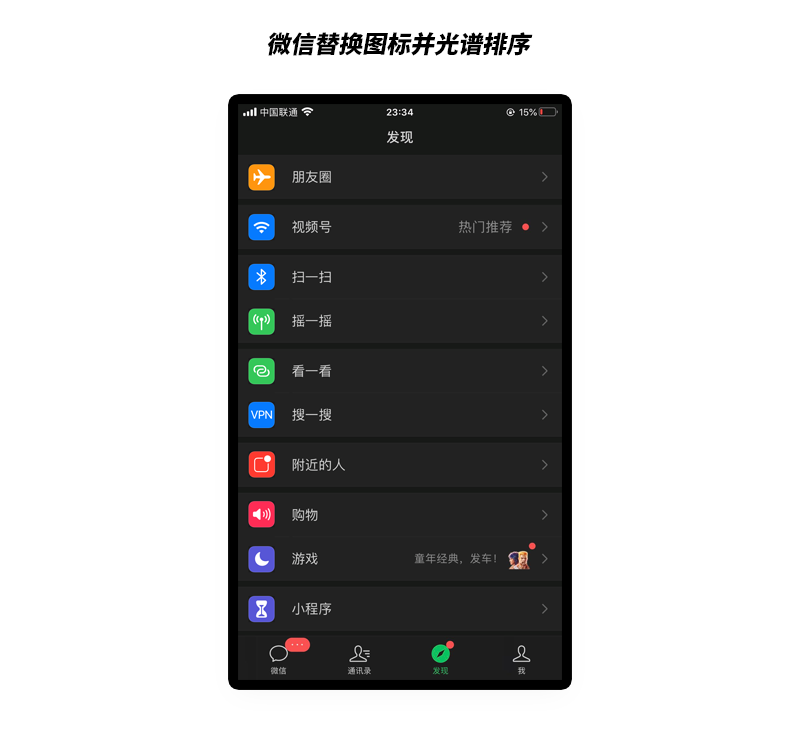
界面视觉体验明显整齐了很多是不是!
疑问:
为什么细线图标和无框图标会在深色背景表现不够好,而在浅色背景下就没问题呢?
是不是所有的UI都会存在这样的问题呢?
我们再来看一些例子:
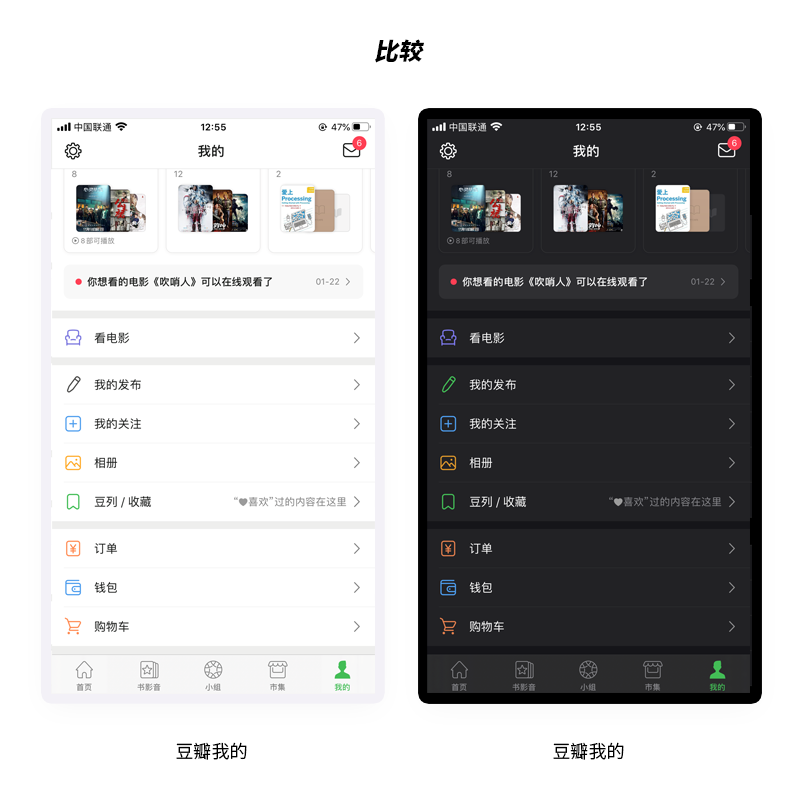

看来结论是一样的,线性图标在深色背景下的表现都是差强人意,反观带框图标适应性很强,浅色和深色模式下均能良好的适配,我来分析一下原因。
当年伽利略用望远镜往天上看,发现木星比金星大,换成肉眼看后金星则比木星大。他认为是眼睛的某种视觉特性造成了这种现象。
德国物理学家赫尔曼把这种错觉称为辐照错觉,就是说在黑暗背景下,亮度越高的物体看起来面积越大。
再来看一张图片

哪个圆圈看起来更大,显然是黑色背景下的白色圆形,实际上这只是一种错觉,所有圆圈是一样大。
光亮刺激会使得神经元产生非线性放大作用,导致刺激比实物本身看起来更大,白色圆形更亮,所以看起来更大一些。
线性图标是用线条勾画图案达到隐喻效果,一般线粗是2px~6px像素。

设计师在设计时候都是以最终视觉作为参考,而设计稿本身多是浅色背景,所以在浅色背景的映衬下图标视觉会显得稍大,视觉基本是平衡的,假如设计是4px而呈现出的效果其实是6px左右。
是不是觉得哪里有点不对了?按照这个逻辑黑色背景下白色线图标不应该是视觉更大、更明显吗?
我们还需要考虑一个因素,那就是色彩,之前的几个界面案例的线性图标都是彩色的,特别是黑色背景下,不同色彩的图标放在一起,会有明显的忽大忽小的感觉,会让界面感觉非常凌乱。

是不是感觉黄色最大,红色的最小?但是其实是一样的,这还是相同形状的,要是图标形状不同感受会更明显
看一个实际中的例子:

由于都是单色线性图标,在浅色和深色下表现还都不错的,但是单色图标略显界面单调,并不太建议这么设计。

毫无疑问,未来的UI场景需要适配多背景色风格,图标除了具备好看隐喻之外,更需要具备抗干扰性
带框图标是一个不错的解决方法,大胆预测带框图标会将成为未来一段时间图标设计主流!
结论
1:深色模式中灰度色阶在一个界面最多可分为四层。
2:为了适配深色模式,今后有框图标将会成为图标设计风格主流。
3:同样为了适配深色模式,细线图标将会被淘汰,剪影和粗线图标会流行起来。
4:图标除了个体设计上用心,在排列上也会极大影响到页面的整合视觉,光谱排列法是个不错的选择。